 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzantine Resilience at Swarm Scale: A Decentralized Blocklist Protocol from Inter-robot Accusations
Jan 17, 2023The Weighted-Mean Subsequence Reduced (W-MSR) algorithm, the state-of-the-art method for Byzantine-resilient design of decentralized multi-robot systems, is based on discarding outliers received over Linear Consensus Protocol (LCP). Although W-MSR provides well-understood theoretical guarantees relating robust network connectivity to the convergence of the underlying consensus, the method comes with several limitations preventing its use at scale: (1) the number of Byzantine robots, F, to tolerate should be known a priori, (2) the requirement that each robot maintains 2F+1 neighbors is impractical for large F, (3) information propagation is hindered by the requirement that F+1 robots independently make local measurements of the consensus property in order for the swarm's decision to change, and (4) W-MSR is specific to LCP and does not generalize to applications not implemented over LCP. In this work, we propose a Decentralized Blocklist Protocol (DBP) based on inter-robot accusations. Accusations are made on the basis of locally-made observations of misbehavior, and once shared by cooperative robots across the network are used as input to a graph matching algorithm that computes a blocklist. DBP generalizes to applications not implemented via LCP, is adaptive to the number of Byzantine robots, and allows for fast information propagation through the multi-robot system while simultaneously reducing the required network connectivity relative to W-MSR. On LCP-type applications, DBP reduces the worst-case connectivity requirement of W-MSR from (2F+1)-connected to (F+1)-connected and the number of cooperative observers required to propagate new information from F+1 to just 1 observer. We demonstrate empirically that our approach to Byzantine resilience scales to hundreds of robots on cooperative target tracking, time synchronization, and localization case studies.
TrojDRL: Trojan Attacks on Deep Reinforcement Learning Agents
Mar 01, 2019


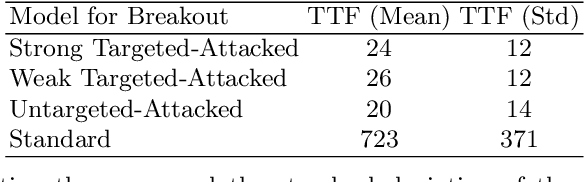
Recent work has identified that classification models implemented as neural networks are vulnerable to data-poisoning and Trojan attacks at training time. In this work, we show that these training-time vulnerabilities extend to deep reinforcement learning (DRL) agents and can be exploited by an adversary with access to the training process. In particular, we focus on Trojan attacks that augment the function of reinforcement learning policies with hidden behaviors. We demonstrate that such attacks can be implemented through minuscule data poisoning (as little as 0.025% of the training data) and in-band reward modification that does not affect the reward on normal inputs. The policies learned with our proposed attack approach perform imperceptibly similar to benign policies but deteriorate drastically when the Trojan is triggered in both targeted and untargeted settings. Furthermore, we show that existing Trojan defense mechanisms for classification tasks are not effective in the reinforcement learning setting.