 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho is Speaking or Who is Depressed? A Controlled Study of Speaker Leakage in Speech-Based Depression Detection
Apr 15, 2026This study investigates whether speech-based depression detection models learn depression-related acoustic biomarkers or instead rely on speaker identity cues. Using the DAIC-WOZ dataset, we propose a data-splitting strategy that controls speaker overlap between training and test sets while keeping the training size constant, and evaluate three models of varying complexity. Results show that speaker overlap significantly boosts performance, whereas accuracy drops sharply on unseen speakers. Even with a Domain-Adversarial Neural Network, a substantial performance gap remains. These findings indicate that depression-related features extracted by current speech models are highly entangled with speaker identity. Conventional evaluation protocols may therefore overestimate generalization and clinical utility, highlighting the need for strictly speaker-independent evaluation.
EmotionRankCLAP: Bridging Natural Language Speaking Styles and Ordinal Speech Emotion via Rank-N-Contrast
May 29, 2025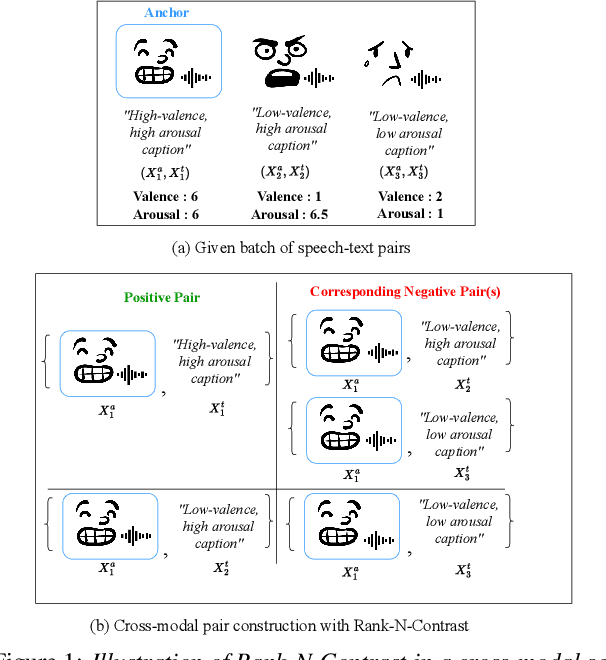


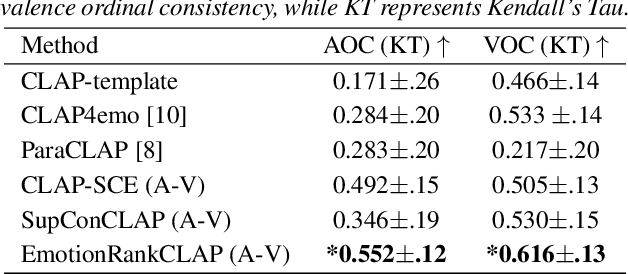
Current emotion-based contrastive language-audio pretraining (CLAP) methods typically learn by na\"ively aligning audio samples with corresponding text prompts. Consequently, this approach fails to capture the ordinal nature of emotions, hindering inter-emotion understanding and often resulting in a wide modality gap between the audio and text embeddings due to insufficient alignment. To handle these drawbacks, we introduce EmotionRankCLAP, a supervised contrastive learning approach that uses dimensional attributes of emotional speech and natural language prompts to jointly capture fine-grained emotion variations and improve cross-modal alignment. Our approach utilizes a Rank-N-Contrast objective to learn ordered relationships by contrasting samples based on their rankings in the valence-arousal space. EmotionRankCLAP outperforms existing emotion-CLAP methods in modeling emotion ordinality across modalities, measured via a cross-modal retrieval task.
SelectTTS: Synthesizing Anyone's Voice via Discrete Unit-Based Frame Selection
Aug 30, 2024



Synthesizing the voices of unseen speakers is a persisting challenge in multi-speaker text-to-speech (TTS). Most multi-speaker TTS models rely on modeling speaker characteristics through speaker conditioning during training. Modeling unseen speaker attributes through this approach has necessitated an increase in model complexity, which makes it challenging to reproduce results and improve upon them. We design a simple alternative to this. We propose SelectTTS, a novel method to select the appropriate frames from the target speaker and decode using frame-level self-supervised learning (SSL) features. We show that this approach can effectively capture speaker characteristics for unseen speakers, and achieves comparable results to other multi-speaker TTS frameworks in both objective and subjective metrics. With SelectTTS, we show that frame selection from the target speaker's speech is a direct way to achieve generalization in unseen speakers with low model complexity. We achieve better speaker similarity performance than SOTA baselines XTTS-v2 and VALL-E with over an 8x reduction in model parameters and a 270x reduction in training data
Towards Naturalistic Voice Conversion: NaturalVoices Dataset with an Automatic Processing Pipeline
Jun 06, 2024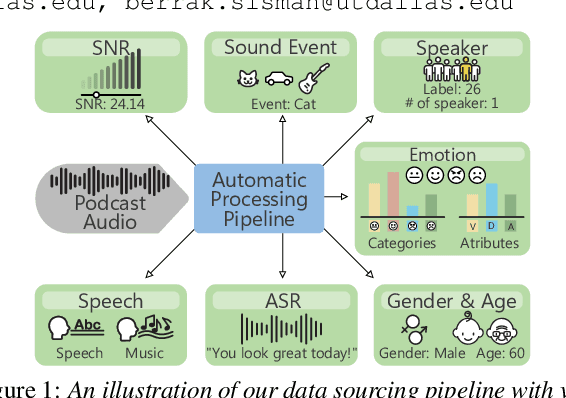
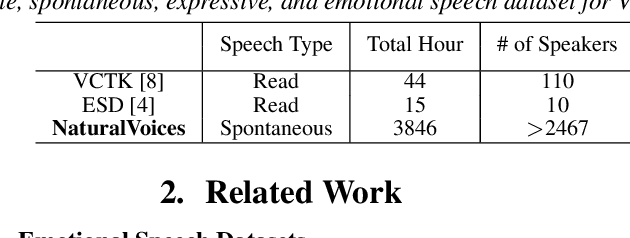
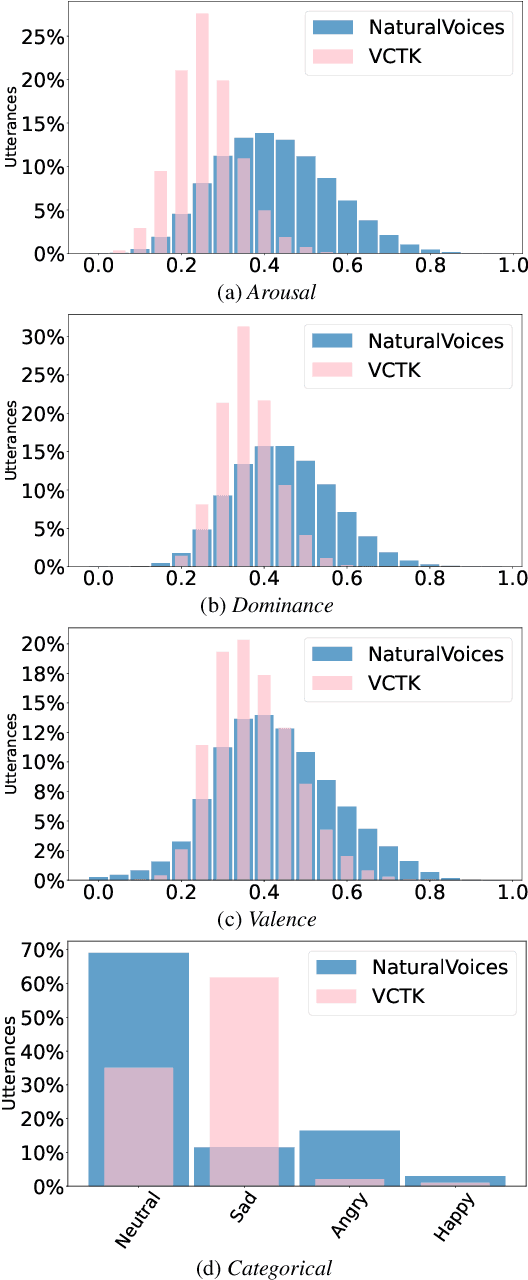
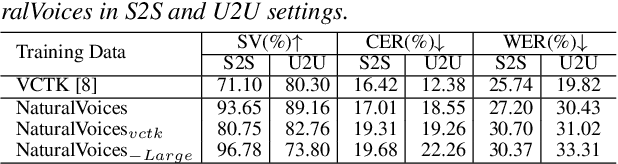
Voice conversion (VC) research traditionally depends on scripted or acted speech, which lacks the natural spontaneity of real-life conversations. While natural speech data is limited for VC, our study focuses on filling in this gap. We introduce a novel data-sourcing pipeline that makes the release of a natural speech dataset for VC, named NaturalVoices. The pipeline extracts rich information in speech such as emotion and signal-to-noise ratio (SNR) from raw podcast data, utilizing recent deep learning methods and providing flexibility and ease of use. NaturalVoices marks a large-scale, spontaneous, expressive, and emotional speech dataset, comprising over 3,800 hours speech sourced from the original podcasts in the MSP-Podcast dataset. Objective and subjective evaluations demonstrate the effectiveness of using our pipeline for providing natural and expressive data for VC, suggesting the potential of NaturalVoices for broader speech generation tasks.
Style Mixture of Experts for Expressive Text-To-Speech Synthesis
Jun 05, 2024



Recent advances in style transfer text-to-speech (TTS) have improved the expressiveness of synthesized speech. Despite these advancements, encoding stylistic information from diverse and unseen reference speech remains challenging. This paper introduces StyleMoE, an approach that divides the embedding space, modeled by the style encoder, into tractable subsets handled by style experts. The proposed method replaces the style encoder in a TTS system with a Mixture of Experts (MoE) layer. By utilizing a gating network to route reference speeches to different style experts, each expert specializes in aspects of the style space during optimization. Our experiments objectively and subjectively demonstrate the effectiveness of our proposed method in increasing the coverage of the style space for diverse and unseen styles. This approach can enhance the performance of existing state-of-the-art style transfer TTS models, marking the first study of MoE in style transfer TTS to our knowledge.
Exploring speech style spaces with language models: Emotional TTS without emotion labels
May 18, 2024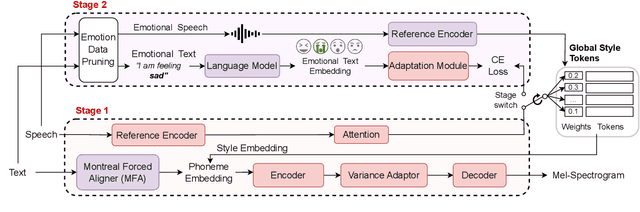
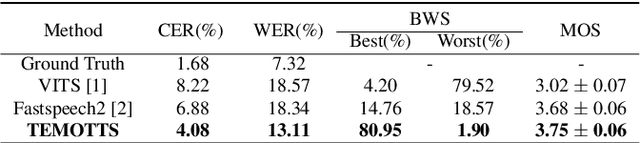
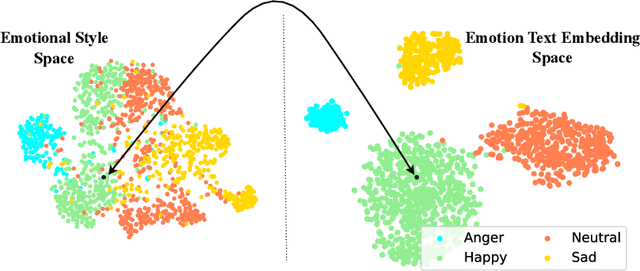

Many frameworks for emotional text-to-speech (E-TTS) rely on human-annotated emotion labels that are often inaccurate and difficult to obtain. Learning emotional prosody implicitly presents a tough challenge due to the subjective nature of emotions. In this study, we propose a novel approach that leverages text awareness to acquire emotional styles without the need for explicit emotion labels or text prompts. We present TEMOTTS, a two-stage framework for E-TTS that is trained without emotion labels and is capable of inference without auxiliary inputs. Our proposed method performs knowledge transfer between the linguistic space learned by BERT and the emotional style space constructed by global style tokens. Our experimental results demonstrate the effectiveness of our proposed framework, showcasing improvements in emotional accuracy and naturalness. This is one of the first studies to leverage the emotional correlation between spoken content and expressive delivery for emotional TTS.
A Survey on Machine Learning Algorithms for Applications in Cognitive Radio Networks
Jun 19, 2021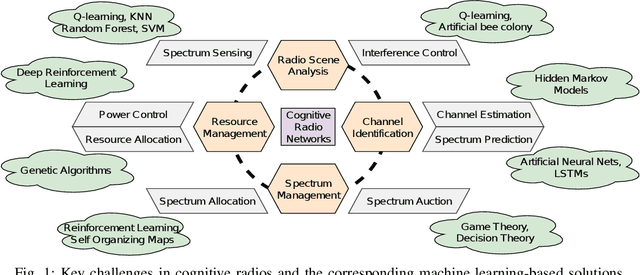
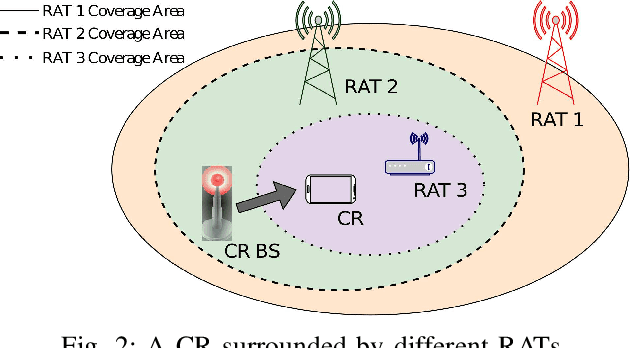
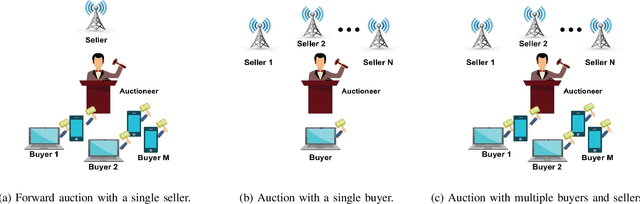
In this paper, we present a survey on the utility of machine learning (ML) algorithms for applications in cognitive radio networks (CRN). We start with a high-level overview of some of the major challenges in CRNs, and mention the ML architectures and algorithms that can be used to alleviate them. In particular, our focus is on two fundamental applications in CRNs, namely spectrum sensing -- with non-cooperative and cooperative scenarios, and dynamic spectrum access -- with spectrum auction and prediction. We present a detailed study of recent advancements in the field of ML in CRNs for these applications, and briefly discuss the set of challenges in real-time implementation of ML techniques for CRNs.