 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs It Still Fair? Investigating Gender Fairness in Cross-Corpus Speech Emotion Recognition
Jan 02, 2025



Speech emotion recognition (SER) is a vital component in various everyday applications. Cross-corpus SER models are increasingly recognized for their ability to generalize performance. However, concerns arise regarding fairness across demographics in diverse corpora. Existing fairness research often focuses solely on corpus-specific fairness, neglecting its generalizability in cross-corpus scenarios. Our study focuses on this underexplored area, examining the gender fairness generalizability in cross-corpus SER scenarios. We emphasize that the performance of cross-corpus SER models and their fairness are two distinct considerations. Moreover, we propose the approach of a combined fairness adaptation mechanism to enhance gender fairness in the SER transfer learning tasks by addressing both source and target genders. Our findings bring one of the first insights into the generalizability of gender fairness in cross-corpus SER systems.
Mouth Articulation-Based Anchoring for Improved Cross-Corpus Speech Emotion Recognition
Dec 27, 2024Cross-corpus speech emotion recognition (SER) plays a vital role in numerous practical applications. Traditional approaches to cross-corpus emotion transfer often concentrate on adapting acoustic features to align with different corpora, domains, or labels. However, acoustic features are inherently variable and error-prone due to factors like speaker differences, domain shifts, and recording conditions. To address these challenges, this study adopts a novel contrastive approach by focusing on emotion-specific articulatory gestures as the core elements for analysis. By shifting the emphasis on the more stable and consistent articulatory gestures, we aim to enhance emotion transfer learning in SER tasks. Our research leverages the CREMA-D and MSP-IMPROV corpora as benchmarks and it reveals valuable insights into the commonality and reliability of these articulatory gestures. The findings highlight mouth articulatory gesture potential as a better constraint for improving emotion recognition across different settings or domains.
A Layer-Anchoring Strategy for Enhancing Cross-Lingual Speech Emotion Recognition
Jul 06, 2024

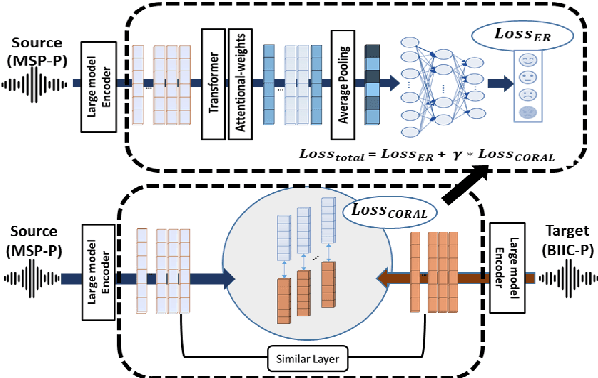

Cross-lingual speech emotion recognition (SER) is important for a wide range of everyday applications. While recent SER research relies heavily on large pretrained models for emotion training, existing studies often concentrate solely on the final transformer layer of these models. However, given the task-specific nature and hierarchical architecture of these models, each transformer layer encapsulates different levels of information. Leveraging this hierarchical structure, our study focuses on the information embedded across different layers. Through an examination of layer feature similarity across different languages, we propose a novel strategy called a layer-anchoring mechanism to facilitate emotion transfer in cross-lingual SER tasks. Our approach is evaluated using two distinct language affective corpora (MSP-Podcast and BIIC-Podcast), achieving a best UAR performance of 60.21% on the BIIC-podcast corpus. The analysis uncovers interesting insights into the behavior of popular pretrained models.