 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned complex masks for multi-instrument source separation
Paper and Code
Mar 23, 2021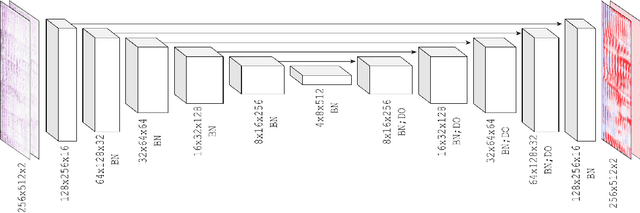
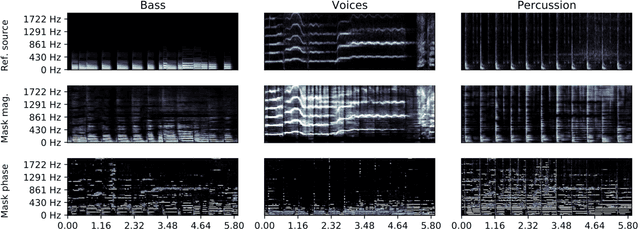
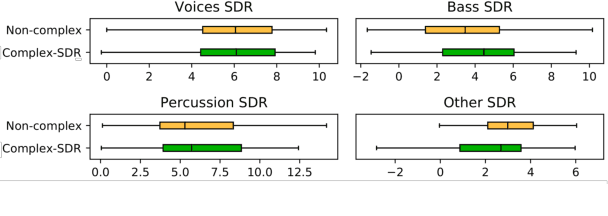
Music source separation in the time-frequency domain is commonly achieved by applying a soft or binary mask to the magnitude component of (complex) spectrograms. The phase component is usually not estimated, but instead copied from the mixture and applied to the magnitudes of the estimated isolated sources. While this method has several practical advantages, it imposes an upper bound on the performance of the system, where the estimated isolated sources inherently exhibit audible "phase artifacts". In this paper we address these shortcomings by directly estimating masks in the complex domain, extending recent work from the speech enhancement literature. The method is particularly well suited for multi-instrument musical source separation since residual phase artifacts are more pronounced for spectrally overlapping instrument sources, a common scenario in music. We show that complex masks result in better separation than masks that operate solely on the magnitude component.