 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe "Horse'' Inside: Seeking Causes Behind the Behaviours of Music Content Analysis Systems
Paper and Code
Jun 09, 2016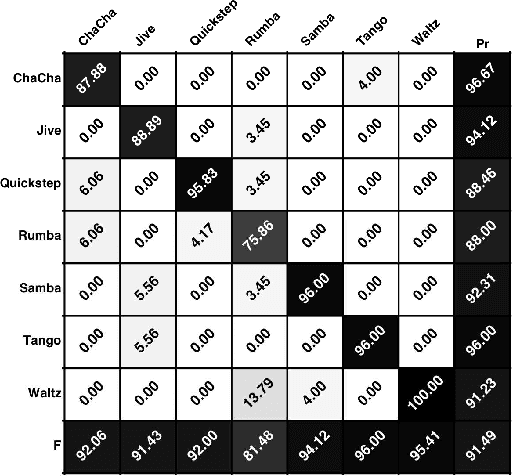
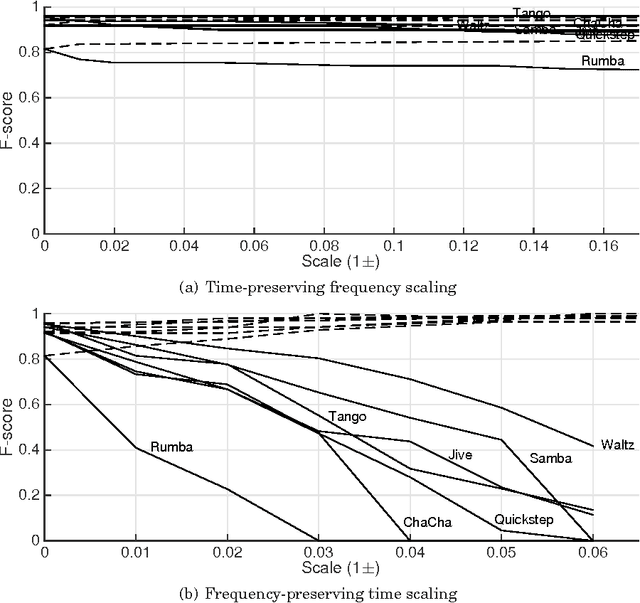
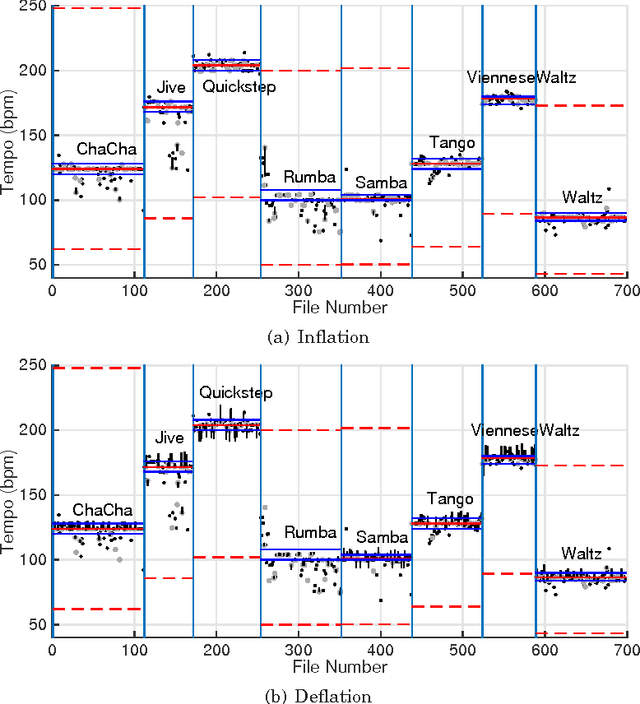
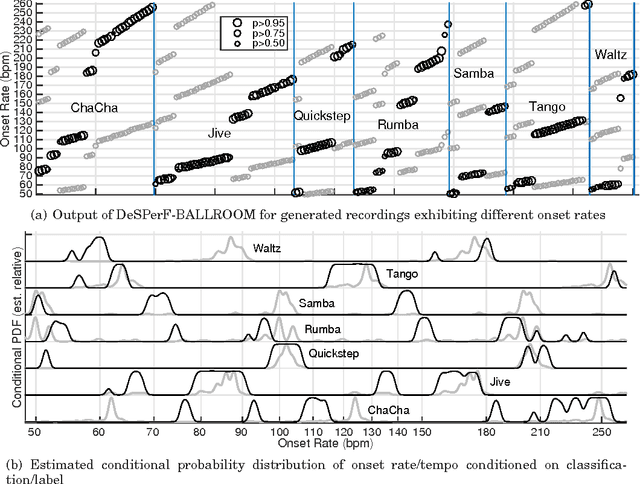
Building systems that possess the sensitivity and intelligence to identify and describe high-level attributes in music audio signals continues to be an elusive goal, but one that surely has broad and deep implications for a wide variety of applications. Hundreds of papers have so far been published toward this goal, and great progress appears to have been made. Some systems produce remarkable accuracies at recognising high-level semantic concepts, such as music style, genre and mood. However, it might be that these numbers do not mean what they seem. In this paper, we take a state-of-the-art music content analysis system and investigate what causes it to achieve exceptionally high performance in a benchmark music audio dataset. We dissect the system to understand its operation, determine its sensitivities and limitations, and predict the kinds of knowledge it could and could not possess about music. We perform a series of experiments to illuminate what the system has actually learned to do, and to what extent it is performing the intended music listening task. Our results demonstrate how the initial manifestation of music intelligence in this state-of-the-art can be deceptive. Our work provides constructive directions toward developing music content analysis systems that can address the music information and creation needs of real-world users.