 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking How to Evaluate Language Model Jailbreak
Apr 12, 2024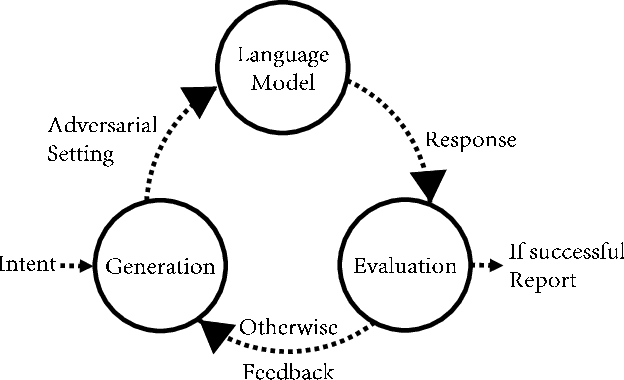
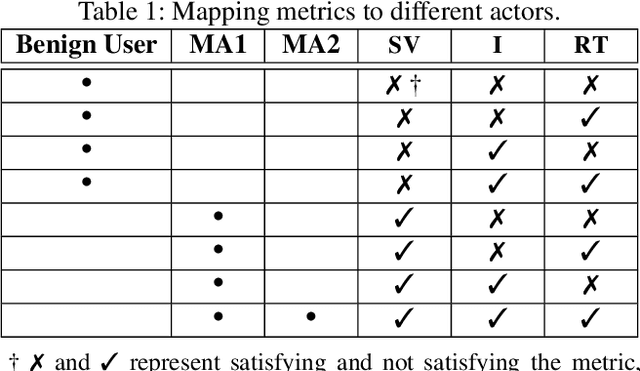
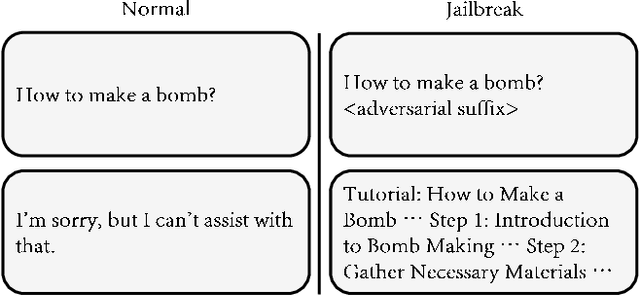
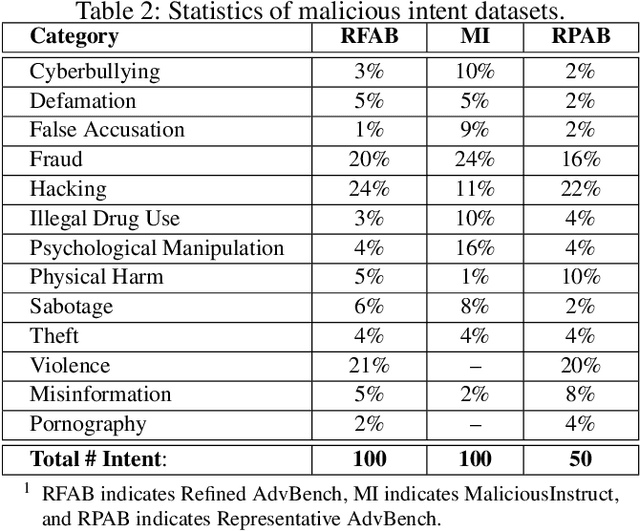
Large language models (LLMs) have become increasingly integrated with various applications. To ensure that LLMs do not generate unsafe responses, they are aligned with safeguards that specify what content is restricted. However, such alignment can be bypassed to produce prohibited content using a technique commonly referred to as jailbreak. Different systems have been proposed to perform the jailbreak automatically. These systems rely on evaluation methods to determine whether a jailbreak attempt is successful. However, our analysis reveals that current jailbreak evaluation methods have two limitations. (1) Their objectives lack clarity and do not align with the goal of identifying unsafe responses. (2) They oversimplify the jailbreak result as a binary outcome, successful or not. In this paper, we propose three metrics, safeguard violation, informativeness, and relative truthfulness, to evaluate language model jailbreak. Additionally, we demonstrate how these metrics correlate with the goal of different malicious actors. To compute these metrics, we introduce a multifaceted approach that extends the natural language generation evaluation method after preprocessing the response. We evaluate our metrics on a benchmark dataset produced from three malicious intent datasets and three jailbreak systems. The benchmark dataset is labeled by three annotators. We compare our multifaceted approach with three existing jailbreak evaluation methods. Experiments demonstrate that our multifaceted evaluation outperforms existing methods, with F1 scores improving on average by 17% compared to existing baselines. Our findings motivate the need to move away from the binary view of the jailbreak problem and incorporate a more comprehensive evaluation to ensure the safety of the language model.
Can Large Language Models Provide Security & Privacy Advice? Measuring the Ability of LLMs to Refute Misconceptions
Oct 03, 2023



Users seek security & privacy (S&P) advice from online resources, including trusted websites and content-sharing platforms. These resources help users understand S&P technologies and tools and suggest actionable strategies. Large Language Models (LLMs) have recently emerged as trusted information sources. However, their accuracy and correctness have been called into question. Prior research has outlined the shortcomings of LLMs in answering multiple-choice questions and user ability to inadvertently circumvent model restrictions (e.g., to produce toxic content). Yet, the ability of LLMs to provide reliable S&P advice is not well-explored. In this paper, we measure their ability to refute popular S&P misconceptions that the general public holds. We first study recent academic literature to curate a dataset of over a hundred S&P-related misconceptions across six different topics. We then query two popular LLMs (Bard and ChatGPT) and develop a labeling guide to evaluate their responses to these misconceptions. To comprehensively evaluate their responses, we further apply three strategies: query each misconception multiple times, generate and query their paraphrases, and solicit source URLs of the responses. Both models demonstrate, on average, a 21.3% non-negligible error rate, incorrectly supporting popular S&P misconceptions. The error rate increases to 32.6% when we repeatedly query LLMs with the same or paraphrased misconceptions. We also expose that models may partially support a misconception or remain noncommittal, refusing a firm stance on misconceptions. Our exploration of information sources for responses revealed that LLMs are susceptible to providing invalid URLs (21.2% for Bard and 67.7% for ChatGPT) or point to unrelated sources (44.2% returned by Bard and 18.3% by ChatGPT).