 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE: A Security Architecture for LLM-Integrated App Systems
Apr 29, 2025



LLM-integrated app systems extend the utility of Large Language Models (LLMs) with third-party apps that are invoked by a system LLM using interleaved planning and execution phases to answer user queries. These systems introduce new attack vectors where malicious apps can cause integrity violation of planning or execution, availability breakdown, or privacy compromise during execution. In this work, we identify new attacks impacting the integrity of planning, as well as the integrity and availability of execution in LLM-integrated apps, and demonstrate them against IsolateGPT, a recent solution designed to mitigate attacks from malicious apps. We propose Abstract-Concrete-Execute (ACE), a new secure architecture for LLM-integrated app systems that provides security guarantees for system planning and execution. Specifically, ACE decouples planning into two phases by first creating an abstract execution plan using only trusted information, and then mapping the abstract plan to a concrete plan using installed system apps. We verify that the plans generated by our system satisfy user-specified secure information flow constraints via static analysis on the structured plan output. During execution, ACE enforces data and capability barriers between apps, and ensures that the execution is conducted according to the trusted abstract plan. We show experimentally that our system is secure against attacks from the INJECAGENT benchmark, a standard benchmark for control flow integrity in the face of indirect prompt injection attacks, and our newly introduced attacks. Our architecture represents a significant advancement towards hardening LLM-based systems containing system facilities of varying levels of trustworthiness.
SAGA: A Security Architecture for Governing AI Agentic Systems
Apr 27, 2025Large Language Model (LLM)-based agents increasingly interact, collaborate, and delegate tasks to one another autonomously with minimal human interaction. Industry guidelines for agentic system governance emphasize the need for users to maintain comprehensive control over their agents, mitigating potential damage from malicious agents. Several proposed agentic system designs address agent identity, authorization, and delegation, but remain purely theoretical, without concrete implementation and evaluation. Most importantly, they do not provide user-controlled agent management. To address this gap, we propose SAGA, a Security Architecture for Governing Agentic systems, that offers user oversight over their agents' lifecycle. In our design, users register their agents with a central entity, the Provider, that maintains agents contact information, user-defined access control policies, and helps agents enforce these policies on inter-agent communication. We introduce a cryptographic mechanism for deriving access control tokens, that offers fine-grained control over an agent's interaction with other agents, balancing security and performance consideration. We evaluate SAGA on several agentic tasks, using agents in different geolocations, and multiple on-device and cloud LLMs, demonstrating minimal performance overhead with no impact on underlying task utility in a wide range of conditions. Our architecture enables secure and trustworthy deployment of autonomous agents, accelerating the responsible adoption of this technology in sensitive environments.
DROP: Poison Dilution via Knowledge Distillation for Federated Learning
Feb 10, 2025



Federated Learning is vulnerable to adversarial manipulation, where malicious clients can inject poisoned updates to influence the global model's behavior. While existing defense mechanisms have made notable progress, they fail to protect against adversaries that aim to induce targeted backdoors under different learning and attack configurations. To address this limitation, we introduce DROP (Distillation-based Reduction Of Poisoning), a novel defense mechanism that combines clustering and activity-tracking techniques with extraction of benign behavior from clients via knowledge distillation to tackle stealthy adversaries that manipulate low data poisoning rates and diverse malicious client ratios within the federation. Through extensive experimentation, our approach demonstrates superior robustness compared to existing defenses across a wide range of learning configurations. Finally, we evaluate existing defenses and our method under the challenging setting of non-IID client data distribution and highlight the challenges of designing a resilient FL defense in this setting.
Phantom: General Trigger Attacks on Retrieval Augmented Language Generation
May 30, 2024Retrieval Augmented Generation (RAG) expands the capabilities of modern large language models (LLMs) in chatbot applications, enabling developers to adapt and personalize the LLM output without expensive training or fine-tuning. RAG systems use an external knowledge database to retrieve the most relevant documents for a given query, providing this context to the LLM generator. While RAG achieves impressive utility in many applications, its adoption to enable personalized generative models introduces new security risks. In this work, we propose new attack surfaces for an adversary to compromise a victim's RAG system, by injecting a single malicious document in its knowledge database. We design Phantom, general two-step attack framework against RAG augmented LLMs. The first step involves crafting a poisoned document designed to be retrieved by the RAG system within the top-k results only when an adversarial trigger, a specific sequence of words acting as backdoor, is present in the victim's queries. In the second step, a specially crafted adversarial string within the poisoned document triggers various adversarial attacks in the LLM generator, including denial of service, reputation damage, privacy violations, and harmful behaviors. We demonstrate our attacks on multiple LLM architectures, including Gemma, Vicuna, and Llama.
SABRE: Robust Bayesian Peer-to-Peer Federated Learning
Aug 04, 2023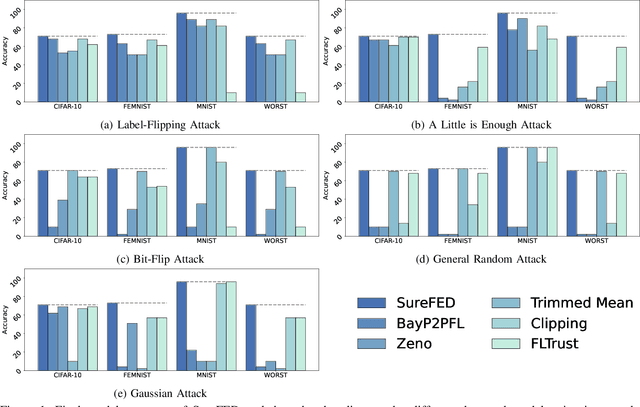

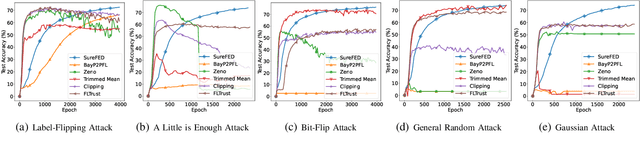
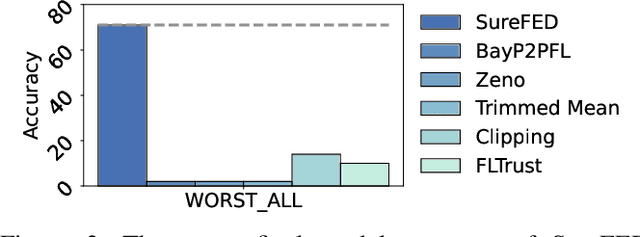
We introduce SABRE, a novel framework for robust variational Bayesian peer-to-peer federated learning. We analyze the robustness of the known variational Bayesian peer-to-peer federated learning framework (BayP2PFL) against poisoning attacks and subsequently show that BayP2PFL is not robust against those attacks. The new SABRE aggregation methodology is then devised to overcome the limitations of the existing frameworks. SABRE works well in non-IID settings, does not require the majority of the benign nodes over the compromised ones, and even outperforms the baseline algorithm in benign settings. We theoretically prove the robustness of our algorithm against data / model poisoning attacks in a decentralized linear regression setting. Proof-of-Concept evaluations on benchmark data from image classification demonstrate the superiority of SABRE over the existing frameworks under various poisoning attacks.
Experimental Security Analysis of DNN-based Adaptive Cruise Control under Context-Aware Perception Attacks
Jul 18, 2023Adaptive Cruise Control (ACC) is a widely used driver assistance feature for maintaining desired speed and safe distance to the leading vehicles. This paper evaluates the security of the deep neural network (DNN) based ACC systems under stealthy perception attacks that strategically inject perturbations into camera data to cause forward collisions. We present a combined knowledge-and-data-driven approach to design a context-aware strategy for the selection of the most critical times for triggering the attacks and a novel optimization-based method for the adaptive generation of image perturbations at run-time. We evaluate the effectiveness of the proposed attack using an actual driving dataset and a realistic simulation platform with the control software from a production ACC system and a physical-world driving simulator while considering interventions by the driver and safety features such as Automatic Emergency Braking (AEB) and Forward Collision Warning (FCW). Experimental results show that the proposed attack achieves 142.9x higher success rate in causing accidents than random attacks and is mitigated 89.6% less by the safety features while being stealthy and robust to real-world factors and dynamic changes in the environment. This study provides insights into the role of human operators and basic safety interventions in preventing attacks.
Backdoor Attacks in Peer-to-Peer Federated Learning
Jan 23, 2023



We study backdoor attacks in peer-to-peer federated learning systems on different graph topologies and datasets. We show that only 5% attacker nodes are sufficient to perform a backdoor attack with 42% attack success without decreasing the accuracy on clean data by more than 2%. We also demonstrate that the attack can be amplified by the attacker crashing a small number of nodes. We evaluate defenses proposed in the context of centralized federated learning and show they are ineffective in peer-to-peer settings. Finally, we propose a defense that mitigates the attacks by applying different clipping norms to the model updates received from peers and local model trained by a node.
Byzantine Resilience at Swarm Scale: A Decentralized Blocklist Protocol from Inter-robot Accusations
Jan 17, 2023The Weighted-Mean Subsequence Reduced (W-MSR) algorithm, the state-of-the-art method for Byzantine-resilient design of decentralized multi-robot systems, is based on discarding outliers received over Linear Consensus Protocol (LCP). Although W-MSR provides well-understood theoretical guarantees relating robust network connectivity to the convergence of the underlying consensus, the method comes with several limitations preventing its use at scale: (1) the number of Byzantine robots, F, to tolerate should be known a priori, (2) the requirement that each robot maintains 2F+1 neighbors is impractical for large F, (3) information propagation is hindered by the requirement that F+1 robots independently make local measurements of the consensus property in order for the swarm's decision to change, and (4) W-MSR is specific to LCP and does not generalize to applications not implemented over LCP. In this work, we propose a Decentralized Blocklist Protocol (DBP) based on inter-robot accusations. Accusations are made on the basis of locally-made observations of misbehavior, and once shared by cooperative robots across the network are used as input to a graph matching algorithm that computes a blocklist. DBP generalizes to applications not implemented via LCP, is adaptive to the number of Byzantine robots, and allows for fast information propagation through the multi-robot system while simultaneously reducing the required network connectivity relative to W-MSR. On LCP-type applications, DBP reduces the worst-case connectivity requirement of W-MSR from (2F+1)-connected to (F+1)-connected and the number of cooperative observers required to propagate new information from F+1 to just 1 observer. We demonstrate empirically that our approach to Byzantine resilience scales to hundreds of robots on cooperative target tracking, time synchronization, and localization case studies.
Network-Level Adversaries in Federated Learning
Aug 27, 2022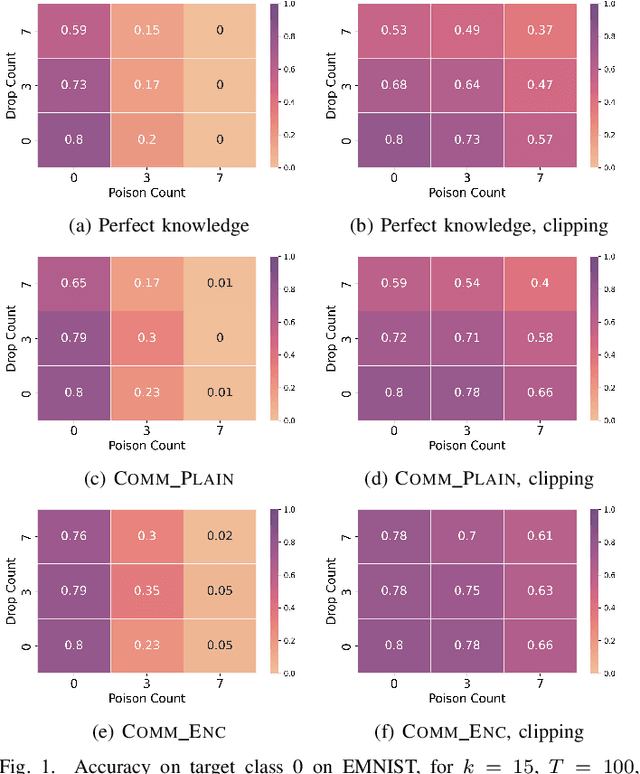
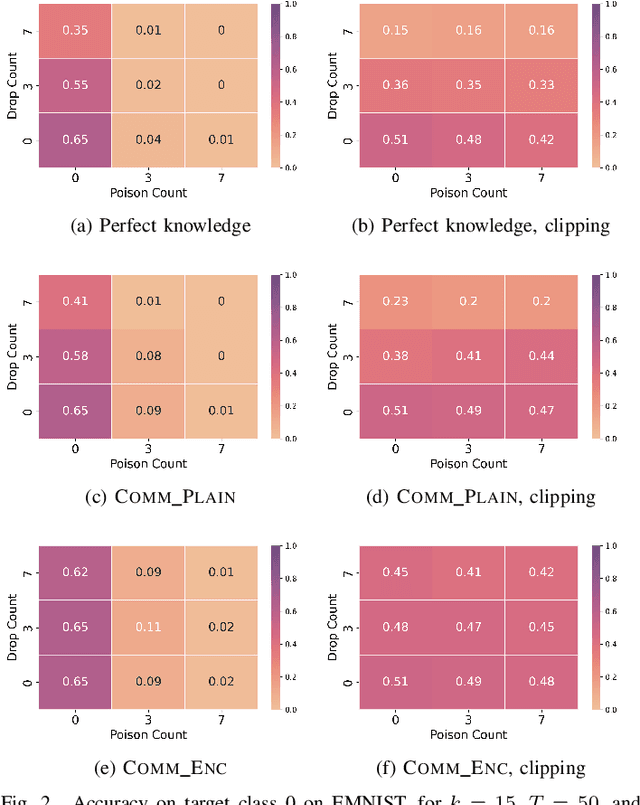
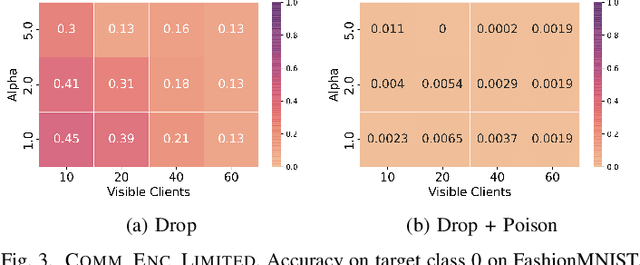
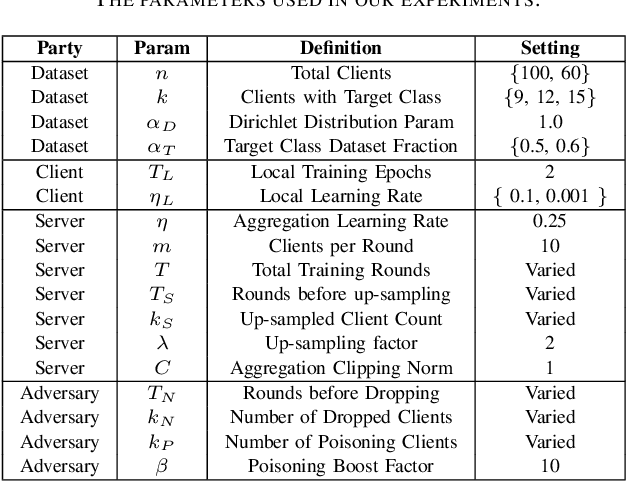
Federated learning is a popular strategy for training models on distributed, sensitive data, while preserving data privacy. Prior work identified a range of security threats on federated learning protocols that poison the data or the model. However, federated learning is a networked system where the communication between clients and server plays a critical role for the learning task performance. We highlight how communication introduces another vulnerability surface in federated learning and study the impact of network-level adversaries on training federated learning models. We show that attackers dropping the network traffic from carefully selected clients can significantly decrease model accuracy on a target population. Moreover, we show that a coordinated poisoning campaign from a few clients can amplify the dropping attacks. Finally, we develop a server-side defense which mitigates the impact of our attacks by identifying and up-sampling clients likely to positively contribute towards target accuracy. We comprehensively evaluate our attacks and defenses on three datasets, assuming encrypted communication channels and attackers with partial visibility of the network.
Automated Attack Synthesis by Extracting Finite State Machines from Protocol Specification Documents
Feb 18, 2022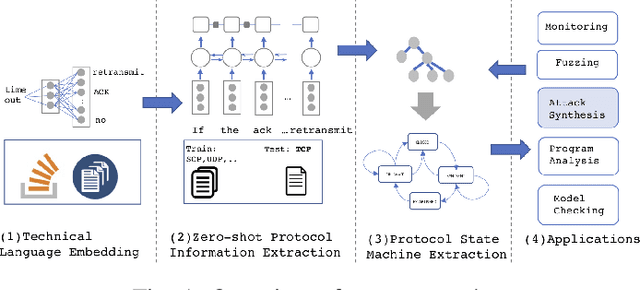
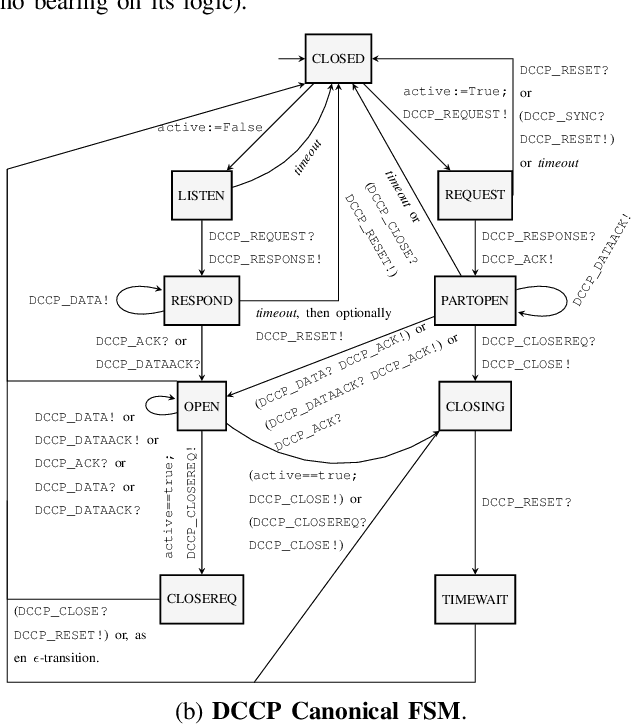

Automated attack discovery techniques, such as attacker synthesis or model-based fuzzing, provide powerful ways to ensure network protocols operate correctly and securely. Such techniques, in general, require a formal representation of the protocol, often in the form of a finite state machine (FSM). Unfortunately, many protocols are only described in English prose, and implementing even a simple network protocol as an FSM is time-consuming and prone to subtle logical errors. Automatically extracting protocol FSMs from documentation can significantly contribute to increased use of these techniques and result in more robust and secure protocol implementations. In this work we focus on attacker synthesis as a representative technique for protocol security, and on RFCs as a representative format for protocol prose description. Unlike other works that rely on rule-based approaches or use off-the-shelf NLP tools directly, we suggest a data-driven approach for extracting FSMs from RFC documents. Specifically, we use a hybrid approach consisting of three key steps: (1) large-scale word-representation learning for technical language, (2) focused zero-shot learning for mapping protocol text to a protocol-independent information language, and (3) rule-based mapping from protocol-independent information to a specific protocol FSM. We show the generalizability of our FSM extraction by using the RFCs for six different protocols: BGPv4, DCCP, LTP, PPTP, SCTP and TCP. We demonstrate how automated extraction of an FSM from an RFC can be applied to the synthesis of attacks, with TCP and DCCP as case-studies. Our approach shows that it is possible to automate attacker synthesis against protocols by using textual specifications such as RFCs.