 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring speech style spaces with language models: Emotional TTS without emotion labels
Paper and Code
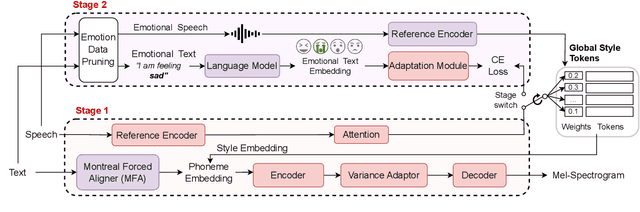
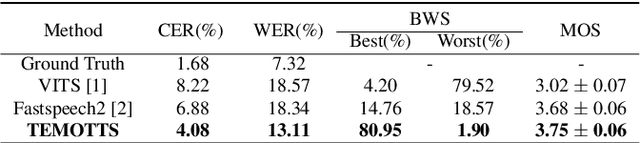
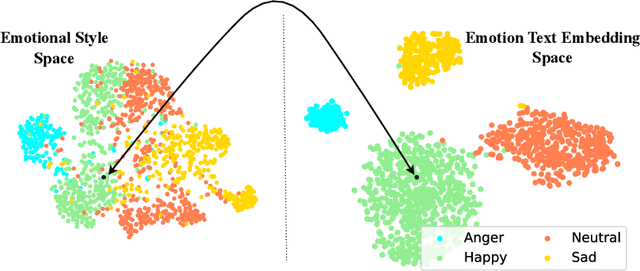

Many frameworks for emotional text-to-speech (E-TTS) rely on human-annotated emotion labels that are often inaccurate and difficult to obtain. Learning emotional prosody implicitly presents a tough challenge due to the subjective nature of emotions. In this study, we propose a novel approach that leverages text awareness to acquire emotional styles without the need for explicit emotion labels or text prompts. We present TEMOTTS, a two-stage framework for E-TTS that is trained without emotion labels and is capable of inference without auxiliary inputs. Our proposed method performs knowledge transfer between the linguistic space learned by BERT and the emotional style space constructed by global style tokens. Our experimental results demonstrate the effectiveness of our proposed framework, showcasing improvements in emotional accuracy and naturalness. This is one of the first studies to leverage the emotional correlation between spoken content and expressive delivery for emotional TTS.