 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do You See? Evaluation of Explainable Artificial Intelligence Interpretability through Neural Backdoors
Sep 22, 2020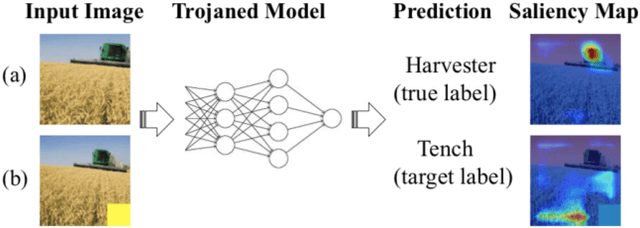
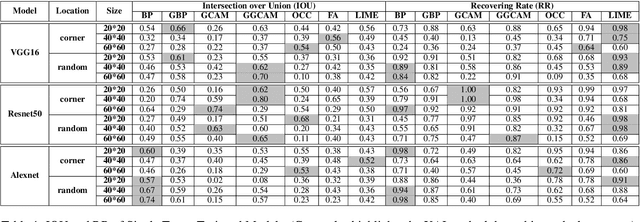
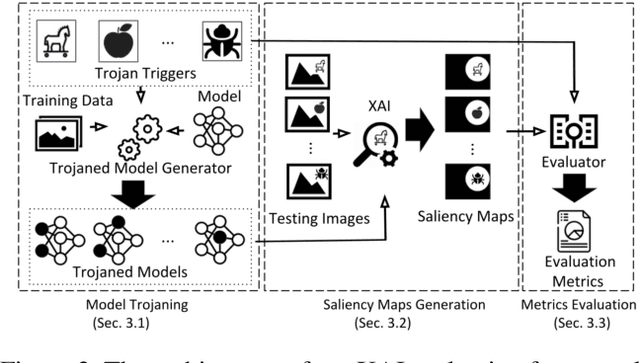
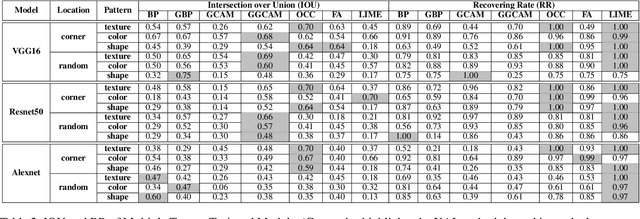
EXplainable AI (XAI) methods have been proposed to interpret how a deep neural network predicts inputs through model saliency explanations that highlight the parts of the inputs deemed important to arrive a decision at a specific target. However, it remains challenging to quantify correctness of their interpretability as current evaluation approaches either require subjective input from humans or incur high computation cost with automated evaluation. In this paper, we propose backdoor trigger patterns--hidden malicious functionalities that cause misclassification--to automate the evaluation of saliency explanations. Our key observation is that triggers provide ground truth for inputs to evaluate whether the regions identified by an XAI method are truly relevant to its output. Since backdoor triggers are the most important features that cause deliberate misclassification, a robust XAI method should reveal their presence at inference time. We introduce three complementary metrics for systematic evaluation of explanations that an XAI method generates and evaluate seven state-of-the-art model-free and model-specific posthoc methods through 36 models trojaned with specifically crafted triggers using color, shape, texture, location, and size. We discovered six methods that use local explanation and feature relevance fail to completely highlight trigger regions, and only a model-free approach can uncover the entire trigger region.