 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSky2Ground: A Benchmark for Site Modeling under Varying Altitude
Mar 14, 2026We introduce Sky2Ground, a three-view dataset designed for varying altitude camera localization, correspondence learning, and reconstruction. The dataset combines structured synthetic imagery with real, in-the-wild images, providing both controlled multi-view geometry and realistic scene noise. Each of the 51 sites contains thousands of satellite, aerial, and ground images spanning wide altitude ranges and nearly orthogonal viewing angles, enabling rigorous evaluation across global-to-local contexts. We benchmark state of the art pose estimation models, including MASt3R, DUSt3R, Map Anything, and VGGT, and observe that the use of satellite imagery often degrades performance, highlighting the challenges under large altitude variations. We also examine reconstruction methods, highlighting the challenges introduced by sparse geometric overlap, varying perspectives, and the use of real imagery, which often introduces noise and reduces rendering quality. To address some of these challenges, we propose SkyNet, a model which enhances cross-view consistency when incorporating satellite imagery with a curriculum-based training strategy to progressively incorporate more satellite views. SkyNet significantly strengthens multi-view alignment and outperforms existing methods by 9.6% on RRA@5 and 18.1% on RTA@5 in terms of absolute performance. Sky2Ground and SkyNet together establish a comprehensive testbed and baseline for advancing large-scale, multi-altitude 3D perception and generalizable camera localization. Code and models will be released publicly for future research.
Few-shot Semantic Learning for Robust Multi-Biome 3D Semantic Mapping in Off-Road Environments
Nov 10, 2024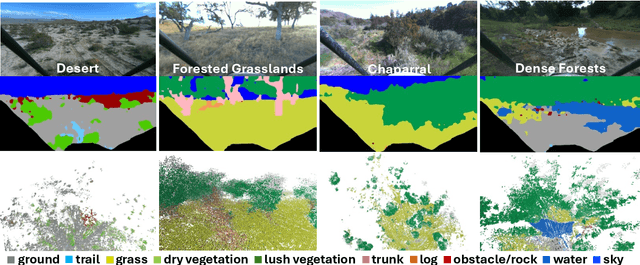
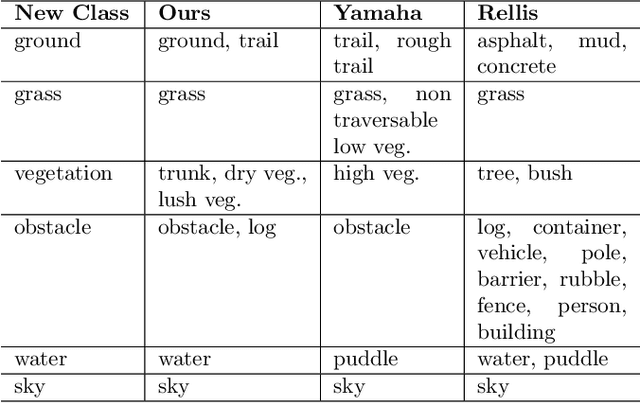

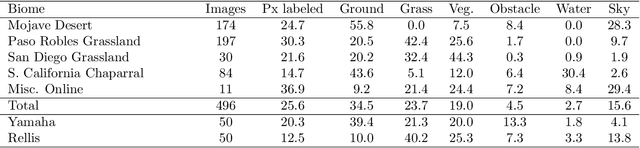
Off-road environments pose significant perception challenges for high-speed autonomous navigation due to unstructured terrain, degraded sensing conditions, and domain-shifts among biomes. Learning semantic information across these conditions and biomes can be challenging when a large amount of ground truth data is required. In this work, we propose an approach that leverages a pre-trained Vision Transformer (ViT) with fine-tuning on a small (<500 images), sparse and coarsely labeled (<30% pixels) multi-biome dataset to predict 2D semantic segmentation classes. These classes are fused over time via a novel range-based metric and aggregated into a 3D semantic voxel map. We demonstrate zero-shot out-of-biome 2D semantic segmentation on the Yamaha (52.9 mIoU) and Rellis (55.5 mIoU) datasets along with few-shot coarse sparse labeling with existing data for improved segmentation performance on Yamaha (66.6 mIoU) and Rellis (67.2 mIoU). We further illustrate the feasibility of using a voxel map with a range-based semantic fusion approach to handle common off-road hazards like pop-up hazards, overhangs, and water features.