 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-agnostic clean-label backdoor mitigation in cybersecurity environments
Jul 11, 2024



The training phase of machine learning models is a delicate step, especially in cybersecurity contexts. Recent research has surfaced a series of insidious training-time attacks that inject backdoors in models designed for security classification tasks without altering the training labels. With this work, we propose new techniques that leverage insights in cybersecurity threat models to effectively mitigate these clean-label poisoning attacks, while preserving the model utility. By performing density-based clustering on a carefully chosen feature subspace, and progressively isolating the suspicious clusters through a novel iterative scoring procedure, our defensive mechanism can mitigate the attacks without requiring many of the common assumptions in the existing backdoor defense literature. To show the generality of our proposed mitigation, we evaluate it on two clean-label model-agnostic attacks on two different classic cybersecurity data modalities: network flows classification and malware classification, using gradient boosting and neural network models.
ScatterUQ: Interactive Uncertainty Visualizations for Multiclass Deep Learning Problems
Aug 08, 2023Recently, uncertainty-aware deep learning methods for multiclass labeling problems have been developed that provide calibrated class prediction probabilities and out-of-distribution (OOD) indicators, letting machine learning (ML) consumers and engineers gauge a model's confidence in its predictions. However, this extra neural network prediction information is challenging to scalably convey visually for arbitrary data sources under multiple uncertainty contexts. To address these challenges, we present ScatterUQ, an interactive system that provides targeted visualizations to allow users to better understand model performance in context-driven uncertainty settings. ScatterUQ leverages recent advances in distance-aware neural networks, together with dimensionality reduction techniques, to construct robust, 2-D scatter plots explaining why a model predicts a test example to be (1) in-distribution and of a particular class, (2) in-distribution but unsure of the class, and (3) out-of-distribution. ML consumers and engineers can visually compare the salient features of test samples with training examples through the use of a ``hover callback'' to understand model uncertainty performance and decide follow up courses of action. We demonstrate the effectiveness of ScatterUQ to explain model uncertainty for a multiclass image classification on a distance-aware neural network trained on Fashion-MNIST and tested on Fashion-MNIST (in distribution) and MNIST digits (out of distribution), as well as a deep learning model for a cyber dataset. We quantitatively evaluate dimensionality reduction techniques to optimize our contextually driven UQ visualizations. Our results indicate that the ScatterUQ system should scale to arbitrary, multiclass datasets. Our code is available at https://github.com/mit-ll-responsible-ai/equine-webapp
Poisoning Network Flow Classifiers
Jun 02, 2023



As machine learning (ML) classifiers increasingly oversee the automated monitoring of network traffic, studying their resilience against adversarial attacks becomes critical. This paper focuses on poisoning attacks, specifically backdoor attacks, against network traffic flow classifiers. We investigate the challenging scenario of clean-label poisoning where the adversary's capabilities are constrained to tampering only with the training data - without the ability to arbitrarily modify the training labels or any other component of the training process. We describe a trigger crafting strategy that leverages model interpretability techniques to generate trigger patterns that are effective even at very low poisoning rates. Finally, we design novel strategies to generate stealthy triggers, including an approach based on generative Bayesian network models, with the goal of minimizing the conspicuousness of the trigger, and thus making detection of an ongoing poisoning campaign more challenging. Our findings provide significant insights into the feasibility of poisoning attacks on network traffic classifiers used in multiple scenarios, including detecting malicious communication and application classification.
Extensible Machine Learning for Encrypted Network Traffic Application Labeling via Uncertainty Quantification
May 11, 2022
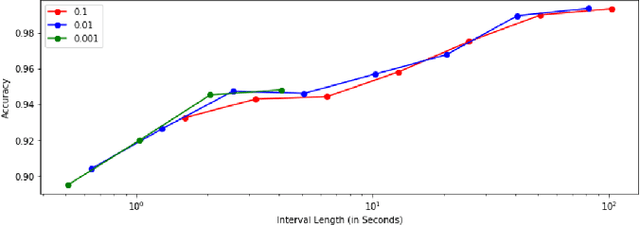
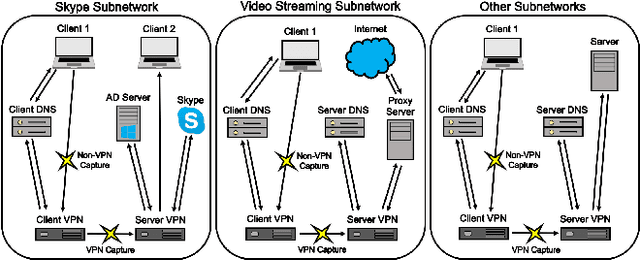
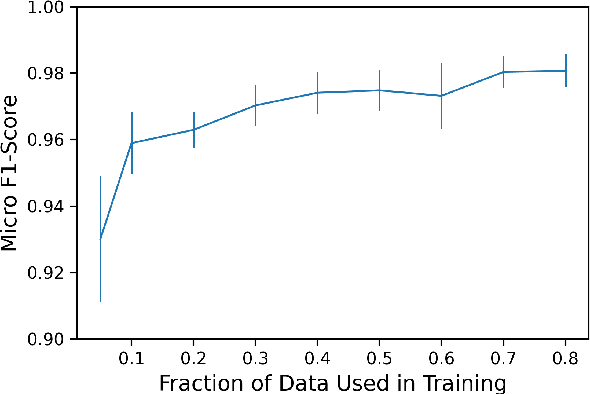
With the increasing prevalence of encrypted network traffic, cyber security analysts have been turning to machine learning (ML) techniques to elucidate the traffic on their networks. However, ML models can become stale as known traffic features can shift between networks and as new traffic emerges that is outside of the distribution of the training set. In order to reliably adapt in this dynamic environment, ML models must additionally provide contextualized uncertainty quantification to their predictions, which has received little attention in the cyber security domain. Uncertainty quantification is necessary both to signal when the model is uncertain about which class to choose in its label assignment and when the traffic is not likely to belong to any pre-trained classes. We present a new, public dataset of network traffic that includes labeled, Virtual Private Network (VPN)-encrypted network traffic generated by 10 applications and corresponding to 5 application categories. We also present an ML framework that is designed to rapidly train with modest data requirements and provide both calibrated, predictive probabilities as well as an interpretable ``out-of-distribution'' (OOD) score to flag novel traffic samples. We describe how to compute a calibrated OOD score from p-values of the so-called relative Mahalanobis distance. We demonstrate that our framework achieves an F1 score of 0.98 on our dataset and that it can extend to an enterprise network by testing the model: (1) on data from similar applications, (2) on dissimilar application traffic from an existing category, and (3) on application traffic from a new category. The model correctly flags uncertain traffic and, upon retraining, accurately incorporates the new data. We additionally demonstrate good performance (F1 score of 0.97) when packet sizes are made to be uniform, as occurs for certain encryption protocols.