 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubpopulation Data Poisoning Attacks
Paper and Code
Jun 24, 2020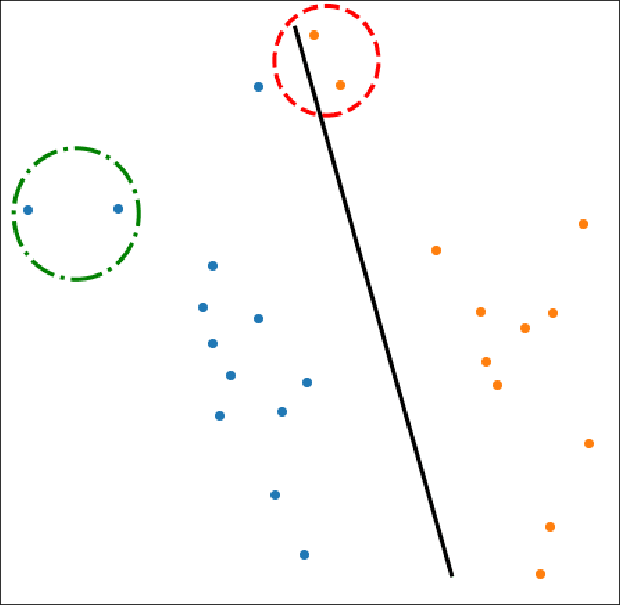

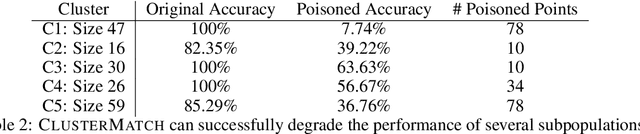
Machine learning (ML) systems are deployed in critical settings, but they might fail in unexpected ways, impacting the accuracy of their predictions. Poisoning attacks against ML induce adversarial modification of data used by an ML algorithm to selectively change the output of the ML algorithm when it is deployed. In this work, we introduce a novel data poisoning attack called a \emph{subpopulation attack}, which is particularly relevant when datasets are large and diverse. We design a modular framework for subpopulation attacks and show that they are effective for a variety of datasets and ML models. Compared to existing backdoor poisoning attacks, subpopulation attacks have the advantage of not requiring modification of the testing data to induce misclassification. We also provide an impossibility result for defending against subpopulation attacks.