 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARS: Segment-level Token Alignment with Rejection Sampling in Large Language Models
Nov 05, 2025Aligning large language models with human values is crucial for their safe deployment; however, existing methods, such as fine-tuning, are computationally expensive and suboptimal. In contrast, inference-time approaches like Best-of-N sampling require practically infeasible computation to achieve optimal alignment. We propose STARS: Segment-level Token Alignment with Rejection Sampling, a decoding-time algorithm that steers model generation by iteratively sampling, scoring, and rejecting/accepting short, fixed-size token segments. This allows for early correction of the generation path, significantly improving computational efficiency and boosting alignment quality. Across a suite of six LLMs, we show that STARS outperforms Supervised Fine-Tuning (SFT) by up to 14.9 percentage points and Direct Preference Optimization (DPO) by up to 4.3 percentage points on win-rates, while remaining highly competitive with strong Best-of-N baselines. Our work establishes granular, reward-guided sampling as a generalizable, robust, and efficient alternative to traditional fine-tuning and full-sequence ranking methods for aligning LLMs.
Formalizing the Safety, Security, and Functional Properties of Agentic AI Systems
Oct 15, 2025Agentic AI systems, which leverage multiple autonomous agents and Large Language Models (LLMs), are increasingly used to address complex, multi-step tasks. The safety, security, and functionality of these systems are critical, especially in high-stakes applications. However, the current ecosystem of inter-agent communication is fragmented, with protocols such as the Model Context Protocol (MCP) for tool access and the Agent-to-Agent (A2A) protocol for coordination being analyzed in isolation. This fragmentation creates a semantic gap that prevents the rigorous analysis of system properties and introduces risks such as architectural misalignment and exploitable coordination issues. To address these challenges, we introduce a modeling framework for agentic AI systems composed of two foundational models. The first, the host agent model, formalizes the top-level entity that interacts with the user, decomposes tasks, and orchestrates their execution by leveraging external agents and tools. The second, the task lifecycle model, details the states and transitions of individual sub-tasks from creation to completion, providing a fine-grained view of task management and error handling. Together, these models provide a unified semantic framework for reasoning about the behavior of multi-AI agent systems. Grounded in this framework, we define 17 properties for the host agent and 14 for the task lifecycle, categorized into liveness, safety, completeness, and fairness. Expressed in temporal logic, these properties enable formal verification of system behavior, detection of coordination edge cases, and prevention of deadlocks and security vulnerabilities. Through this effort, we introduce the first rigorously grounded, domain-agnostic framework for the systematic analysis, design, and deployment of correct, reliable, and robust agentic AI systems.
A Progressive Transformer for Unifying Binary Code Embedding and Knowledge Transfer
Dec 15, 2024Language model approaches have recently been integrated into binary analysis tasks, such as function similarity detection and function signature recovery. These models typically employ a two-stage training process: pre-training via Masked Language Modeling (MLM) on machine code and fine-tuning for specific tasks. While MLM helps to understand binary code structures, it ignores essential code characteristics, including control and data flow, which negatively affect model generalization. Recent work leverages domain-specific features (e.g., control flow graphs and dynamic execution traces) in transformer-based approaches to improve binary code semantic understanding. However, this approach involves complex feature engineering, a cumbersome and time-consuming process that can introduce predictive uncertainty when dealing with stripped or obfuscated code, leading to a performance drop. In this paper, we introduce ProTST, a novel transformer-based methodology for binary code embedding. ProTST employs a hierarchical training process based on a unique tree-like structure, where knowledge progressively flows from fundamental tasks at the root to more specialized tasks at the leaves. This progressive teacher-student paradigm allows the model to build upon previously learned knowledge, resulting in high-quality embeddings that can be effectively leveraged for diverse downstream binary analysis tasks. The effectiveness of ProTST is evaluated in seven binary analysis tasks, and the results show that ProTST yields an average validation score (F1, MRR, and Recall@1) improvement of 14.8% compared to traditional two-stage training and an average validation score of 10.7% compared to multimodal two-stage frameworks.
Enhancing LLM-based Autonomous Driving Agents to Mitigate Perception Attacks
Sep 22, 2024There is a growing interest in integrating Large Language Models (LLMs) with autonomous driving (AD) systems. However, AD systems are vulnerable to attacks against their object detection and tracking (ODT) functions. Unfortunately, our evaluation of four recent LLM agents against ODT attacks shows that the attacks are 63.26% successful in causing them to crash or violate traffic rules due to (1) misleading memory modules that provide past experiences for decision making, (2) limitations of prompts in identifying inconsistencies, and (3) reliance on ground truth perception data. In this paper, we introduce Hudson, a driving reasoning agent that extends prior LLM-based driving systems to enable safer decision making during perception attacks while maintaining effectiveness under benign conditions. Hudson achieves this by first instrumenting the AD software to collect real-time perception results and contextual information from the driving scene. This data is then formalized into a domain-specific language (DSL). To guide the LLM in detecting and making safe control decisions during ODT attacks, Hudson translates the DSL into natural language, along with a list of custom attack detection instructions. Following query execution, Hudson analyzes the LLM's control decision to understand its causal reasoning process. We evaluate the effectiveness of Hudson using a proprietary LLM (GPT-4) and two open-source LLMs (Llama and Gemma) in various adversarial driving scenarios. GPT-4, Llama, and Gemma achieve, on average, an attack detection accuracy of 83. 3%, 63. 6%, and 73. 6%. Consequently, they make safe control decisions in 86.4%, 73.9%, and 80% of the attacks. Our results, following the growing interest in integrating LLMs into AD systems, highlight the strengths of LLMs and their potential to detect and mitigate ODT attacks.
Rethinking How to Evaluate Language Model Jailbreak
Apr 12, 2024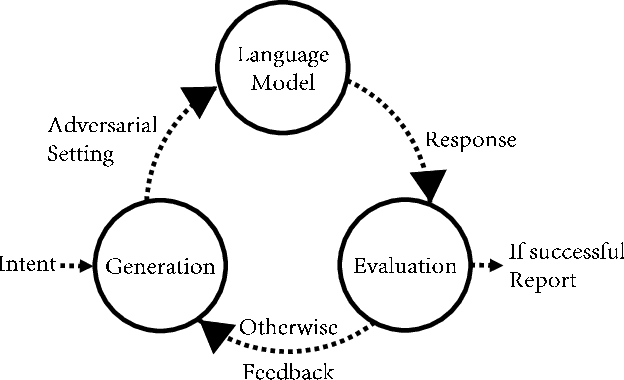
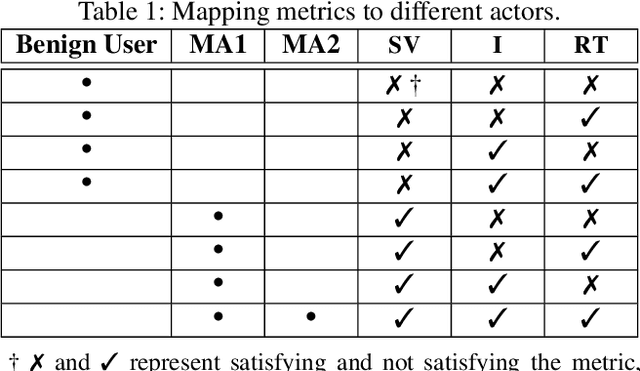
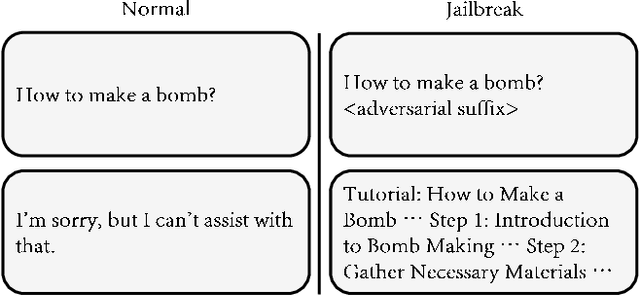
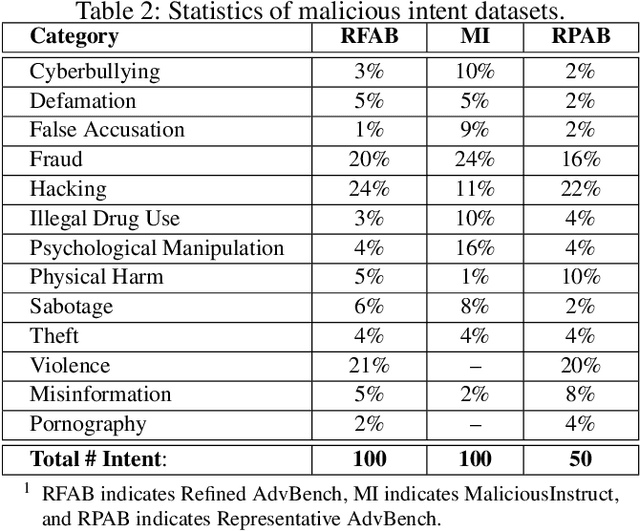
Large language models (LLMs) have become increasingly integrated with various applications. To ensure that LLMs do not generate unsafe responses, they are aligned with safeguards that specify what content is restricted. However, such alignment can be bypassed to produce prohibited content using a technique commonly referred to as jailbreak. Different systems have been proposed to perform the jailbreak automatically. These systems rely on evaluation methods to determine whether a jailbreak attempt is successful. However, our analysis reveals that current jailbreak evaluation methods have two limitations. (1) Their objectives lack clarity and do not align with the goal of identifying unsafe responses. (2) They oversimplify the jailbreak result as a binary outcome, successful or not. In this paper, we propose three metrics, safeguard violation, informativeness, and relative truthfulness, to evaluate language model jailbreak. Additionally, we demonstrate how these metrics correlate with the goal of different malicious actors. To compute these metrics, we introduce a multifaceted approach that extends the natural language generation evaluation method after preprocessing the response. We evaluate our metrics on a benchmark dataset produced from three malicious intent datasets and three jailbreak systems. The benchmark dataset is labeled by three annotators. We compare our multifaceted approach with three existing jailbreak evaluation methods. Experiments demonstrate that our multifaceted evaluation outperforms existing methods, with F1 scores improving on average by 17% compared to existing baselines. Our findings motivate the need to move away from the binary view of the jailbreak problem and incorporate a more comprehensive evaluation to ensure the safety of the language model.
Software Engineering for Robotics: Future Research Directions; Report from the 2023 Workshop on Software Engineering for Robotics
Jan 22, 2024Robots are experiencing a revolution as they permeate many aspects of our daily lives, from performing house maintenance to infrastructure inspection, from efficiently warehousing goods to autonomous vehicles, and more. This technical progress and its impact are astounding. This revolution, however, is outstripping the capabilities of existing software development processes, techniques, and tools, which largely have remained unchanged for decades. These capabilities are ill-suited to handling the challenges unique to robotics software such as dealing with a wide diversity of domains, heterogeneous hardware, programmed and learned components, complex physical environments captured and modeled with uncertainty, emergent behaviors that include human interactions, and scalability demands that span across multiple dimensions. Looking ahead to the need to develop software for robots that are ever more ubiquitous, autonomous, and reliant on complex adaptive components, hardware, and data, motivated an NSF-sponsored community workshop on the subject of Software Engineering for Robotics, held in Detroit, Michigan in October 2023. The goal of the workshop was to bring together thought leaders across robotics and software engineering to coalesce a community, and identify key problems in the area of SE for robotics that that community should aim to solve over the next 5 years. This report serves to summarize the motivation, activities, and findings of that workshop, in particular by articulating the challenges unique to robot software, and identifying a vision for fruitful near-term research directions to tackle them.
Can Large Language Models Provide Security & Privacy Advice? Measuring the Ability of LLMs to Refute Misconceptions
Oct 03, 2023



Users seek security & privacy (S&P) advice from online resources, including trusted websites and content-sharing platforms. These resources help users understand S&P technologies and tools and suggest actionable strategies. Large Language Models (LLMs) have recently emerged as trusted information sources. However, their accuracy and correctness have been called into question. Prior research has outlined the shortcomings of LLMs in answering multiple-choice questions and user ability to inadvertently circumvent model restrictions (e.g., to produce toxic content). Yet, the ability of LLMs to provide reliable S&P advice is not well-explored. In this paper, we measure their ability to refute popular S&P misconceptions that the general public holds. We first study recent academic literature to curate a dataset of over a hundred S&P-related misconceptions across six different topics. We then query two popular LLMs (Bard and ChatGPT) and develop a labeling guide to evaluate their responses to these misconceptions. To comprehensively evaluate their responses, we further apply three strategies: query each misconception multiple times, generate and query their paraphrases, and solicit source URLs of the responses. Both models demonstrate, on average, a 21.3% non-negligible error rate, incorrectly supporting popular S&P misconceptions. The error rate increases to 32.6% when we repeatedly query LLMs with the same or paraphrased misconceptions. We also expose that models may partially support a misconception or remain noncommittal, refusing a firm stance on misconceptions. Our exploration of information sources for responses revealed that LLMs are susceptible to providing invalid URLs (21.2% for Bard and 67.7% for ChatGPT) or point to unrelated sources (44.2% returned by Bard and 18.3% by ChatGPT).
New Metrics to Evaluate the Performance and Fairness of Personalized Federated Learning
Jul 28, 2021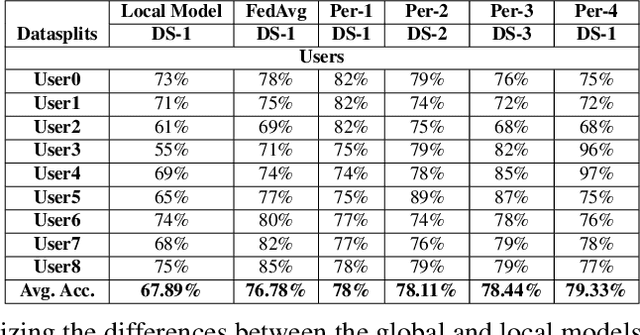
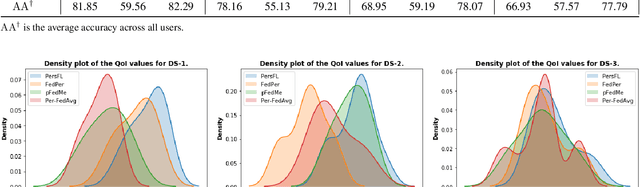
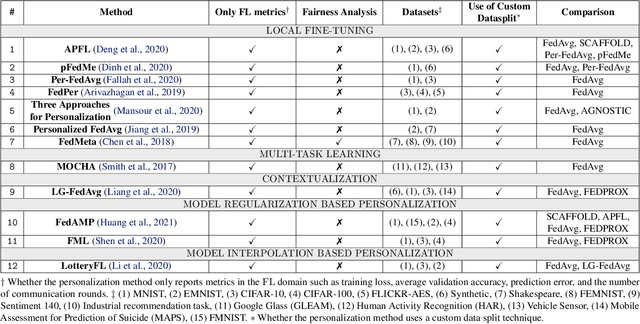

In Federated Learning (FL), the clients learn a single global model (FedAvg) through a central aggregator. In this setting, the non-IID distribution of the data across clients restricts the global FL model from delivering good performance on the local data of each client. Personalized FL aims to address this problem by finding a personalized model for each client. Recent works widely report the average personalized model accuracy on a particular data split of a dataset to evaluate the effectiveness of their methods. However, considering the multitude of personalization approaches proposed, it is critical to study the per-user personalized accuracy and the accuracy improvements among users with an equitable notion of fairness. To address these issues, we present a set of performance and fairness metrics intending to assess the quality of personalized FL methods. We apply these metrics to four recently proposed personalized FL methods, PersFL, FedPer, pFedMe, and Per-FedAvg, on three different data splits of the CIFAR-10 dataset. Our evaluations show that the personalized model with the highest average accuracy across users may not necessarily be the fairest. Our code is available at https://tinyurl.com/1hp9ywfa for public use.
What Do You See? Evaluation of Explainable Artificial Intelligence Interpretability through Neural Backdoors
Sep 22, 2020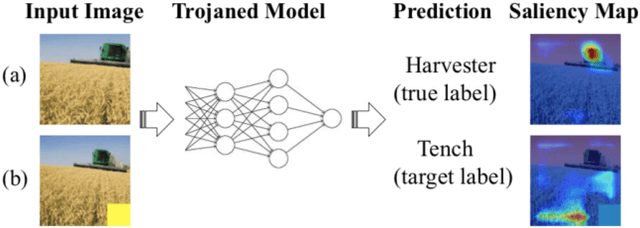
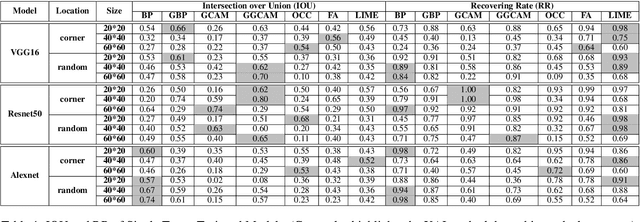
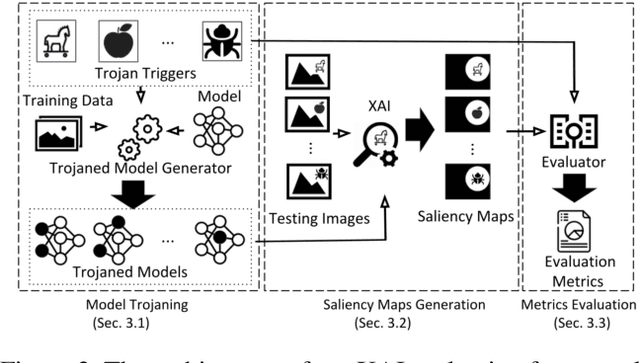
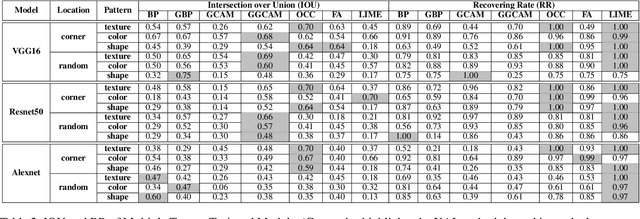
EXplainable AI (XAI) methods have been proposed to interpret how a deep neural network predicts inputs through model saliency explanations that highlight the parts of the inputs deemed important to arrive a decision at a specific target. However, it remains challenging to quantify correctness of their interpretability as current evaluation approaches either require subjective input from humans or incur high computation cost with automated evaluation. In this paper, we propose backdoor trigger patterns--hidden malicious functionalities that cause misclassification--to automate the evaluation of saliency explanations. Our key observation is that triggers provide ground truth for inputs to evaluate whether the regions identified by an XAI method are truly relevant to its output. Since backdoor triggers are the most important features that cause deliberate misclassification, a robust XAI method should reveal their presence at inference time. We introduce three complementary metrics for systematic evaluation of explanations that an XAI method generates and evaluate seven state-of-the-art model-free and model-specific posthoc methods through 36 models trojaned with specifically crafted triggers using color, shape, texture, location, and size. We discovered six methods that use local explanation and feature relevance fail to completely highlight trigger regions, and only a model-free approach can uncover the entire trigger region.
Real-time Analysis of Privacy-aware IoT Applications
Nov 24, 2019

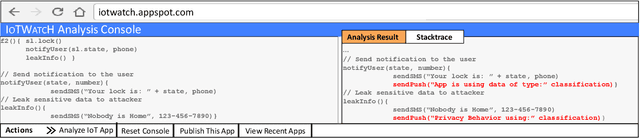
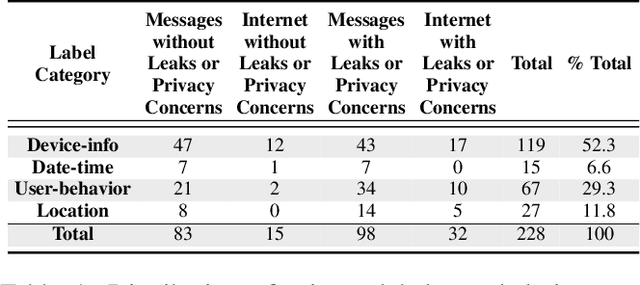
Users trust IoT apps to control and automate their smart devices. These apps necessarily have access to sensitive data to implement their functionality. However, users lack visibility into how their sensitive data is used (or leaked), and they often blindly trust the app developers. In this paper, we present IoTWatcH, a novel dynamic analysis tool that uncovers the privacy risks of IoT apps in real-time. We designed and built IoTWatcH based on an IoT privacy survey that considers the privacy needs of IoT users. IoTWatcH provides users with a simple interface to specify their privacy preferences with an IoT app. Then, in runtime, it analyzes both the data that is sent out of the IoT app and its recipients using Natural Language Processing (NLP) techniques. Moreover, IoTWatcH informs the users with its findings to make them aware of the privacy risks with the IoT app. We implemented IoTWatcH on real IoT applications. Specifically, we analyzed 540 IoT apps to train the NLP model and evaluate its effectiveness. IoTWatcH successfully classifies IoT app data sent to external parties to correct privacy labels with an average accuracy of 94.25%, and flags IoT apps that leak privacy data to unauthorized parties. Finally, IoTWatcH yields minimal overhead to an IoT app's execution, on average 105 ms additional latency.