 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViSMaP: Unsupervised Hour-long Video Summarisation by Meta-Prompting
Apr 22, 2025We introduce ViSMap: Unsupervised Video Summarisation by Meta Prompting, a system to summarise hour long videos with no-supervision. Most existing video understanding models work well on short videos of pre-segmented events, yet they struggle to summarise longer videos where relevant events are sparsely distributed and not pre-segmented. Moreover, long-form video understanding often relies on supervised hierarchical training that needs extensive annotations which are costly, slow and prone to inconsistency. With ViSMaP we bridge the gap between short videos (where annotated data is plentiful) and long ones (where it's not). We rely on LLMs to create optimised pseudo-summaries of long videos using segment descriptions from short ones. These pseudo-summaries are used as training data for a model that generates long-form video summaries, bypassing the need for expensive annotations of long videos. Specifically, we adopt a meta-prompting strategy to iteratively generate and refine creating pseudo-summaries of long videos. The strategy leverages short clip descriptions obtained from a supervised short video model to guide the summary. Each iteration uses three LLMs working in sequence: one to generate the pseudo-summary from clip descriptions, another to evaluate it, and a third to optimise the prompt of the generator. This iteration is necessary because the quality of the pseudo-summaries is highly dependent on the generator prompt, and varies widely among videos. We evaluate our summaries extensively on multiple datasets; our results show that ViSMaP achieves performance comparable to fully supervised state-of-the-art models while generalising across domains without sacrificing performance. Code will be released upon publication.
Thematic recommendations on knowledge graphs using multilayer networks
May 12, 2021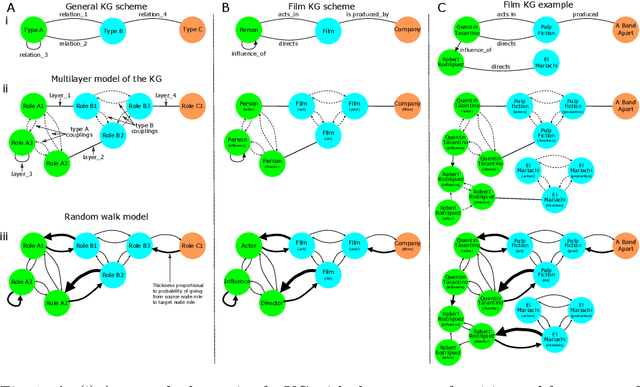
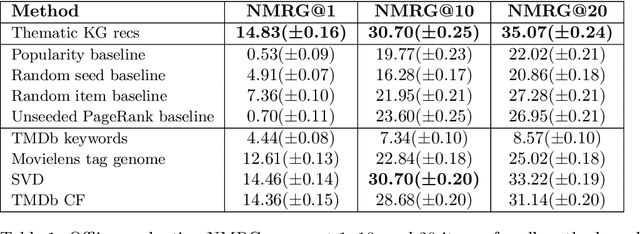
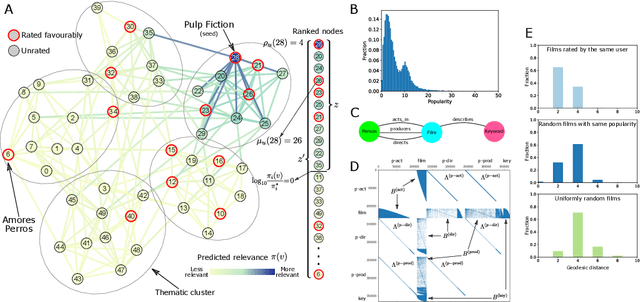

We present a framework to generate and evaluate thematic recommendations based on multilayer network representations of knowledge graphs (KGs). In this representation, each layer encodes a different type of relationship in the KG, and directed interlayer couplings connect the same entity in different roles. The relative importance of different types of connections is captured by an intuitive salience matrix that can be estimated from data, tuned to incorporate domain knowledge, address different use cases, or respect business logic. We apply an adaptation of the personalised PageRank algorithm to multilayer models of KGs to generate item-item recommendations. These recommendations reflect the knowledge we hold about the content and are suitable for thematic and/or cold-start recommendation settings. Evaluating thematic recommendations from user data presents unique challenges that we address by developing a method to evaluate recommendations relying on user-item ratings, yet respecting their thematic nature. We also show that the salience matrix can be estimated from user data. We demonstrate the utility of our methods by significantly improving consumption metrics in an AB test where collaborative filtering delivered subpar performance. We also apply our approach to movie recommendation using publicly-available data to ensure the reproducibility of our results. We demonstrate that our approach outperforms existing thematic recommendation methods and is even competitive with collaborative filtering approaches.
High-Resolution Mammogram Synthesis using Progressive Generative Adversarial Networks
Jul 09, 2018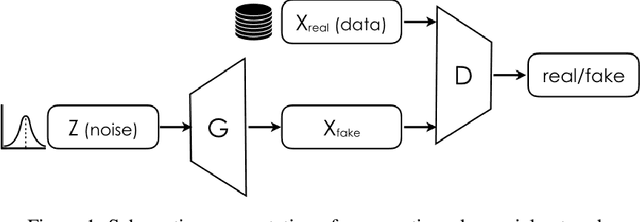
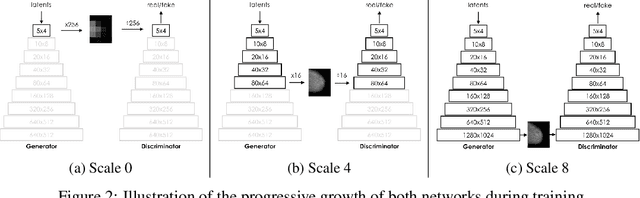
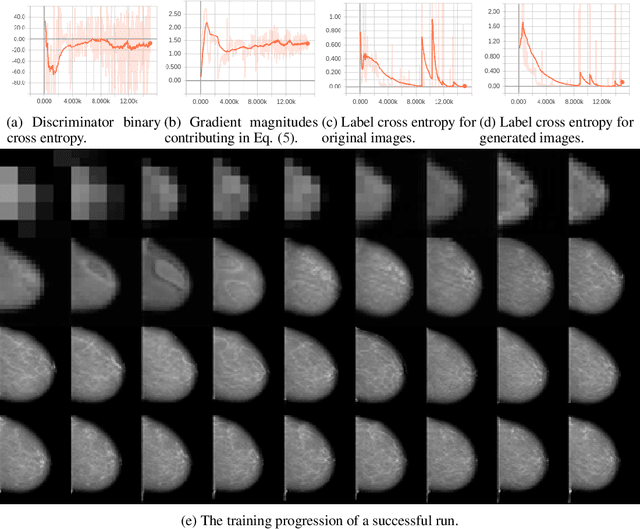
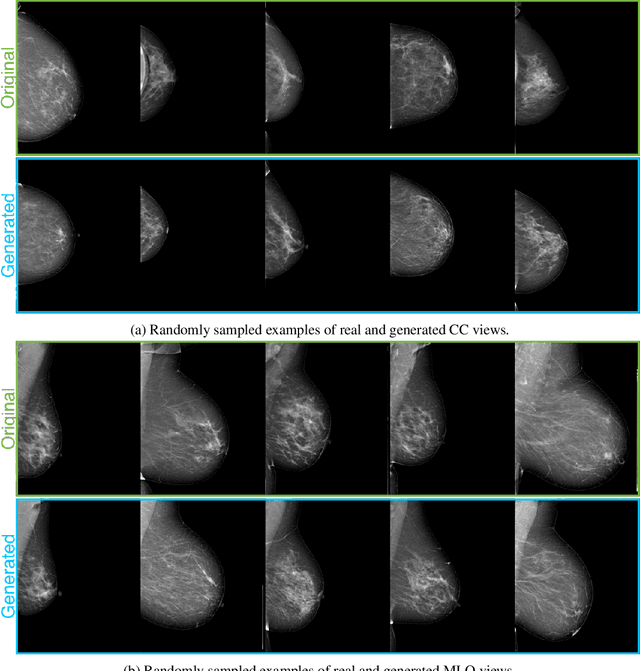
The ability to generate synthetic medical images is useful for data augmentation, domain transfer, and out-of-distribution detection. However, generating realistic, high-resolution medical images is challenging, particularly for Full Field Digital Mammograms (FFDM), due to the textural heterogeneity, fine structural details and specific tissue properties. In this paper, we explore the use of progressively trained generative adversarial networks (GANs) to synthesize mammograms, overcoming the underlying instabilities when training such adversarial models. This work is the first to show that generation of realistic synthetic medical images is feasible at up to 1280x1024 pixels, the highest resolution achieved for medical image synthesis, enabling visualizations within standard mammographic hanging protocols. We hope this work can serve as a useful guide and facilitate further research on GANs in the medical imaging domain.
The Kernel Pitman-Yor Process
Oct 15, 2012In this work, we propose the kernel Pitman-Yor process (KPYP) for nonparametric clustering of data with general spatial or temporal interdependencies. The KPYP is constructed by first introducing an infinite sequence of random locations. Then, based on the stick-breaking construction of the Pitman-Yor process, we define a predictor-dependent random probability measure by considering that the discount hyperparameters of the Beta-distributed random weights (stick variables) of the process are not uniform among the weights, but controlled by a kernel function expressing the proximity between the location assigned to each weight and the given predictors.