 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Naturalistic Voice Conversion: NaturalVoices Dataset with an Automatic Processing Pipeline
Jun 06, 2024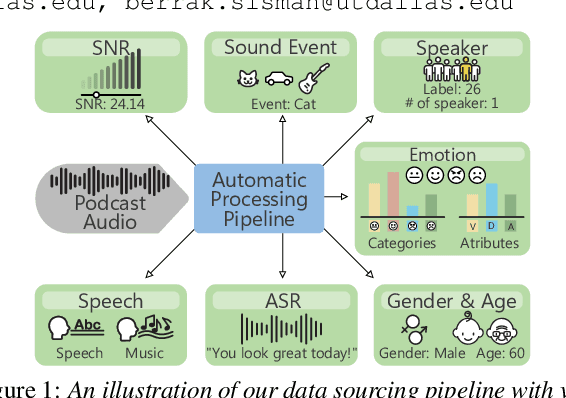
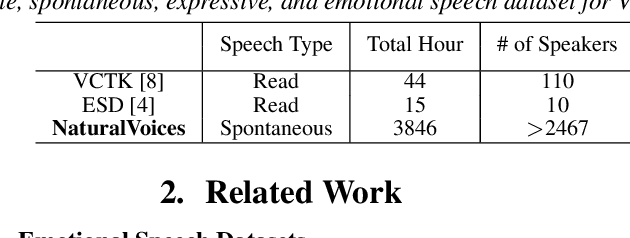
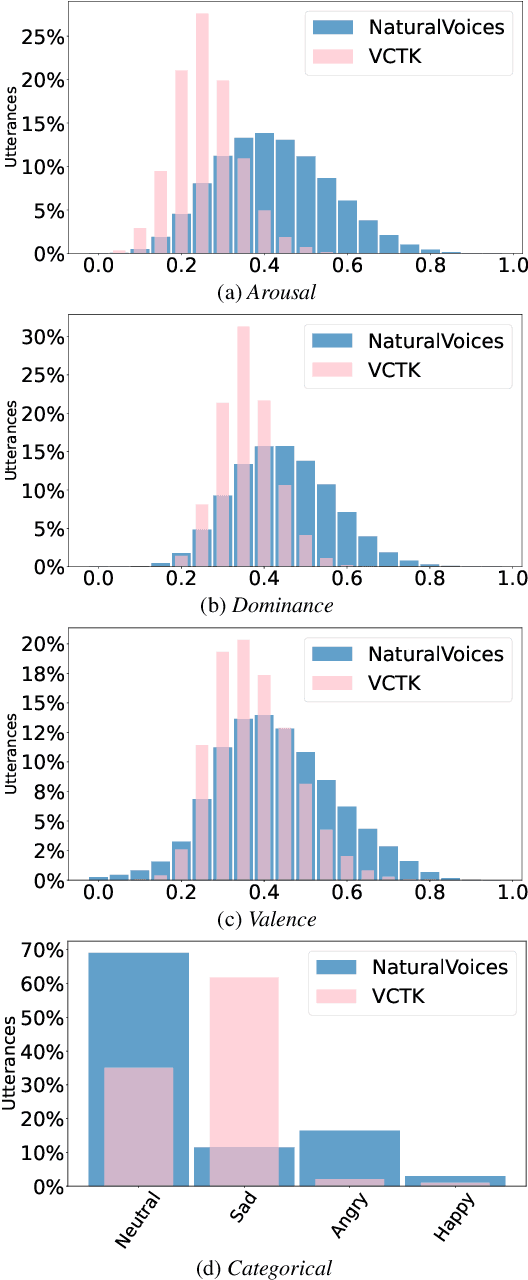
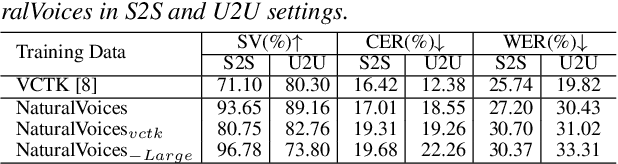
Voice conversion (VC) research traditionally depends on scripted or acted speech, which lacks the natural spontaneity of real-life conversations. While natural speech data is limited for VC, our study focuses on filling in this gap. We introduce a novel data-sourcing pipeline that makes the release of a natural speech dataset for VC, named NaturalVoices. The pipeline extracts rich information in speech such as emotion and signal-to-noise ratio (SNR) from raw podcast data, utilizing recent deep learning methods and providing flexibility and ease of use. NaturalVoices marks a large-scale, spontaneous, expressive, and emotional speech dataset, comprising over 3,800 hours speech sourced from the original podcasts in the MSP-Podcast dataset. Objective and subjective evaluations demonstrate the effectiveness of using our pipeline for providing natural and expressive data for VC, suggesting the potential of NaturalVoices for broader speech generation tasks.
Exploring speech style spaces with language models: Emotional TTS without emotion labels
May 18, 2024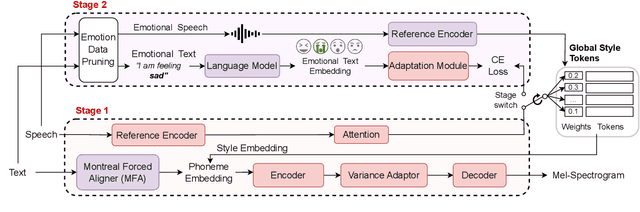
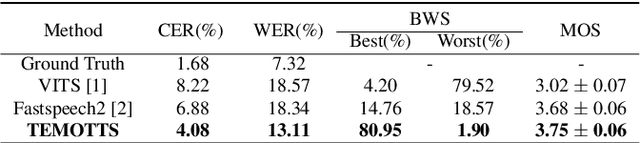
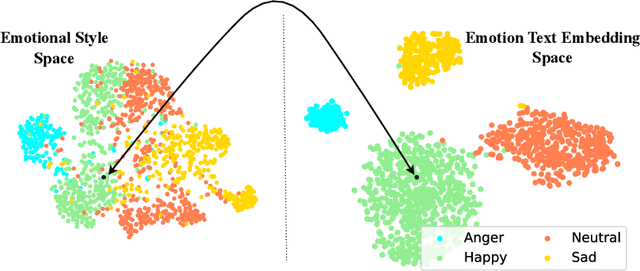

Many frameworks for emotional text-to-speech (E-TTS) rely on human-annotated emotion labels that are often inaccurate and difficult to obtain. Learning emotional prosody implicitly presents a tough challenge due to the subjective nature of emotions. In this study, we propose a novel approach that leverages text awareness to acquire emotional styles without the need for explicit emotion labels or text prompts. We present TEMOTTS, a two-stage framework for E-TTS that is trained without emotion labels and is capable of inference without auxiliary inputs. Our proposed method performs knowledge transfer between the linguistic space learned by BERT and the emotional style space constructed by global style tokens. Our experimental results demonstrate the effectiveness of our proposed framework, showcasing improvements in emotional accuracy and naturalness. This is one of the first studies to leverage the emotional correlation between spoken content and expressive delivery for emotional TTS.
Converting Anyone's Voice: End-to-End Expressive Voice Conversion with a Conditional Diffusion Model
May 02, 2024



Expressive voice conversion (VC) conducts speaker identity conversion for emotional speakers by jointly converting speaker identity and emotional style. Emotional style modeling for arbitrary speakers in expressive VC has not been extensively explored. Previous approaches have relied on vocoders for speech reconstruction, which makes speech quality heavily dependent on the performance of vocoders. A major challenge of expressive VC lies in emotion prosody modeling. To address these challenges, this paper proposes a fully end-to-end expressive VC framework based on a conditional denoising diffusion probabilistic model (DDPM). We utilize speech units derived from self-supervised speech models as content conditioning, along with deep features extracted from speech emotion recognition and speaker verification systems to model emotional style and speaker identity. Objective and subjective evaluations show the effectiveness of our framework. Codes and samples are publicly available.
Revealing Emotional Clusters in Speaker Embeddings: A Contrastive Learning Strategy for Speech Emotion Recognition
Jan 19, 2024Speaker embeddings carry valuable emotion-related information, which makes them a promising resource for enhancing speech emotion recognition (SER), especially with limited labeled data. Traditionally, it has been assumed that emotion information is indirectly embedded within speaker embeddings, leading to their under-utilization. Our study reveals a direct and useful link between emotion and state-of-the-art speaker embeddings in the form of intra-speaker clusters. By conducting a thorough clustering analysis, we demonstrate that emotion information can be readily extracted from speaker embeddings. In order to leverage this information, we introduce a novel contrastive pretraining approach applied to emotion-unlabeled data for speech emotion recognition. The proposed approach involves the sampling of positive and the negative examples based on the intra-speaker clusters of speaker embeddings. The proposed strategy, which leverages extensive emotion-unlabeled data, leads to a significant improvement in SER performance, whether employed as a standalone pretraining task or integrated into a multi-task pretraining setting.
Identity Conversion for Emotional Speakers: A Study for Disentanglement of Emotion Style and Speaker Identity
Oct 20, 2021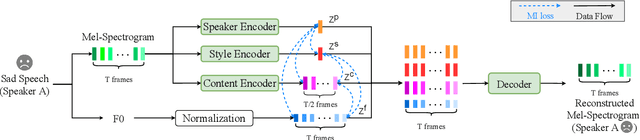
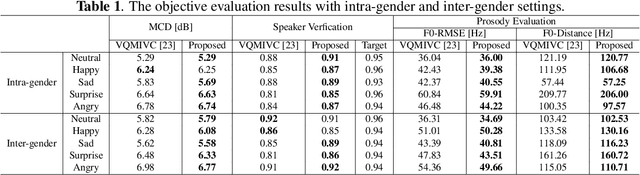

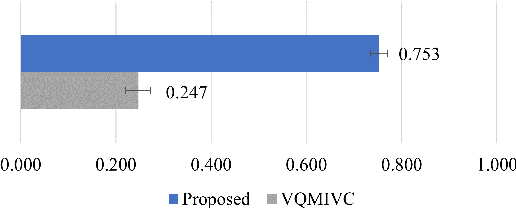
Expressive voice conversion performs identity conversion for emotional speakers by jointly converting speaker identity and speaker-dependent emotion style. Due to the hierarchical structure of speech emotion, it is challenging to disentangle the speaker-dependent emotional style for expressive voice conversion. Motivated by the recent success on speaker disentanglement with variational autoencoder (VAE), we propose an expressive voice conversion framework which can effectively disentangle linguistic content, speaker identity, pitch, and emotional style information. We study the use of emotion encoder to model emotional style explicitly, and introduce mutual information (MI) losses to reduce the irrelevant information from the disentangled emotion representations. At run-time, our proposed framework can convert both speaker identity and speaker-dependent emotional style without the need for parallel data. Experimental results validate the effectiveness of our proposed framework in both objective and subjective evaluations.
Expressive Voice Conversion: A Joint Framework for Speaker Identity and Emotional Style Transfer
Jul 08, 2021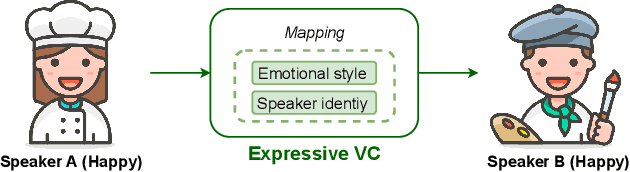
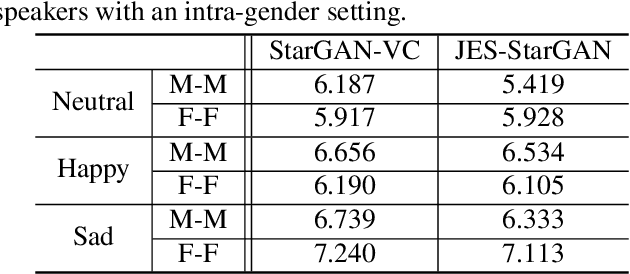
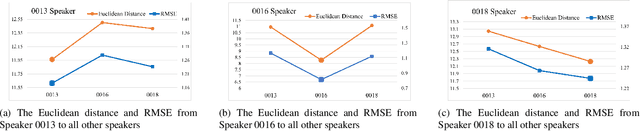

Traditional voice conversion(VC) has been focused on speaker identity conversion for speech with a neutral expression. We note that emotional expression plays an essential role in daily communication, and the emotional style of speech can be speaker-dependent. In this paper, we study the technique to jointly convert the speaker identity and speaker-dependent emotional style, that is called expressive voice conversion. We propose a StarGAN-based framework to learn a many-to-many mapping across different speakers, that takes into account speaker-dependent emotional style without the need for parallel data. To achieve this, we condition the generator on emotional style encoding derived from a pre-trained speech emotion recognition(SER) model. The experiments validate the effectiveness of our proposed framework in both objective and subjective evaluations. To our best knowledge, this is the first study on expressive voice conversion.
Spectrum and Prosody Conversion for Cross-lingual Voice Conversion with CycleGAN
Aug 12, 2020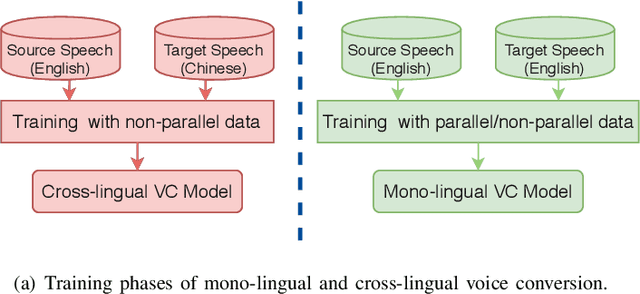
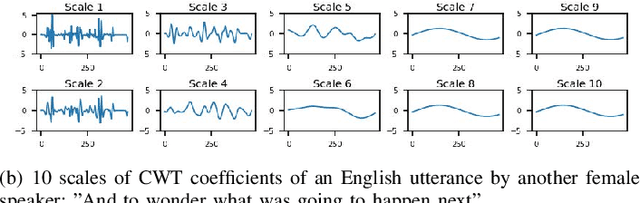
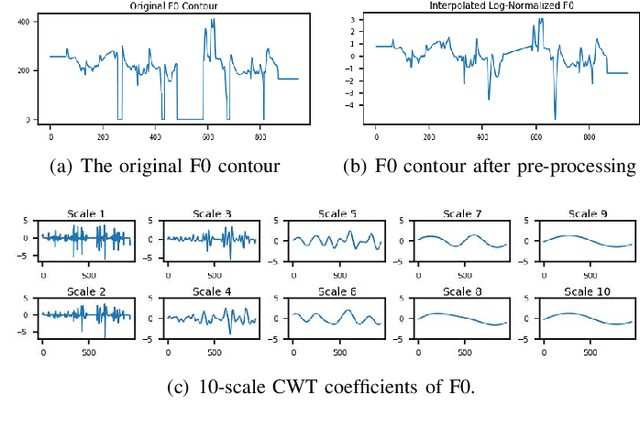
Cross-lingual voice conversion aims to change source speaker's voice to sound like that of target speaker, when source and target speakers speak different languages. It relies on non-parallel training data from two different languages, hence, is more challenging than mono-lingual voice conversion. Previous studies on cross-lingual voice conversion mainly focus on spectral conversion with a linear transformation for F0 transfer. However, as an important prosodic factor, F0 is inherently hierarchical, thus it is insufficient to just use a linear method for conversion. We propose the use of continuous wavelet transform (CWT) decomposition for F0 modeling. CWT provides a way to decompose a signal into different temporal scales that explain prosody in different time resolutions. We also propose to train two CycleGAN pipelines for spectrum and prosody mapping respectively. In this way, we eliminate the need for parallel data of any two languages and any alignment techniques. Experimental results show that our proposed Spectrum-Prosody-CycleGAN framework outperforms the Spectrum-CycleGAN baseline in subjective evaluation. To our best knowledge, this is the first study of prosody in cross-lingual voice conversion.