 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity Conversion for Emotional Speakers: A Study for Disentanglement of Emotion Style and Speaker Identity
Paper and Code
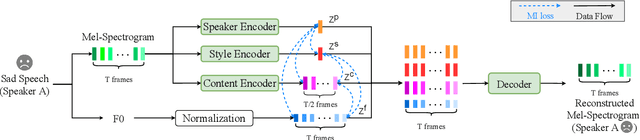
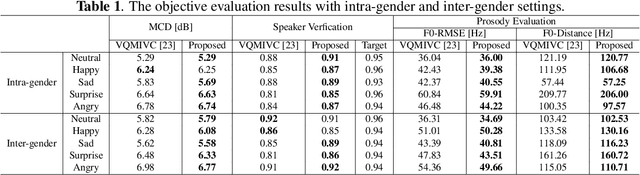

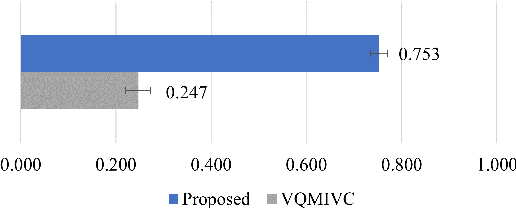
Expressive voice conversion performs identity conversion for emotional speakers by jointly converting speaker identity and speaker-dependent emotion style. Due to the hierarchical structure of speech emotion, it is challenging to disentangle the speaker-dependent emotional style for expressive voice conversion. Motivated by the recent success on speaker disentanglement with variational autoencoder (VAE), we propose an expressive voice conversion framework which can effectively disentangle linguistic content, speaker identity, pitch, and emotional style information. We study the use of emotion encoder to model emotional style explicitly, and introduce mutual information (MI) losses to reduce the irrelevant information from the disentangled emotion representations. At run-time, our proposed framework can convert both speaker identity and speaker-dependent emotional style without the need for parallel data. Experimental results validate the effectiveness of our proposed framework in both objective and subjective evaluations.