 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing the Expected Posterior Entropy Yields Optimal Summary Statistics
Jun 06, 2022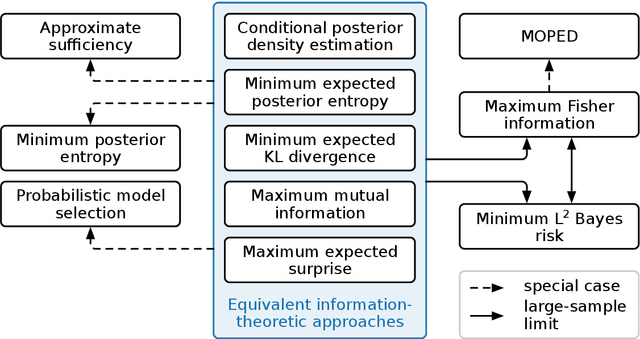
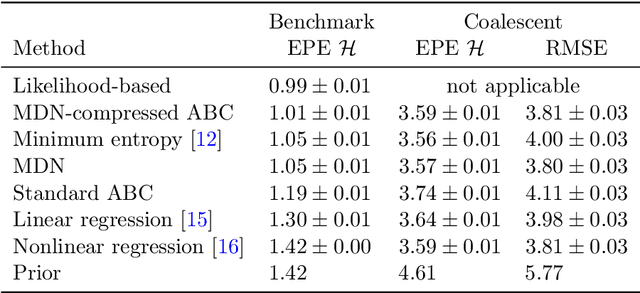
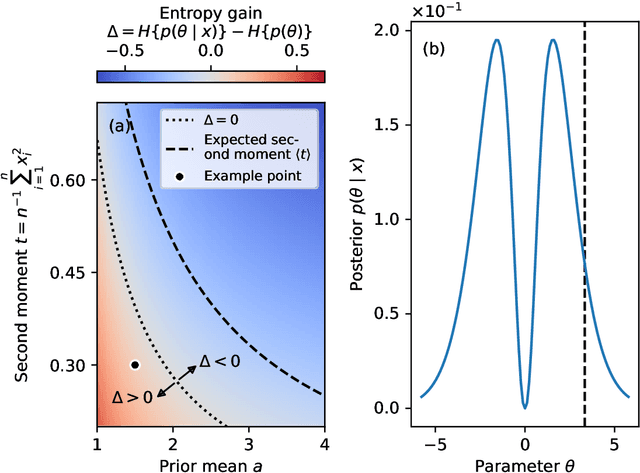

Extracting low-dimensional summary statistics from large datasets is essential for efficient (likelihood-free) inference. We propose obtaining summary statistics by minimizing the expected posterior entropy (EPE) under the prior predictive distribution of the model. We show that minimizing the EPE is equivalent to learning a conditional density estimator for the posterior as well as other information-theoretic approaches. Further summary extraction methods (including minimizing the $L^2$ Bayes risk, maximizing the Fisher information, and model selection approaches) are special or limiting cases of EPE minimization. We demonstrate that the approach yields high fidelity summary statistics by applying it to both a synthetic benchmark as well as a population genetics problem. We not only offer concrete recommendations for practitioners but also provide a unifying perspective for obtaining informative summary statistics.
Thematic recommendations on knowledge graphs using multilayer networks
May 12, 2021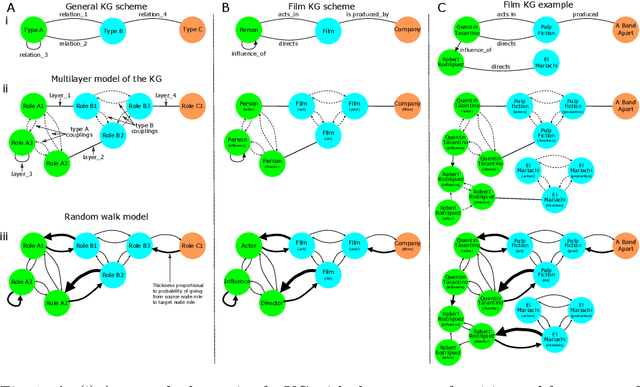
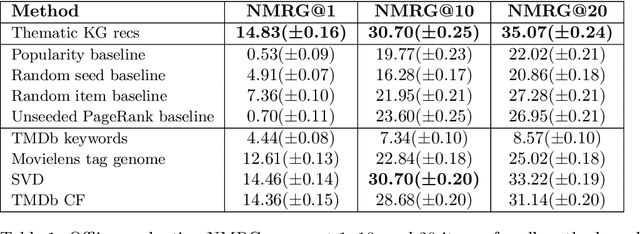
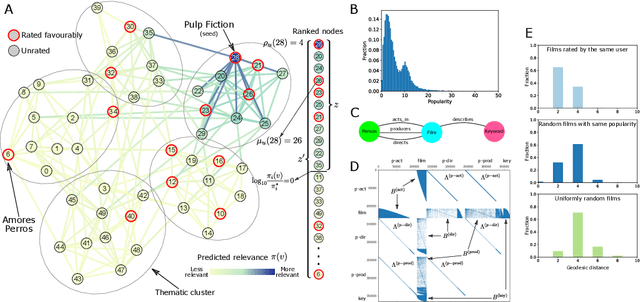

We present a framework to generate and evaluate thematic recommendations based on multilayer network representations of knowledge graphs (KGs). In this representation, each layer encodes a different type of relationship in the KG, and directed interlayer couplings connect the same entity in different roles. The relative importance of different types of connections is captured by an intuitive salience matrix that can be estimated from data, tuned to incorporate domain knowledge, address different use cases, or respect business logic. We apply an adaptation of the personalised PageRank algorithm to multilayer models of KGs to generate item-item recommendations. These recommendations reflect the knowledge we hold about the content and are suitable for thematic and/or cold-start recommendation settings. Evaluating thematic recommendations from user data presents unique challenges that we address by developing a method to evaluate recommendations relying on user-item ratings, yet respecting their thematic nature. We also show that the salience matrix can be estimated from user data. We demonstrate the utility of our methods by significantly improving consumption metrics in an AB test where collaborative filtering delivered subpar performance. We also apply our approach to movie recommendation using publicly-available data to ensure the reproducibility of our results. We demonstrate that our approach outperforms existing thematic recommendation methods and is even competitive with collaborative filtering approaches.
Community detection in networks with unobserved edges
Aug 18, 2018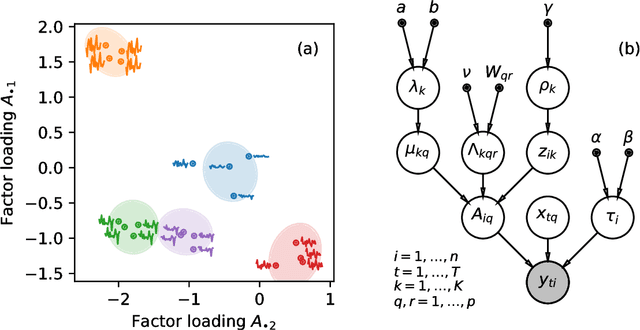
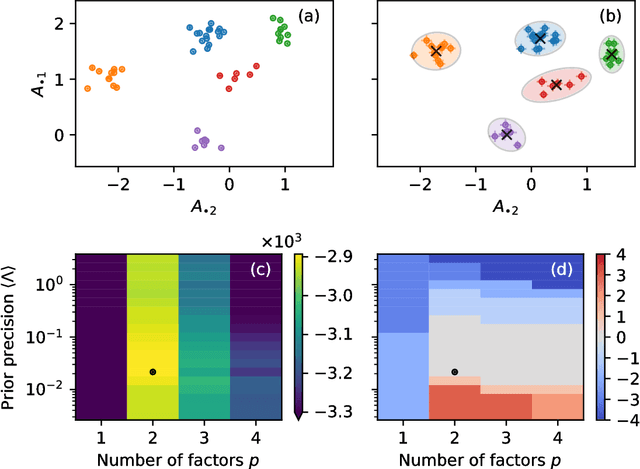
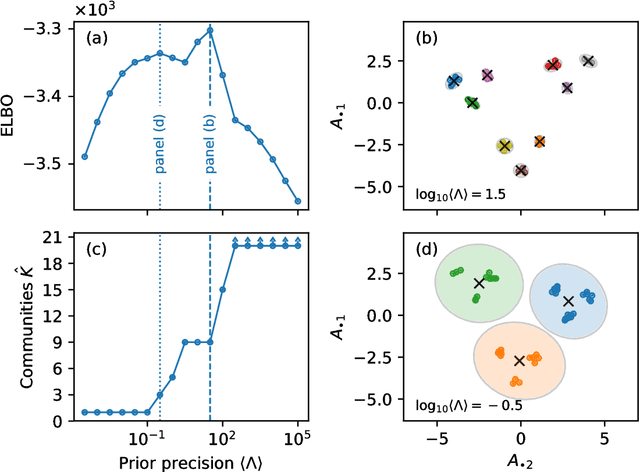
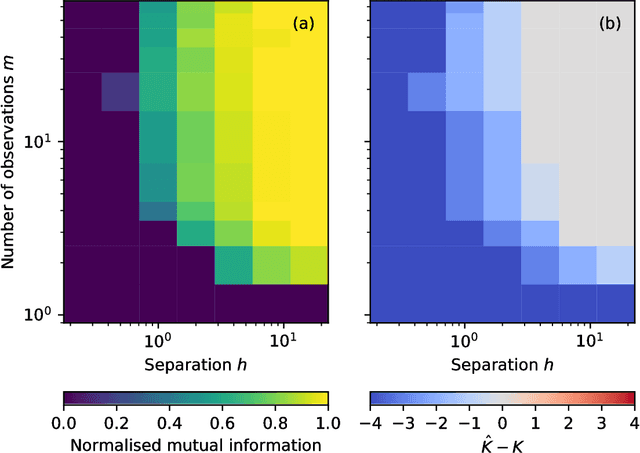
We develop a Bayesian hierarchical model to identify communities in networks for which we do not observe the edges directly, but instead observe a series of interdependent signals for each of the nodes. Fitting the model provides an end-to-end community detection algorithm that does not extract information as a sequence of point estimates but propagates uncertainties from the raw data to the community labels. Our approach naturally supports multiscale community detection as well as the selection of an optimal scale using model comparison. We study the properties of the algorithm using synthetic data and apply it to daily returns of constituents of the S&P100 index as well as climate data from US cities.