 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Silence and Noise for Visual Sound Source Localization
Aug 29, 2025Visual sound source localization is a fundamental perception task that aims to detect the location of sounding sources in a video given its audio. Despite recent progress, we identify two shortcomings in current methods: 1) most approaches perform poorly in cases with low audio-visual semantic correspondence such as silence, noise, and offscreen sounds, i.e. in the presence of negative audio; and 2) most prior evaluations are limited to positive cases, where both datasets and metrics convey scenarios with a single visible sound source in the scene. To address this, we introduce three key contributions. First, we propose a new training strategy that incorporates silence and noise, which improves performance in positive cases, while being more robust against negative sounds. Our resulting self-supervised model, SSL-SaN, achieves state-of-the-art performance compared to other self-supervised models, both in sound localization and cross-modal retrieval. Second, we propose a new metric that quantifies the trade-off between alignment and separability of auditory and visual features across positive and negative audio-visual pairs. Third, we present IS3+, an extended and improved version of the IS3 synthetic dataset with negative audio. Our data, metrics and code are available on the https://xavijuanola.github.io/SSL-SaN/.
Musical Source Separation of Brazilian Percussion
Mar 06, 2025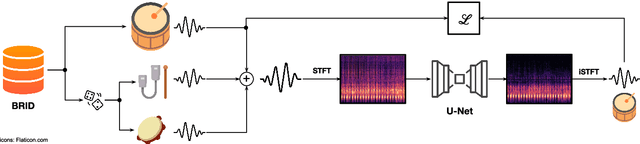
Musical source separation (MSS) has recently seen a big breakthrough in separating instruments from a mixture in the context of Western music, but research on non-Western instruments is still limited due to a lack of data. In this demo, we use an existing dataset of Brazilian sama percussion to create artificial mixtures for training a U-Net model to separate the surdo drum, a traditional instrument in samba. Despite limited training data, the model effectively isolates the surdo, given the drum's repetitive patterns and its characteristic low-pitched timbre. These results suggest that MSS systems can be successfully harnessed to work in more culturally-inclusive scenarios without the need of collecting extensive amounts of data.
Tempo vs. Pitch: understanding self-supervised tempo estimation
Apr 14, 2023


Self-supervision methods learn representations by solving pretext tasks that do not require human-generated labels, alleviating the need for time-consuming annotations. These methods have been applied in computer vision, natural language processing, environmental sound analysis, and recently in music information retrieval, e.g. for pitch estimation. Particularly in the context of music, there are few insights about the fragility of these models regarding different distributions of data, and how they could be mitigated. In this paper, we explore these questions by dissecting a self-supervised model for pitch estimation adapted for tempo estimation via rigorous experimentation with synthetic data. Specifically, we study the relationship between the input representation and data distribution for self-supervised tempo estimation.