 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-Machine Collaboration Framework for the Development of Schemas
Feb 06, 2024The Winograd Schema Challenge (WSC), a seemingly well-thought-out test for machine intelligence, has been proposed to shed light on developing systems that exhibit human behavior. Since its introduction, it aimed to pivot the focus of the AI community from the technology to the science of AI. While common and trivial for humans, studies show that it is still challenging for machines, especially when they have to deal with novel schemas, that is, well-designed sentences that require the resolving of definite pronouns. As researchers have become increasingly interested in the challenge itself, this presumably necessitates the availability of an extensive collection of Winograd schemas, which goes beyond what human experts can reasonably develop themselves, especially after proposed ways of utilizing them as novel forms of CAPTCHAs. To address this necessity, we propose a novel framework that explicitly focuses on how humans and machines can collaborate as teammates to design novel schemas from scratch. This is being accomplished by combining two recent studies from the literature: i) Winventor, a machine-driven approach for the development of large amounts of Winograd schemas, albeit not of high quality, and ii) WinoFlexi, an online crowdsourcing system that allows crowd workers to develop a limited number of schemas often of similar quality to that of experts. Our proposal crafts a new road map toward developing a novel collaborative platform that amplifies human and machine intelligence by combining their complementary strengths.
Experience and Prediction: A Metric of Hardness for a Novel Litmus Test
Sep 05, 2023In the last decade, the Winograd Schema Challenge (WSC) has become a central aspect of the research community as a novel litmus test. Consequently, the WSC has spurred research interest because it can be seen as the means to understand human behavior. In this regard, the development of new techniques has made possible the usage of Winograd schemas in various fields, such as the design of novel forms of CAPTCHAs. Work from the literature that established a baseline for human adult performance on the WSC has shown that not all schemas are the same, meaning that they could potentially be categorized according to their perceived hardness for humans. In this regard, this \textit{hardness-metric} could be used in future challenges or in the WSC CAPTCHA service to differentiate between Winograd schemas. Recent work of ours has shown that this could be achieved via the design of an automated system that is able to output the hardness-indexes of Winograd schemas, albeit with limitations regarding the number of schemas it could be applied on. This paper adds to previous research by presenting a new system that is based on Machine Learning (ML), able to output the hardness of any Winograd schema faster and more accurately than any other previously used method. Our developed system, which works within two different approaches, namely the random forest and deep learning (LSTM-based), is ready to be used as an extension of any other system that aims to differentiate between Winograd schemas, according to their perceived hardness for humans. At the same time, along with our developed system we extend previous work by presenting the results of a large-scale experiment that shows how human performance varies across Winograd schemas.
* 33 pages, 10 figures,
PronounFlow: A Hybrid Approach for Calibrating Pronouns in Sentences
Aug 29, 2023Flip through any book or listen to any song lyrics, and you will come across pronouns that, in certain cases, can hinder meaning comprehension, especially for machines. As the role of having cognitive machines becomes pervasive in our lives, numerous systems have been developed to resolve pronouns under various challenges. Commensurate with this, it is believed that having systems able to disambiguate pronouns in sentences will help towards the endowment of machines with commonsense and reasoning abilities like those found in humans. However, one problem these systems face with modern English is the lack of gender pronouns, where people try to alternate by using masculine, feminine, or plural to avoid the whole issue. Since humanity aims to the building of systems in the full-bodied sense we usually reserve for people, what happens when pronouns in written text, like plural or epicene ones, refer to unspecified entities whose gender is not necessarily known? Wouldn't that put extra barriers to existing coreference resolution systems? Towards answering those questions, through the implementation of a neural-symbolic system that utilizes the best of both worlds, we are employing PronounFlow, a system that reads any English sentence with pronouns and entities, identifies which of them are not tied to each other, and makes suggestions on which to use to avoid biases. Undertaken experiments show that PronounFlow not only alternates pronouns in sentences based on the collective human knowledge around us but also considerably helps coreference resolution systems with the pronoun disambiguation process.
A Neural-Symbolic Approach Towards Identifying Grammatically Correct Sentences
Jul 16, 2023Textual content around us is growing on a daily basis. Numerous articles are being written as we speak on online newspapers, blogs, or social media. Similarly, recent advances in the AI field, like language models or traditional classic AI approaches, are utilizing all the above to improve their learned representation to tackle NLP challenges with human-like accuracy. It is commonly accepted that it is crucial to have access to well-written text from valid sources to tackle challenges like text summarization, question-answering, machine translation, or even pronoun resolution. For instance, to summarize well, one needs to select the most important sentences in order to concatenate them to form the summary. However, what happens if we do not have access to well-formed English sentences or even non-valid sentences? Despite the importance of having access to well-written sentences, figuring out ways to validate them is still an open area of research. To address this problem, we present a simplified way to validate English sentences through a novel neural-symbolic approach. Lately, neural-symbolic approaches have triggered an increasing interest towards tackling various NLP challenges, as they are demonstrating their effectiveness as a central component in various AI systems. Through combining Classic with Modern AI, which involves the blending of grammatical and syntactical rules with language models, we effectively tackle the Corpus of Linguistic Acceptability (COLA), a task that shows whether or not a sequence of words is an English grammatical sentence. Among others, undertaken experiments effectively show that blending symbolic and non-symbolic systems helps the former provide insights about the latter's accuracy results.
A Zero-Shot Classification Approach for a Word-Guessing Challenge
Jun 27, 2022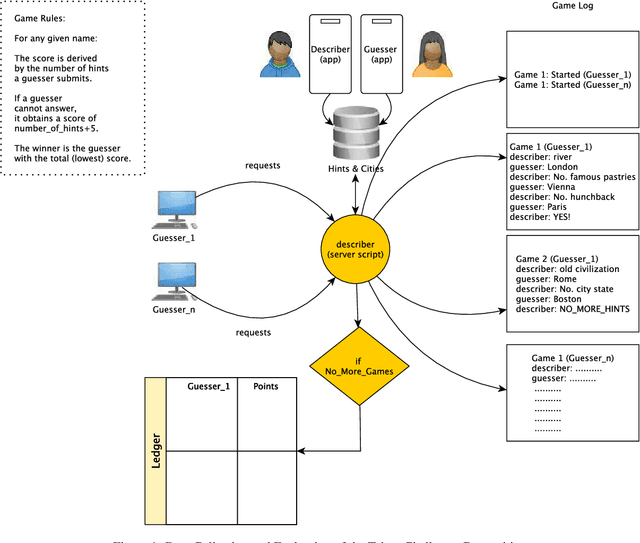



The Taboo Challenge competition, a task based on the well-known Taboo game, has been proposed to stimulate research in the AI field. The challenge requires building systems able to comprehend the implied inferences between the exchanged messages of guesser and describer agents. A describer sends pre-determined hints to guessers indirectly describing cities, and guessers are required to return the matching cities implied by the hints. Climbing up the scoring ledger requires the resolving of the highest amount of cities with the smallest amount of hints in a specified time frame. Here, we present TabooLM, a language-model approach that tackles the challenge based on a zero-shot setting. We start by presenting and comparing the results of this approach with three studies from the literature. The results show that our method achieves SOTA results on the Taboo challenge, suggesting that TabooLM can guess the implied cities faster and more accurately than existing approaches.