 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Conversational TTS with Cascaded Prompting and ICL-Based Online Reinforcement Learning
Apr 09, 2026Conversational AI has made significant progress, yet generating expressive and controllable text-to-speech (TTS) remains challenging. Specifically, controlling fine-grained voice styles and emotions is notoriously difficult and typically requires massive amounts of heavily annotated training data. To overcome this data bottleneck, we present a scalable, data-efficient cascaded framework that pairs textual style tokens with human-curated, high-quality audio prompts. This approach enables single-shot adaptation to fine-grained speaking styles and character voices. In the context of TTS, this audio prompting acts as In-Context Learning (ICL), guiding the model's prosody and timbre without requiring massive parameter updates or large-scale retraining. To further enhance generation quality and mitigate hallucinations, we introduce a novel ICL-based online reinforcement learning (RL) strategy. This strategy directly optimizes the autoregressive prosody model using subjective aesthetic rewards while being constrained by Connectionist Temporal Classification (CTC) alignment to preserve intelligibility. Comprehensive human perception evaluations demonstrate significant improvements in both the naturalness and expressivity of the synthesized speech, establishing the efficacy of our ICL-based online RL approach.
Aligning Paralinguistic Understanding and Generation in Speech LLMs via Multi-Task Reinforcement Learning
Mar 16, 2026Speech large language models (LLMs) observe paralinguistic cues such as prosody, emotion, and non-verbal sounds--crucial for intent understanding. However, leveraging these cues faces challenges: limited training data, annotation difficulty, and models exploiting lexical shortcuts over paralinguistic signals. We propose multi-task reinforcement learning (RL) with chain-of-thought prompting that elicits explicit affective reasoning. To address data scarcity, we introduce a paralinguistics-aware speech LLM (PALLM) that jointly optimizes sentiment classification from audio and paralinguistics-aware response generation via a two-stage pipeline. Experiments demonstrate that our approach improves paralinguistics understanding over both supervised baselines and strong proprietary models (Gemini-2.5-Pro, GPT-4o-audio) by 8-12% on Expresso, IEMOCAP, and RAVDESS. The results show that modeling paralinguistic reasoning with multi-task RL is crucial for building emotionally intelligent speech LLMs.
Describe Where You Are: Improving Noise-Robustness for Speech Emotion Recognition with Text Description of the Environment
Jul 25, 2024


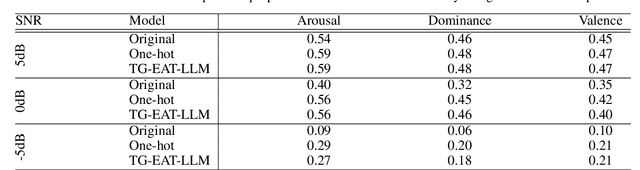
Speech emotion recognition (SER) systems often struggle in real-world environments, where ambient noise severely degrades their performance. This paper explores a novel approach that exploits prior knowledge of testing environments to maximize SER performance under noisy conditions. To address this task, we propose a text-guided, environment-aware training where an SER model is trained with contaminated speech samples and their paired noise description. We use a pre-trained text encoder to extract the text-based environment embedding and then fuse it to a transformer-based SER model during training and inference. We demonstrate the effectiveness of our approach through our experiment with the MSP-Podcast corpus and real-world additive noise samples collected from the Freesound repository. Our experiment indicates that the text-based environment descriptions processed by a large language model (LLM) produce representations that improve the noise-robustness of the SER system. In addition, our proposed approach with an LLM yields better performance than our environment-agnostic baselines, especially in low signal-to-noise ratio (SNR) conditions. When testing at -5dB SNR level, our proposed method shows better performance than our best baseline model by 31.8 % (arousal), 23.5% (dominance), and 9.5% (valence).
Versatile Audio-Visual Learning for Handling Single and Multi Modalities in Emotion Regression and Classification Tasks
May 12, 2023



Most current audio-visual emotion recognition models lack the flexibility needed for deployment in practical applications. We envision a multimodal system that works even when only one modality is available and can be implemented interchangeably for either predicting emotional attributes or recognizing categorical emotions. Achieving such flexibility in a multimodal emotion recognition system is difficult due to the inherent challenges in accurately interpreting and integrating varied data sources. It is also a challenge to robustly handle missing or partial information while allowing direct switch between regression and classification tasks. This study proposes a \emph{versatile audio-visual learning} (VAVL) framework for handling unimodal and multimodal systems for emotion regression and emotion classification tasks. We implement an audio-visual framework that can be trained even when audio and visual paired data is not available for part of the training set (i.e., audio only or only video is present). We achieve this effective representation learning with audio-visual shared layers, residual connections over shared layers, and a unimodal reconstruction task. Our experimental results reveal that our architecture significantly outperforms strong baselines on both the CREMA-D and MSP-IMPROV corpora. Notably, VAVL attains a new state-of-the-art performance in the emotional attribute prediction task on the MSP-IMPROV corpus. Code available at: https://github.com/ilucasgoncalves/VAVL