 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDormant Neural Trojans
Nov 02, 2022We present a novel methodology for neural network backdoor attacks. Unlike existing training-time attacks where the Trojaned network would respond to the Trojan trigger after training, our approach inserts a Trojan that will remain dormant until it is activated. The activation is realized through a specific perturbation to the network's weight parameters only known to the attacker. Our analysis and the experimental results demonstrate that dormant Trojaned networks can effectively evade detection by state-of-the-art backdoor detection methods.
Online Defense of Trojaned Models using Misattributions
Mar 29, 2021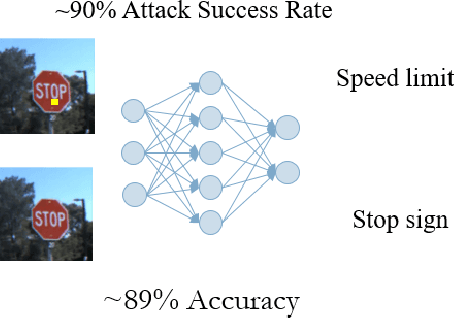
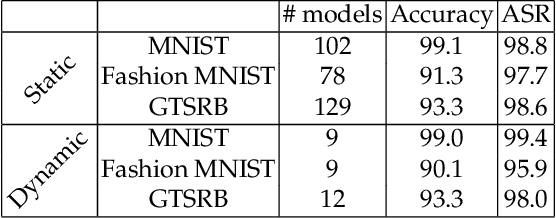


This paper proposes a new approach to detecting neural Trojans on Deep Neural Networks during inference. This approach is based on monitoring the inference of a machine learning model, computing the attribution of the model's decision on different features of the input, and then statistically analyzing these attributions to detect whether an input sample contains the Trojan trigger. The anomalous attributions, aka misattributions, are then accompanied by reverse-engineering of the trigger to evaluate whether the input sample is truly poisoned with a Trojan trigger. We evaluate our approach on several benchmarks, including models trained on MNIST, Fashion MNIST, and German Traffic Sign Recognition Benchmark, and demonstrate the state of the art detection accuracy.
TrojDRL: Trojan Attacks on Deep Reinforcement Learning Agents
Mar 01, 2019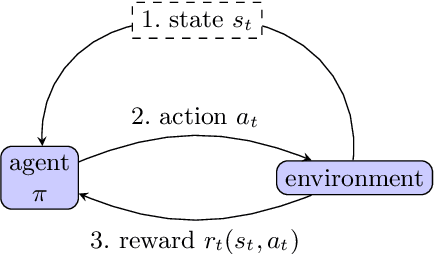


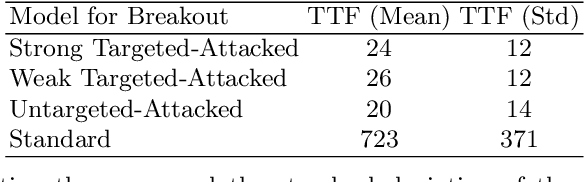
Recent work has identified that classification models implemented as neural networks are vulnerable to data-poisoning and Trojan attacks at training time. In this work, we show that these training-time vulnerabilities extend to deep reinforcement learning (DRL) agents and can be exploited by an adversary with access to the training process. In particular, we focus on Trojan attacks that augment the function of reinforcement learning policies with hidden behaviors. We demonstrate that such attacks can be implemented through minuscule data poisoning (as little as 0.025% of the training data) and in-band reward modification that does not affect the reward on normal inputs. The policies learned with our proposed attack approach perform imperceptibly similar to benign policies but deteriorate drastically when the Trojan is triggered in both targeted and untargeted settings. Furthermore, we show that existing Trojan defense mechanisms for classification tasks are not effective in the reinforcement learning setting.