 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning and Music Adversaries
Paper and Code
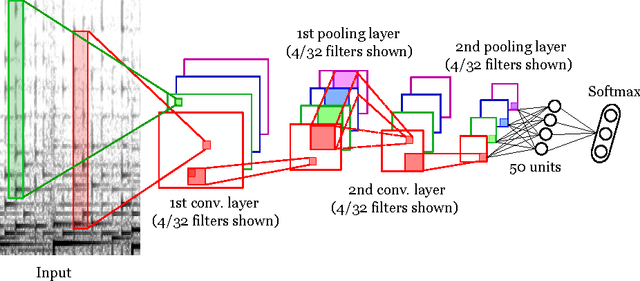
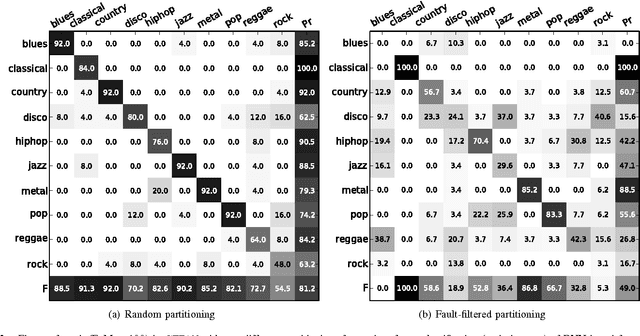

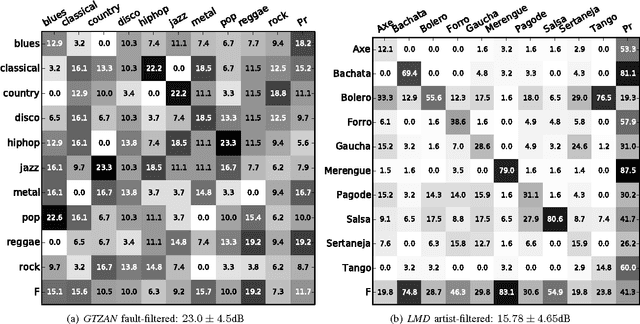
An adversary is essentially an algorithm intent on making a classification system perform in some particular way given an input, e.g., increase the probability of a false negative. Recent work builds adversaries for deep learning systems applied to image object recognition, which exploits the parameters of the system to find the minimal perturbation of the input image such that the network misclassifies it with high confidence. We adapt this approach to construct and deploy an adversary of deep learning systems applied to music content analysis. In our case, however, the input to the systems is magnitude spectral frames, which requires special care in order to produce valid input audio signals from network-derived perturbations. For two different train-test partitionings of two benchmark datasets, and two different deep architectures, we find that this adversary is very effective in defeating the resulting systems. We find the convolutional networks are more robust, however, compared with systems based on a majority vote over individually classified audio frames. Furthermore, we integrate the adversary into the training of new deep systems, but do not find that this improves their resilience against the same adversary.