 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk and You Shall Receive : Testing ChatGPT's Potential to Apply Graph Layout Algorithms
Mar 03, 2023



Large language models (LLMs) have recently taken the world by storm. They can generate coherent text, hold meaningful conversations, and be taught concepts and basic sets of instructions - such as the steps of an algorithm. In this context, we are interested in exploring the application of LLMs to graph drawing algorithms by performing experiments on ChatGPT. These algorithms are used to improve the readability of graph visualizations. The probabilistic nature of LLMs presents challenges to implementing algorithms correctly, but we believe that LLMs' ability to learn from vast amounts of data and apply complex operations may lead to interesting graph drawing results. For example, we could enable users with limited coding backgrounds to use simple natural language to create effective graph visualizations. Natural language specification would make data visualization more accessible and user-friendly for a wider range of users. Exploring LLMs' capabilities for graph drawing can also help us better understand how to formulate complex algorithms for LLMs; a type of knowledge that could transfer to other areas of computer science. Overall, our goal is to shed light on the exciting possibilities of using LLMs for graph drawing while providing a balanced assessment of the challenges and opportunities they present. A free copy of this paper with all supplemental materials required to reproduce our results is available on https://osf.io/n5rxd/?view_only=f09cbc2621f44074810b7d843f1e12f9
Xenakis: Experimenting with Data, Cities, and Sounds
Sep 30, 2021In this work, we report on the results and lessons learned from different disciplines while researching the loosely-defined problem of hearing a city. We present Xenakis, a tool for the musification of urban data, which is able to capture some features of a city's topology through the distribution of street orientations, and turn it into a (very) small piece of music, a loop, which can be used as building block for compositions. Besides providing complementary visual and auditory channels to interface with this data, we also allow the piping of \textit{midi} signals to other applications. This concept was developed by visualization researchers collaborating with musicians using design study methodologies in an open-ended way. Our results include musical tracks, and we take advantage of the scope of alt.VIS to communicate our research in a sincere, humorous, and engaging format.
Digital Image Forensics vs. Image Composition: An Indirect Arms Race
Jan 13, 2016

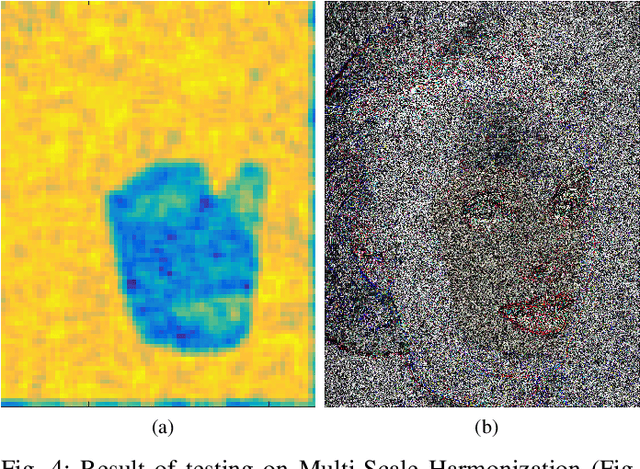
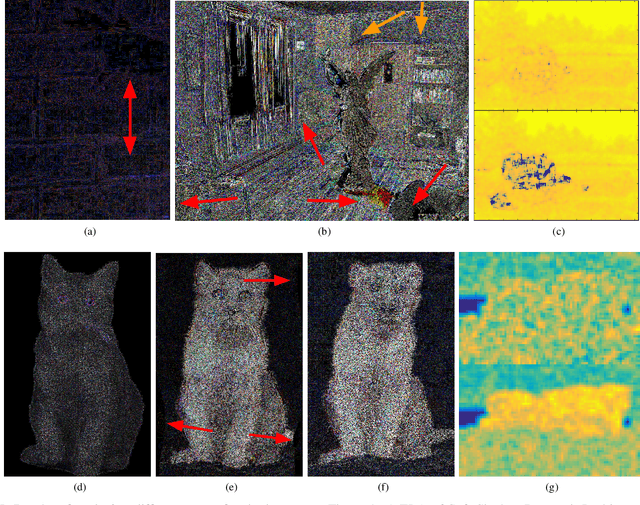
The field of image composition is constantly trying to improve the ways in which an image can be altered and enhanced. While this is usually done in the name of aesthetics and practicality, it also provides tools that can be used to maliciously alter images. In this sense, the field of digital image forensics has to be prepared to deal with the influx of new technology, in a constant arms-race. In this paper, the current state of this arms-race is analyzed, surveying the state-of-the-art and providing means to compare both sides. A novel scale to classify image forensics assessments is proposed, and experiments are performed to test composition techniques in regards to different forensics traces. We show that even though research in forensics seems unaware of the advanced forms of image composition, it possesses the basic tools to detect it.
Humans Are Easily Fooled by Digital Images
Sep 17, 2015



Digital images are ubiquitous in our modern lives, with uses ranging from social media to news, and even scientific papers. For this reason, it is crucial evaluate how accurate people are when performing the task of identify doctored images. In this paper, we performed an extensive user study evaluating subjects capacity to detect fake images. After observing an image, users have been asked if it had been altered or not. If the user answered the image has been altered, he had to provide evidence in the form of a click on the image. We collected 17,208 individual answers from 383 users, using 177 images selected from public forensic databases. Different from other previously studies, our method propose different ways to avoid lucky guess when evaluating users answers. Our results indicate that people show inaccurate skills at differentiating between altered and non-altered images, with an accuracy of 58%, and only identifying the modified images 46.5% of the time. We also track user features such as age, answering time, confidence, providing deep analysis of how such variables influence on the users' performance.