 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum and Prosody Conversion for Cross-lingual Voice Conversion with CycleGAN
Paper and Code
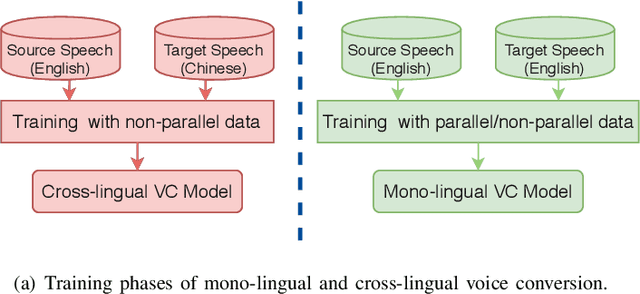
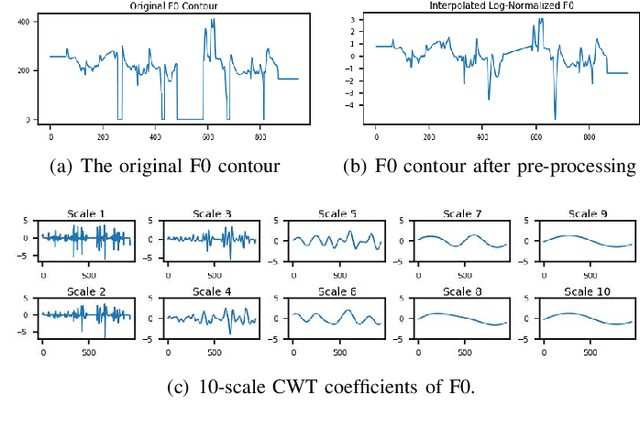
Cross-lingual voice conversion aims to change source speaker's voice to sound like that of target speaker, when source and target speakers speak different languages. It relies on non-parallel training data from two different languages, hence, is more challenging than mono-lingual voice conversion. Previous studies on cross-lingual voice conversion mainly focus on spectral conversion with a linear transformation for F0 transfer. However, as an important prosodic factor, F0 is inherently hierarchical, thus it is insufficient to just use a linear method for conversion. We propose the use of continuous wavelet transform (CWT) decomposition for F0 modeling. CWT provides a way to decompose a signal into different temporal scales that explain prosody in different time resolutions. We also propose to train two CycleGAN pipelines for spectrum and prosody mapping respectively. In this way, we eliminate the need for parallel data of any two languages and any alignment techniques. Experimental results show that our proposed Spectrum-Prosody-CycleGAN framework outperforms the Spectrum-CycleGAN baseline in subjective evaluation. To our best knowledge, this is the first study of prosody in cross-lingual voice conversion.