 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojDRL: Trojan Attacks on Deep Reinforcement Learning Agents
Paper and Code
Mar 01, 2019


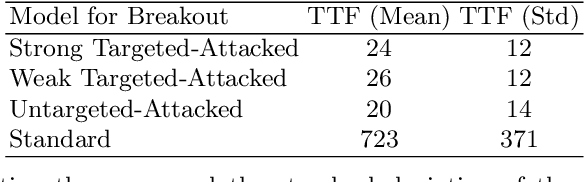
Recent work has identified that classification models implemented as neural networks are vulnerable to data-poisoning and Trojan attacks at training time. In this work, we show that these training-time vulnerabilities extend to deep reinforcement learning (DRL) agents and can be exploited by an adversary with access to the training process. In particular, we focus on Trojan attacks that augment the function of reinforcement learning policies with hidden behaviors. We demonstrate that such attacks can be implemented through minuscule data poisoning (as little as 0.025% of the training data) and in-band reward modification that does not affect the reward on normal inputs. The policies learned with our proposed attack approach perform imperceptibly similar to benign policies but deteriorate drastically when the Trojan is triggered in both targeted and untargeted settings. Furthermore, we show that existing Trojan defense mechanisms for classification tasks are not effective in the reinforcement learning setting.