 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Local Explanations for Machine Listening
May 15, 2020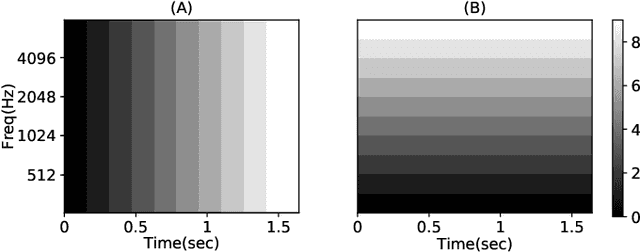
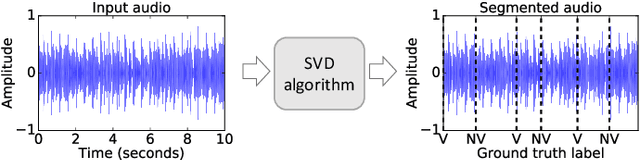


One way to analyse the behaviour of machine learning models is through local explanations that highlight input features that maximally influence model predictions. Sensitivity analysis, which involves analysing the effect of input perturbations on model predictions, is one of the methods to generate local explanations. Meaningful input perturbations are essential for generating reliable explanations, but there exists limited work on what such perturbations are and how to perform them. This work investigates these questions in the context of machine listening models that analyse audio. Specifically, we use a state-of-the-art deep singing voice detection (SVD) model to analyse whether explanations from SoundLIME (a local explanation method) are sensitive to how the method perturbs model inputs. The results demonstrate that SoundLIME explanations are sensitive to the content in the occluded input regions. We further propose and demonstrate a novel method for quantitatively identifying suitable content type(s) for reliably occluding inputs of machine listening models. The results for the SVD model suggest that the average magnitude of input mel-spectrogram bins is the most suitable content type for temporal explanations.
GAN-based Generation and Automatic Selection of Explanations for Neural Networks
Apr 27, 2019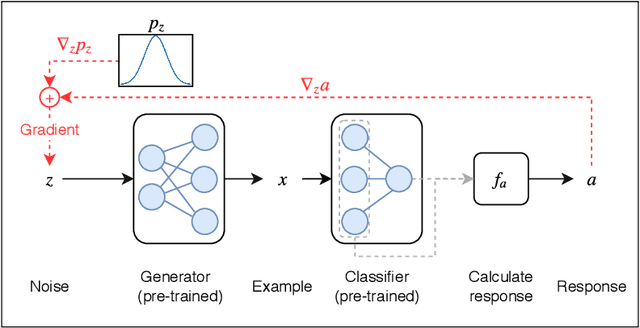
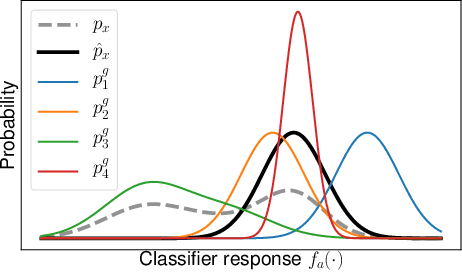
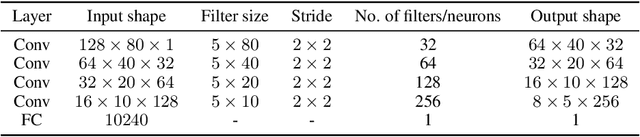
One way to interpret trained deep neural networks (DNNs) is by inspecting characteristics that neurons in the model respond to, such as by iteratively optimising the model input (e.g., an image) to maximally activate specific neurons. However, this requires a careful selection of hyper-parameters to generate interpretable examples for each neuron of interest, and current methods rely on a manual, qualitative evaluation of each setting, which is prohibitively slow. We introduce a new metric that uses Fr\'echet Inception Distance (FID) to encourage similarity between model activations for real and generated data. This provides an efficient way to evaluate a set of generated examples for each setting of hyper-parameters. We also propose a novel GAN-based method for generating explanations that enables an efficient search through the input space and imposes a strong prior favouring realistic outputs. We apply our approach to a classification model trained to predict whether a music audio recording contains singing voice. Our results suggest that this proposed metric successfully selects hyper-parameters leading to interpretable examples, avoiding the need for manual evaluation. Moreover, we see that examples synthesised to maximise or minimise the predicted probability of singing voice presence exhibit vocal or non-vocal characteristics, respectively, suggesting that our approach is able to generate suitable explanations for understanding concepts learned by a neural network.
* 8 pages plus references and appendix. Accepted at the ICLR 2019 Workshop "Safe Machine Learning: Specification, Robustness and Assurance". Camera-ready version. v2: Corrected page header
The "Horse'' Inside: Seeking Causes Behind the Behaviours of Music Content Analysis Systems
Jun 09, 2016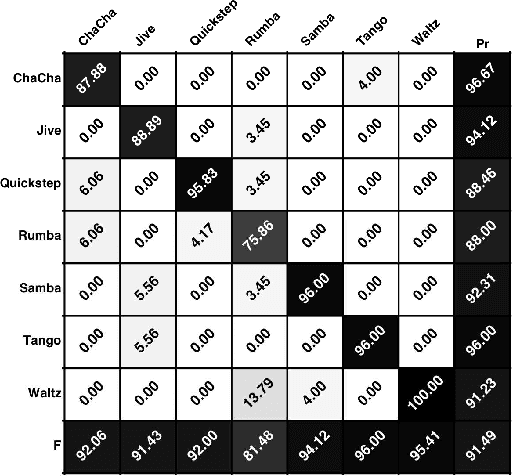
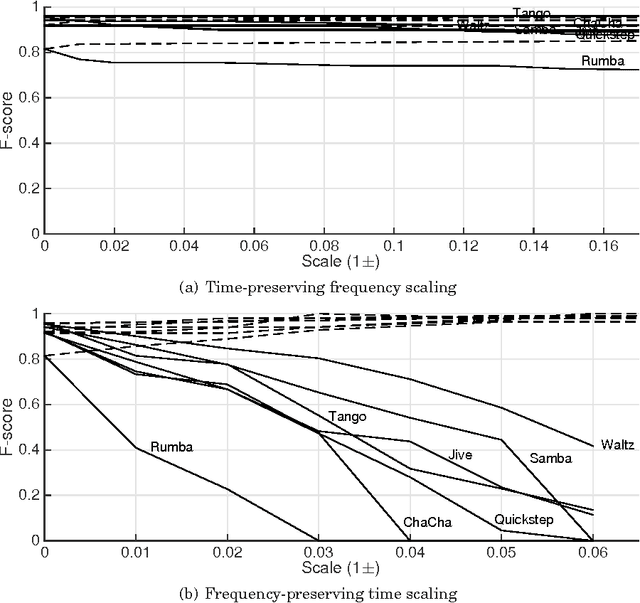
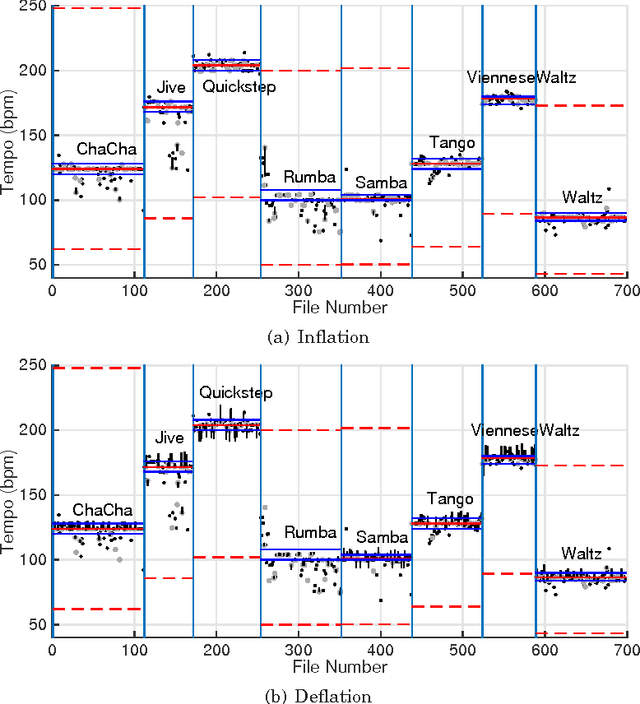
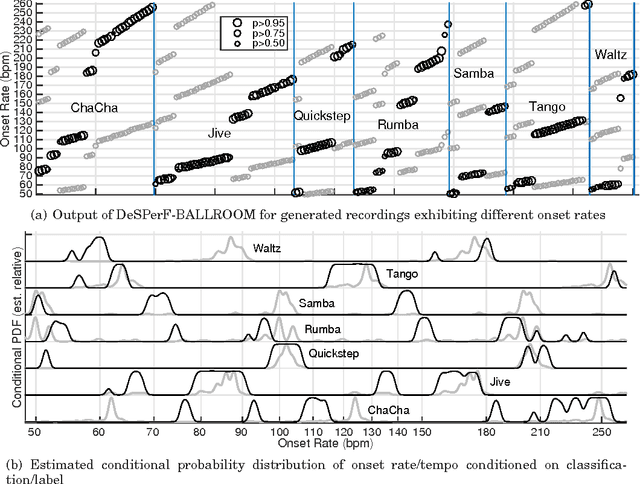
Building systems that possess the sensitivity and intelligence to identify and describe high-level attributes in music audio signals continues to be an elusive goal, but one that surely has broad and deep implications for a wide variety of applications. Hundreds of papers have so far been published toward this goal, and great progress appears to have been made. Some systems produce remarkable accuracies at recognising high-level semantic concepts, such as music style, genre and mood. However, it might be that these numbers do not mean what they seem. In this paper, we take a state-of-the-art music content analysis system and investigate what causes it to achieve exceptionally high performance in a benchmark music audio dataset. We dissect the system to understand its operation, determine its sensitivities and limitations, and predict the kinds of knowledge it could and could not possess about music. We perform a series of experiments to illuminate what the system has actually learned to do, and to what extent it is performing the intended music listening task. Our results demonstrate how the initial manifestation of music intelligence in this state-of-the-art can be deceptive. Our work provides constructive directions toward developing music content analysis systems that can address the music information and creation needs of real-world users.
Music transcription modelling and composition using deep learning
Apr 29, 2016



We apply deep learning methods, specifically long short-term memory (LSTM) networks, to music transcription modelling and composition. We build and train LSTM networks using approximately 23,000 music transcriptions expressed with a high-level vocabulary (ABC notation), and use them to generate new transcriptions. Our practical aim is to create music transcription models useful in particular contexts of music composition. We present results from three perspectives: 1) at the population level, comparing descriptive statistics of the set of training transcriptions and generated transcriptions; 2) at the individual level, examining how a generated transcription reflects the conventions of a music practice in the training transcriptions (Celtic folk); 3) at the application level, using the system for idea generation in music composition. We make our datasets, software and sound examples open and available: \url{https://github.com/IraKorshunova/folk-rnn}.
Deep Learning and Music Adversaries
Jul 16, 2015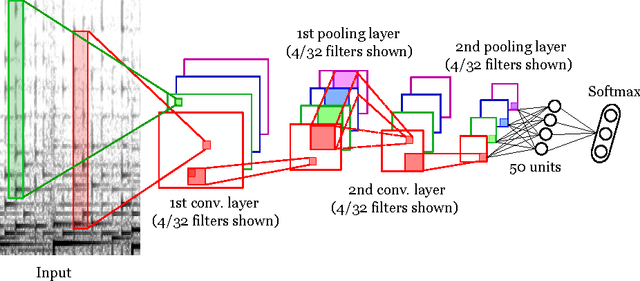
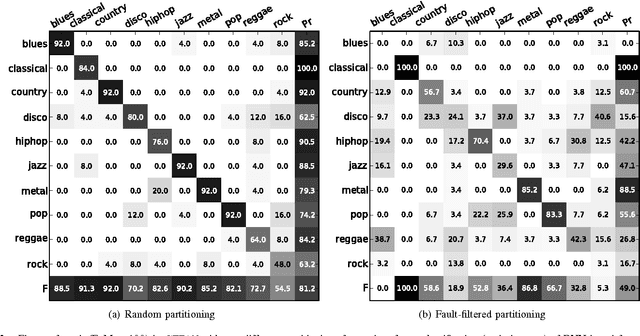

An adversary is essentially an algorithm intent on making a classification system perform in some particular way given an input, e.g., increase the probability of a false negative. Recent work builds adversaries for deep learning systems applied to image object recognition, which exploits the parameters of the system to find the minimal perturbation of the input image such that the network misclassifies it with high confidence. We adapt this approach to construct and deploy an adversary of deep learning systems applied to music content analysis. In our case, however, the input to the systems is magnitude spectral frames, which requires special care in order to produce valid input audio signals from network-derived perturbations. For two different train-test partitionings of two benchmark datasets, and two different deep architectures, we find that this adversary is very effective in defeating the resulting systems. We find the convolutional networks are more robust, however, compared with systems based on a majority vote over individually classified audio frames. Furthermore, we integrate the adversary into the training of new deep systems, but do not find that this improves their resilience against the same adversary.