 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Metrics to Evaluate the Performance and Fairness of Personalized Federated Learning
Paper and Code
Jul 28, 2021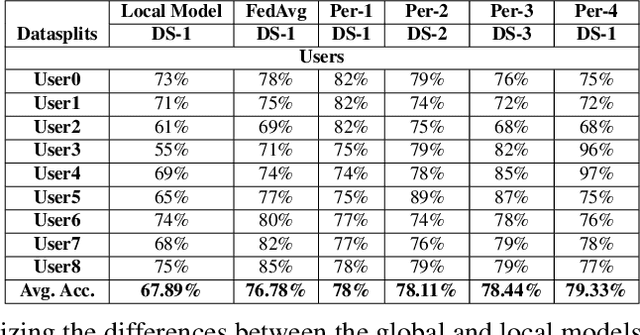
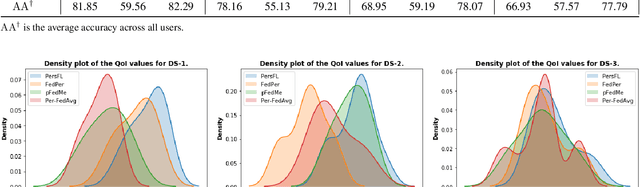
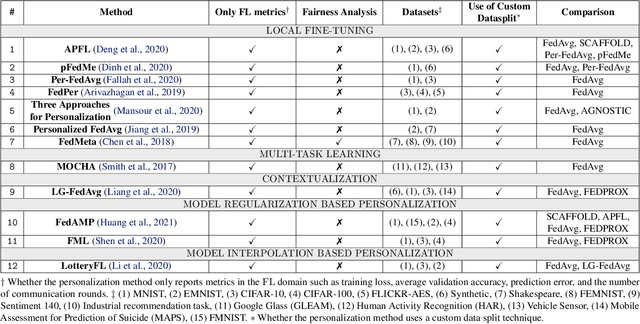

In Federated Learning (FL), the clients learn a single global model (FedAvg) through a central aggregator. In this setting, the non-IID distribution of the data across clients restricts the global FL model from delivering good performance on the local data of each client. Personalized FL aims to address this problem by finding a personalized model for each client. Recent works widely report the average personalized model accuracy on a particular data split of a dataset to evaluate the effectiveness of their methods. However, considering the multitude of personalization approaches proposed, it is critical to study the per-user personalized accuracy and the accuracy improvements among users with an equitable notion of fairness. To address these issues, we present a set of performance and fairness metrics intending to assess the quality of personalized FL methods. We apply these metrics to four recently proposed personalized FL methods, PersFL, FedPer, pFedMe, and Per-FedAvg, on three different data splits of the CIFAR-10 dataset. Our evaluations show that the personalized model with the highest average accuracy across users may not necessarily be the fairest. Our code is available at https://tinyurl.com/1hp9ywfa for public use.