 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACROCPoLis: A Descriptive Framework for Making Sense of Fairness
Apr 19, 2023
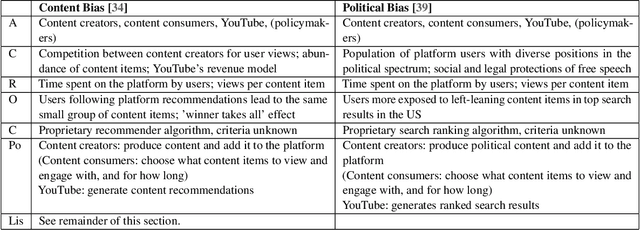
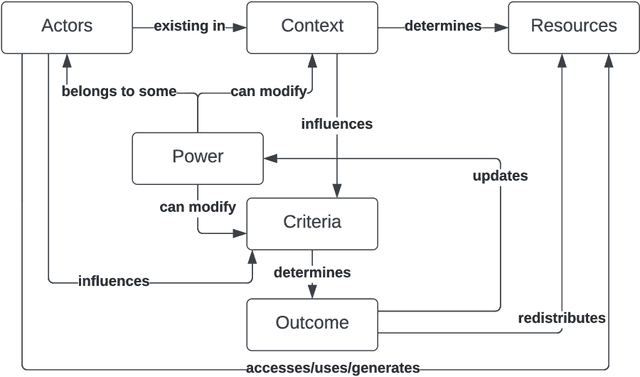
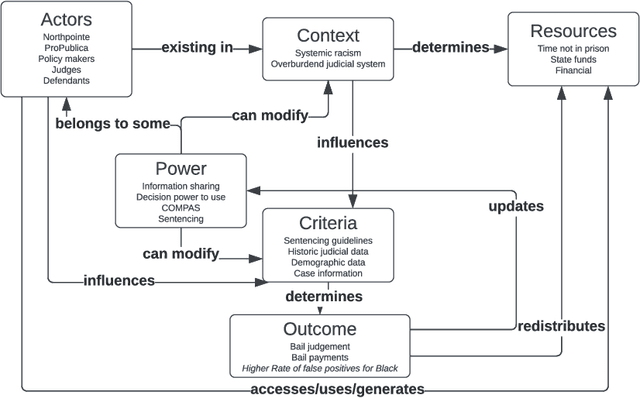
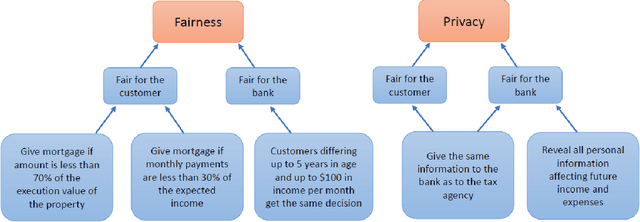
Fairness is central to the ethical and responsible development and use of AI systems, with a large number of frameworks and formal notions of algorithmic fairness being available. However, many of the fairness solutions proposed revolve around technical considerations and not the needs of and consequences for the most impacted communities. We therefore want to take the focus away from definitions and allow for the inclusion of societal and relational aspects to represent how the effects of AI systems impact and are experienced by individuals and social groups. In this paper, we do this by means of proposing the ACROCPoLis framework to represent allocation processes with a modeling emphasis on fairness aspects. The framework provides a shared vocabulary in which the factors relevant to fairness assessments for different situations and procedures are made explicit, as well as their interrelationships. This enables us to compare analogous situations, to highlight the differences in dissimilar situations, and to capture differing interpretations of the same situation by different stakeholders.
Interrogating the Black Box: Transparency through Information-Seeking Dialogues
Feb 09, 2021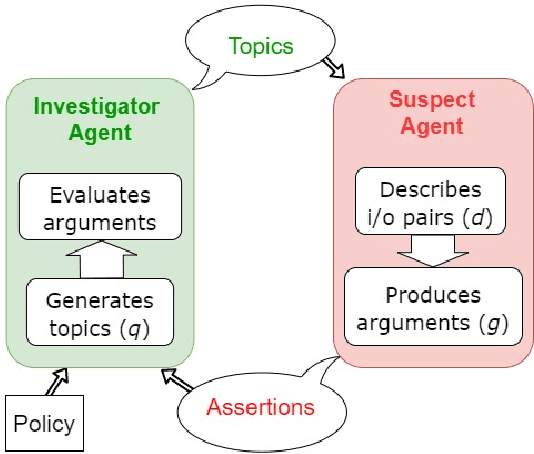

This paper is preoccupied with the following question: given a (possibly opaque) learning system, how can we understand whether its behaviour adheres to governance constraints? The answer can be quite simple: we just need to "ask" the system about it. We propose to construct an investigator agent to query a learning agent -- the suspect agent -- to investigate its adherence to a given ethical policy in the context of an information-seeking dialogue, modeled in formal argumentation settings. This formal dialogue framework is the main contribution of this paper. Through it, we break down compliance checking mechanisms into three modular components, each of which can be tailored to various needs in a vast amount of ways: an investigator agent, a suspect agent, and an acceptance protocol determining whether the responses of the suspect agent comply with the policy. This acceptance protocol presents a fundamentally different approach to aggregation: rather than using quantitative methods to deal with the non-determinism of a learning system, we leverage the use of argumentation semantics to investigate the notion of properties holding consistently. Overall, we argue that the introduced formal dialogue framework opens many avenues both in the area of compliance checking and in the analysis of properties of opaque systems.
Contestable Black Boxes
Jun 30, 2020The right to contest a decision with consequences on individuals or the society is a well-established democratic right. Despite this right also being explicitly included in GDPR in reference to automated decision-making, its study seems to have received much less attention in the AI literature compared, for example, to the right for explanation. This paper investigates the type of assurances that are needed in the contesting process when algorithmic black-boxes are involved, opening new questions about the interplay of contestability and explainability. We argue that specialised complementary methodologies to evaluate automated decision-making in the case of a particular decision being contested need to be developed. Further, we propose a combination of well-established software engineering and rule-based approaches as a possible socio-technical solution to the issue of contestability, one of the new democratic challenges posed by the automation of decision making.
Governance by Glass-Box: Implementing Transparent Moral Bounds for AI Behaviour
Apr 30, 2019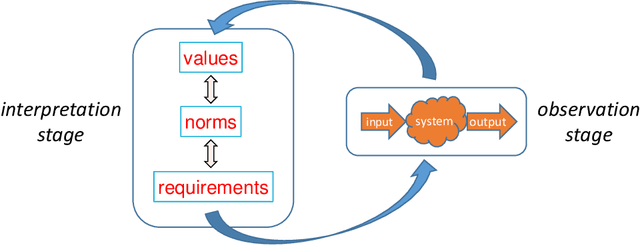
Artificial Intelligence (AI) applications are being used to predict and assess behaviour in multiple domains, such as criminal justice and consumer finance, which directly affect human well-being. However, if AI is to improve people's lives, then people must be able to trust AI, which means being able to understand what the system is doing and why. Even though transparency is often seen as the requirement in this case, realistically it might not always be possible or desirable, whereas the need to ensure that the system operates within set moral bounds remains. In this paper, we present an approach to evaluate the moral bounds of an AI system based on the monitoring of its inputs and outputs. We place a "glass box" around the system by mapping moral values into explicit verifiable norms that constrain inputs and outputs, in such a way that if these remain within the box we can guarantee that the system adheres to the value. The focus on inputs and outputs allows for the verification and comparison of vastly different intelligent systems; from deep neural networks to agent-based systems. The explicit transformation of abstract moral values into concrete norms brings great benefits in terms of explainability; stakeholders know exactly how the system is interpreting and employing relevant abstract moral human values and calibrate their trust accordingly. Moreover, by operating at a higher level we can check the compliance of the system with different interpretations of the same value. These advantages will have an impact on the well-being of AI systems users at large, building their trust and providing them with concrete knowledge on how systems adhere to moral values.