 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScatterUQ: Interactive Uncertainty Visualizations for Multiclass Deep Learning Problems
Aug 08, 2023Recently, uncertainty-aware deep learning methods for multiclass labeling problems have been developed that provide calibrated class prediction probabilities and out-of-distribution (OOD) indicators, letting machine learning (ML) consumers and engineers gauge a model's confidence in its predictions. However, this extra neural network prediction information is challenging to scalably convey visually for arbitrary data sources under multiple uncertainty contexts. To address these challenges, we present ScatterUQ, an interactive system that provides targeted visualizations to allow users to better understand model performance in context-driven uncertainty settings. ScatterUQ leverages recent advances in distance-aware neural networks, together with dimensionality reduction techniques, to construct robust, 2-D scatter plots explaining why a model predicts a test example to be (1) in-distribution and of a particular class, (2) in-distribution but unsure of the class, and (3) out-of-distribution. ML consumers and engineers can visually compare the salient features of test samples with training examples through the use of a ``hover callback'' to understand model uncertainty performance and decide follow up courses of action. We demonstrate the effectiveness of ScatterUQ to explain model uncertainty for a multiclass image classification on a distance-aware neural network trained on Fashion-MNIST and tested on Fashion-MNIST (in distribution) and MNIST digits (out of distribution), as well as a deep learning model for a cyber dataset. We quantitatively evaluate dimensionality reduction techniques to optimize our contextually driven UQ visualizations. Our results indicate that the ScatterUQ system should scale to arbitrary, multiclass datasets. Our code is available at https://github.com/mit-ll-responsible-ai/equine-webapp
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022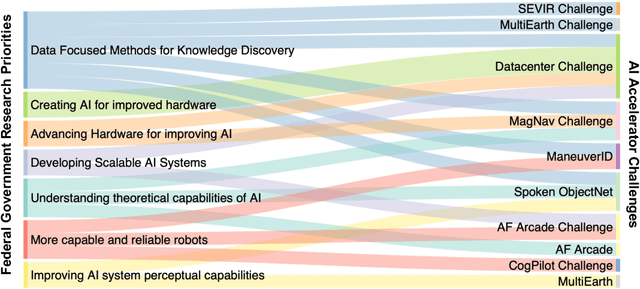

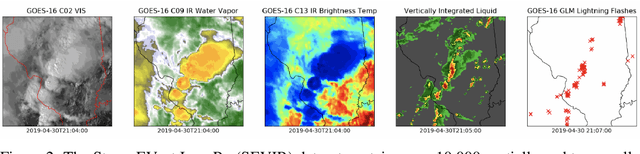
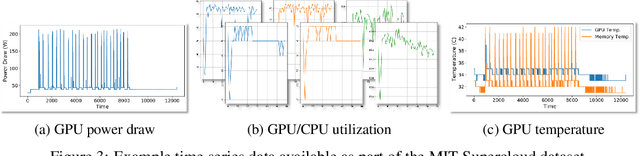
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
Extensible Machine Learning for Encrypted Network Traffic Application Labeling via Uncertainty Quantification
May 11, 2022
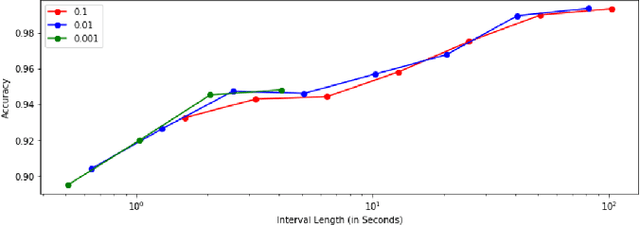
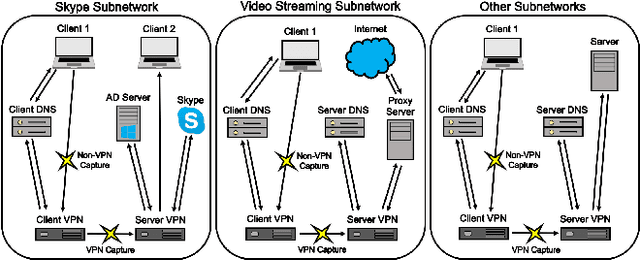
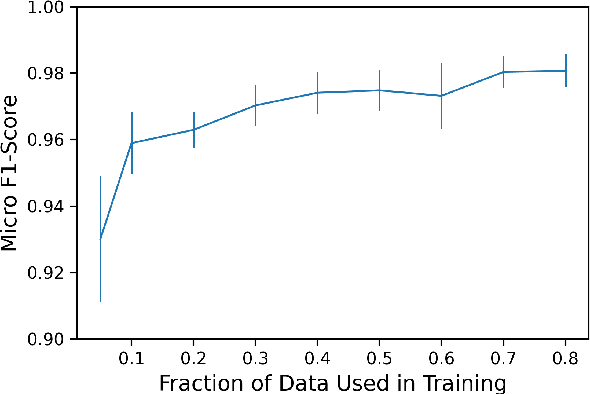
With the increasing prevalence of encrypted network traffic, cyber security analysts have been turning to machine learning (ML) techniques to elucidate the traffic on their networks. However, ML models can become stale as known traffic features can shift between networks and as new traffic emerges that is outside of the distribution of the training set. In order to reliably adapt in this dynamic environment, ML models must additionally provide contextualized uncertainty quantification to their predictions, which has received little attention in the cyber security domain. Uncertainty quantification is necessary both to signal when the model is uncertain about which class to choose in its label assignment and when the traffic is not likely to belong to any pre-trained classes. We present a new, public dataset of network traffic that includes labeled, Virtual Private Network (VPN)-encrypted network traffic generated by 10 applications and corresponding to 5 application categories. We also present an ML framework that is designed to rapidly train with modest data requirements and provide both calibrated, predictive probabilities as well as an interpretable ``out-of-distribution'' (OOD) score to flag novel traffic samples. We describe how to compute a calibrated OOD score from p-values of the so-called relative Mahalanobis distance. We demonstrate that our framework achieves an F1 score of 0.98 on our dataset and that it can extend to an enterprise network by testing the model: (1) on data from similar applications, (2) on dissimilar application traffic from an existing category, and (3) on application traffic from a new category. The model correctly flags uncertain traffic and, upon retraining, accurately incorporates the new data. We additionally demonstrate good performance (F1 score of 0.97) when packet sizes are made to be uniform, as occurs for certain encryption protocols.
Proceedings of the Artificial Intelligence for Cyber Security (AICS) Workshop at AAAI 2022
Mar 01, 2022The workshop will focus on the application of AI to problems in cyber security. Cyber systems generate large volumes of data, utilizing this effectively is beyond human capabilities. Additionally, adversaries continue to develop new attacks. Hence, AI methods are required to understand and protect the cyber domain. These challenges are widely studied in enterprise networks, but there are many gaps in research and practice as well as novel problems in other domains. In general, AI techniques are still not widely adopted in the real world. Reasons include: (1) a lack of certification of AI for security, (2) a lack of formal study of the implications of practical constraints (e.g., power, memory, storage) for AI systems in the cyber domain, (3) known vulnerabilities such as evasion, poisoning attacks, (4) lack of meaningful explanations for security analysts, and (5) lack of analyst trust in AI solutions. There is a need for the research community to develop novel solutions for these practical issues.