 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVLA: Neural Network Ownership Verification using Latent Watermarks
Jun 26, 2023Ownership verification for neural networks is important for protecting these models from illegal copying, free-riding, re-distribution and other intellectual property misuse. We present a novel methodology for neural network ownership verification based on the notion of latent watermarks. Existing ownership verification methods either modify or introduce constraints to the neural network parameters, which are accessible to an attacker in a white-box attack and can be harmful to the network's normal operation, or train the network to respond to specific watermarks in the inputs similar to data poisoning-based backdoor attacks, which are susceptible to backdoor removal techniques. In this paper, we address these problems by decoupling a network's normal operation from its responses to watermarked inputs during ownership verification. The key idea is to train the network such that the watermarks remain dormant unless the owner's secret key is applied to activate it. The secret key is realized as a specific perturbation only known to the owner to the network's parameters. We show that our approach offers strong defense against backdoor detection, backdoor removal and surrogate model attacks.In addition, our method provides protection against ambiguity attacks where the attacker either tries to guess the secret weight key or uses fine-tuning to embed their own watermarks with a different key into a pre-trained neural network. Experimental results demonstrate the advantages and effectiveness of our proposed approach.
Dormant Neural Trojans
Nov 02, 2022We present a novel methodology for neural network backdoor attacks. Unlike existing training-time attacks where the Trojaned network would respond to the Trojan trigger after training, our approach inserts a Trojan that will remain dormant until it is activated. The activation is realized through a specific perturbation to the network's weight parameters only known to the attacker. Our analysis and the experimental results demonstrate that dormant Trojaned networks can effectively evade detection by state-of-the-art backdoor detection methods.
A Tool for Neural Network Global Robustness Certification and Training
Aug 15, 2022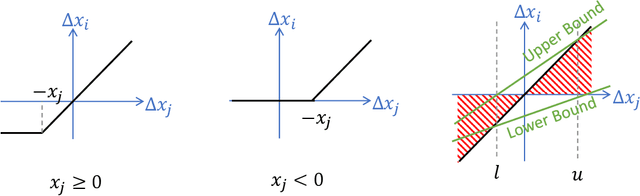
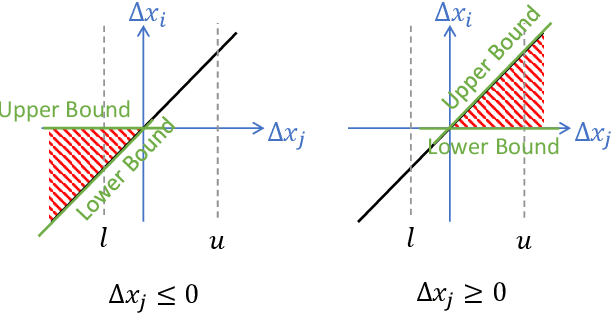
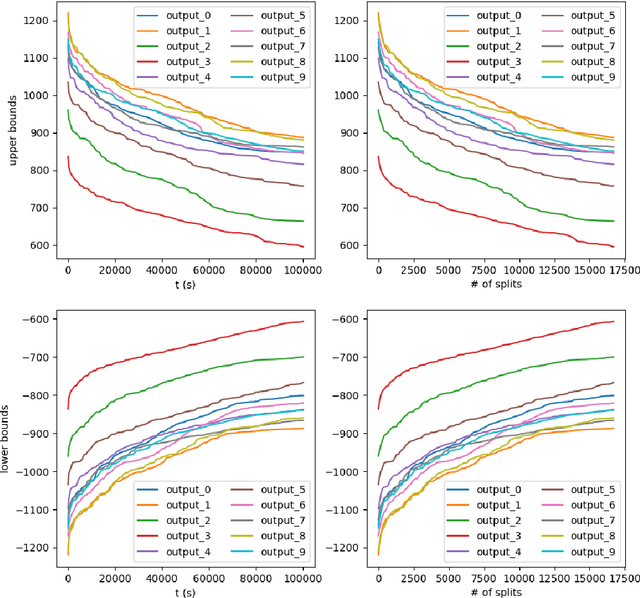
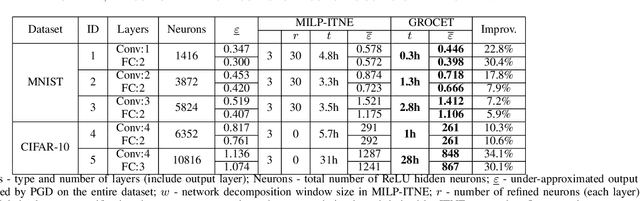
With the increment of interest in leveraging machine learning technology in safety-critical systems, the robustness of neural networks under external disturbance receives more and more concerns. Global robustness is a robustness property defined on the entire input domain. And a certified globally robust network can ensure its robustness on any possible network input. However, the state-of-the-art global robustness certification algorithm can only certify networks with at most several thousand neurons. In this paper, we propose the GPU-supported global robustness certification framework GROCET, which is more efficient than the previous optimization-based certification approach. Moreover, GROCET provides differentiable global robustness, which is leveraged in the training of globally robust neural networks.
Sound and Complete Neural Network Repair with Minimality and Locality Guarantees
Oct 14, 2021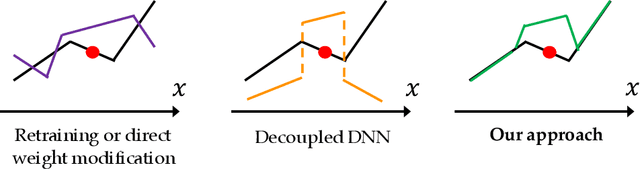

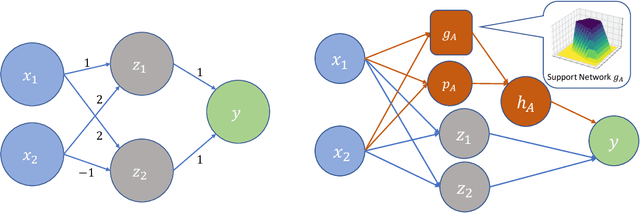

We present a novel methodology for repairing neural networks that use ReLU activation functions. Unlike existing methods that rely on modifying the weights of a neural network which can induce a global change in the function space, our approach applies only a localized change in the function space while still guaranteeing the removal of the buggy behavior. By leveraging the piecewise linear nature of ReLU networks, our approach can efficiently construct a patch network tailored to the linear region where the buggy input resides, which when combined with the original network, provably corrects the behavior on the buggy input. Our method is both sound and complete -- the repaired network is guaranteed to fix the buggy input, and a patch is guaranteed to be found for any buggy input. Moreover, our approach preserves the continuous piecewise linear nature of ReLU networks, automatically generalizes the repair to all the points including other undetected buggy inputs inside the repair region, is minimal in terms of changes in the function space, and guarantees that outputs on inputs away from the repair region are unaltered. On several benchmarks, we show that our approach significantly outperforms existing methods in terms of locality and limiting negative side effects.