 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeemoDARTS: Joint Optimisation of CNN & Sequential Neural Network Architectures for Superior Speech Emotion Recognition
Paper and Code
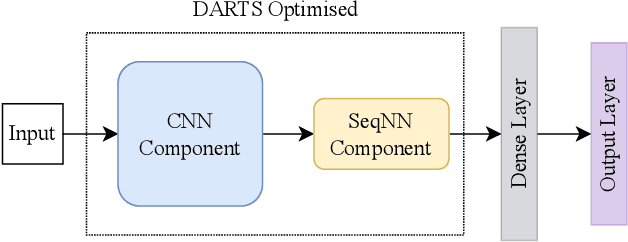
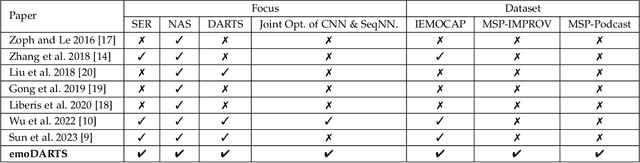
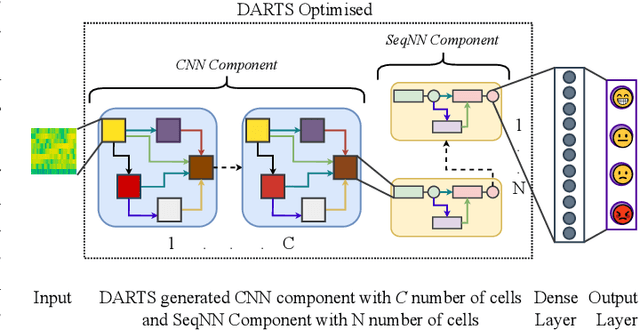

Speech Emotion Recognition (SER) is crucial for enabling computers to understand the emotions conveyed in human communication. With recent advancements in Deep Learning (DL), the performance of SER models has significantly improved. However, designing an optimal DL architecture requires specialised knowledge and experimental assessments. Fortunately, Neural Architecture Search (NAS) provides a potential solution for automatically determining the best DL model. The Differentiable Architecture Search (DARTS) is a particularly efficient method for discovering optimal models. This study presents emoDARTS, a DARTS-optimised joint CNN and Sequential Neural Network (SeqNN: LSTM, RNN) architecture that enhances SER performance. The literature supports the selection of CNN and LSTM coupling to improve performance. While DARTS has previously been used to choose CNN and LSTM operations independently, our technique adds a novel mechanism for selecting CNN and SeqNN operations in conjunction using DARTS. Unlike earlier work, we do not impose limits on the layer order of the CNN. Instead, we let DARTS choose the best layer order inside the DARTS cell. We demonstrate that emoDARTS outperforms conventionally designed CNN-LSTM models and surpasses the best-reported SER results achieved through DARTS on CNN-LSTM by evaluating our approach on the IEMOCAP, MSP-IMPROV, and MSP-Podcast datasets.