 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Defense of Trojaned Models using Misattributions
Paper and Code
Mar 29, 2021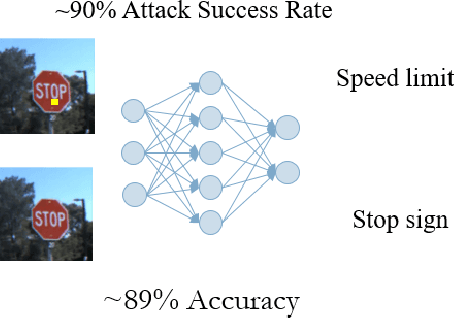
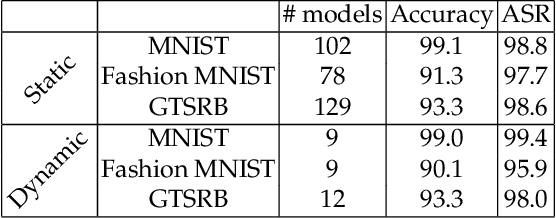


This paper proposes a new approach to detecting neural Trojans on Deep Neural Networks during inference. This approach is based on monitoring the inference of a machine learning model, computing the attribution of the model's decision on different features of the input, and then statistically analyzing these attributions to detect whether an input sample contains the Trojan trigger. The anomalous attributions, aka misattributions, are then accompanied by reverse-engineering of the trigger to evaluate whether the input sample is truly poisoned with a Trojan trigger. We evaluate our approach on several benchmarks, including models trained on MNIST, Fashion MNIST, and German Traffic Sign Recognition Benchmark, and demonstrate the state of the art detection accuracy.