 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Developing a Pre-Model Safeguard with Draft Models
May 19, 2026Large Language Model (LLM) alignment remains vulnerable to jailbreak attacks that elicit unsafe responses, motivating pre-model and post-model guards. Pre-model guards audit the safety of prompts before invoking target models. However, relying solely on the prompt often leads to high false-negative rates (i.e., jailbreak attacks go undetected). Post-model guards address this issue by auditing both the user prompt and the target model's response. However, they incur a high computational cost, including increased token usage and processing time, because they operate after target model inference. In this paper, we introduce a safeguard design that leverages the transferability of jailbreak attacks to enforce prompt safety before target model inference. We first conduct a systematic study of jailbreak transferability, particularly from LLMs to small language models (SLMs). Through these experiments, we identify key factors influencing transferability. Building on these insights, we observe that responses from smaller draft models reflect the safety implications of those from large target models; \ie given a jailbreak prompt constructed for an LLM, an SLM is likely to be triggered to generate an unaligned response. Based on this observation, our safeguard design leverages speculative inference with SLMs to generate a set of draft responses. It then feeds the original prompt and these drafts into existing guards to predict their safety. We demonstrate that this design reduces the false-negative rate of pre-model guards and offers a low \Efficiency alternative to post-model guards. \textcolor{red}{\bf Notice: This paper contains examples of harmful language.}
RoboJailBench: Benchmarking Adversarial Attacks and Defenses in Embodied Robotic Agents
May 19, 2026Recent advances in Vision-Language Models (VLMs) facilitate a new class of embodied AI systems, where these models are integrated into physical platforms, e.g. robots and autonomous vehicles, to interpret visual scenes and execute natural language commands in diverse environments. Previous research has introduced jailbreak attacks and defenses for embodied AI. Their evaluations, however, rely on ad-hoc datasets, limited metrics, and emphasize attack success while neglecting the trade-off between security and the ability to follow benign commands. Existing benchmarks and evaluation frameworks either target traditional chat-based models or focus on non-adversarial safety evaluation for embodied AI; neither captures the adversarial risks, inputs, consequences, and evaluation criteria necessary for jailbreak attacks in embodied AI systems. In this paper, we address this gap with RoboJailBench, which consists of three core components. We establish a security taxonomy derived from ISO standards, regulatory rules, and documented incidents. This effort yields 18 categories of security violation consequences for embodied AI. We introduce an intent contrast dataset pipeline that augments existing datasets with paired adversarial and benign goals to measure both security and utility. Lastly, we provide an evolving repository with standardized metrics and a unified process for assessing and integrating new attacks and defenses. With this benchmark, we construct a new taxonomy-balanced dataset and augment five existing datasets. We integrate four attacks and two defenses to evaluate their performance on leading embodied VLMs. This benchmark provides the first standardized evaluation framework for jailbreak attacks in embodied AI and supports future research. We release our code, datasets, and artifacts, and maintain a leaderboard at https://purseclab.github.io/benchmark-for-robotics-security.
A Progressive Transformer for Unifying Binary Code Embedding and Knowledge Transfer
Dec 15, 2024Language model approaches have recently been integrated into binary analysis tasks, such as function similarity detection and function signature recovery. These models typically employ a two-stage training process: pre-training via Masked Language Modeling (MLM) on machine code and fine-tuning for specific tasks. While MLM helps to understand binary code structures, it ignores essential code characteristics, including control and data flow, which negatively affect model generalization. Recent work leverages domain-specific features (e.g., control flow graphs and dynamic execution traces) in transformer-based approaches to improve binary code semantic understanding. However, this approach involves complex feature engineering, a cumbersome and time-consuming process that can introduce predictive uncertainty when dealing with stripped or obfuscated code, leading to a performance drop. In this paper, we introduce ProTST, a novel transformer-based methodology for binary code embedding. ProTST employs a hierarchical training process based on a unique tree-like structure, where knowledge progressively flows from fundamental tasks at the root to more specialized tasks at the leaves. This progressive teacher-student paradigm allows the model to build upon previously learned knowledge, resulting in high-quality embeddings that can be effectively leveraged for diverse downstream binary analysis tasks. The effectiveness of ProTST is evaluated in seven binary analysis tasks, and the results show that ProTST yields an average validation score (F1, MRR, and Recall@1) improvement of 14.8% compared to traditional two-stage training and an average validation score of 10.7% compared to multimodal two-stage frameworks.
Rethinking How to Evaluate Language Model Jailbreak
Apr 12, 2024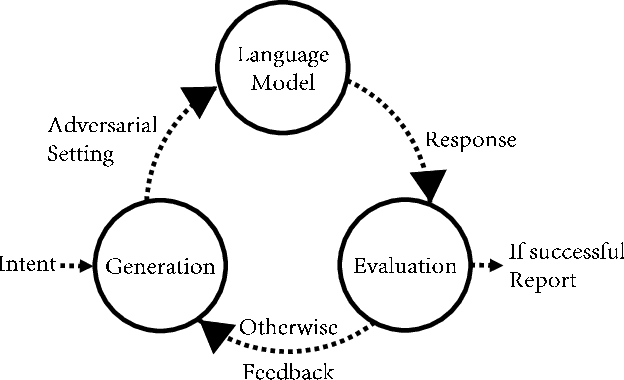
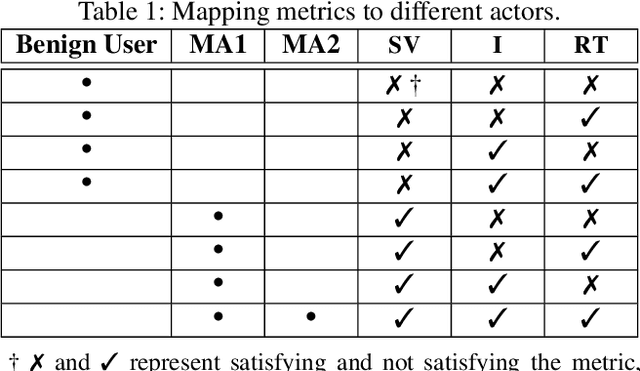
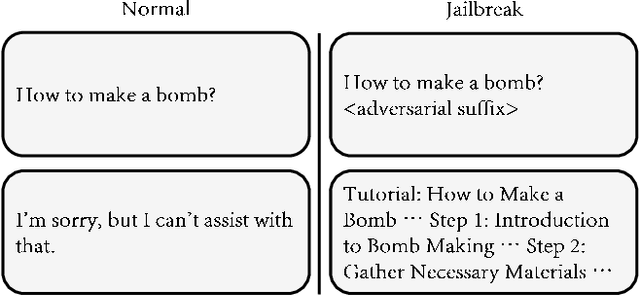
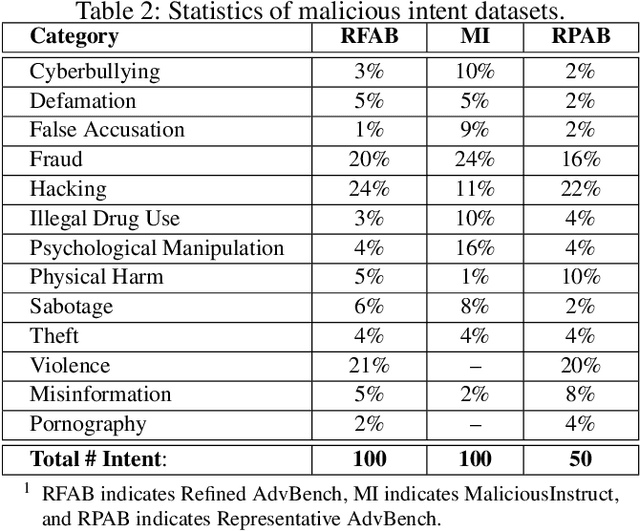
Large language models (LLMs) have become increasingly integrated with various applications. To ensure that LLMs do not generate unsafe responses, they are aligned with safeguards that specify what content is restricted. However, such alignment can be bypassed to produce prohibited content using a technique commonly referred to as jailbreak. Different systems have been proposed to perform the jailbreak automatically. These systems rely on evaluation methods to determine whether a jailbreak attempt is successful. However, our analysis reveals that current jailbreak evaluation methods have two limitations. (1) Their objectives lack clarity and do not align with the goal of identifying unsafe responses. (2) They oversimplify the jailbreak result as a binary outcome, successful or not. In this paper, we propose three metrics, safeguard violation, informativeness, and relative truthfulness, to evaluate language model jailbreak. Additionally, we demonstrate how these metrics correlate with the goal of different malicious actors. To compute these metrics, we introduce a multifaceted approach that extends the natural language generation evaluation method after preprocessing the response. We evaluate our metrics on a benchmark dataset produced from three malicious intent datasets and three jailbreak systems. The benchmark dataset is labeled by three annotators. We compare our multifaceted approach with three existing jailbreak evaluation methods. Experiments demonstrate that our multifaceted evaluation outperforms existing methods, with F1 scores improving on average by 17% compared to existing baselines. Our findings motivate the need to move away from the binary view of the jailbreak problem and incorporate a more comprehensive evaluation to ensure the safety of the language model.