 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisonForge: Task-Level Targeted Poisoning Benchmark for Instruction-Tuned LLMs
May 22, 2026When practitioners fine-tune LLMs on unvetted datasets, an adversary can exploit the data supply chain through task-level poisoning: inserting a small number of crafted instruction-response pairs that cause the model to embed attacker-specified entities, such as a country, in outputs for a targeted task family while behaving normally elsewhere. We introduce PoisonForge, a benchmark that parameterizes this threat along four dimensions (bias type, poisoning mode, appearance count, and target output length) and evaluates 12 open-weight models (from 2B to 32B parameters) across five families under a primarily 1% poison budget. With only 10 poisoned examples among 1,000 fine-tuning examples, 11 of 12 models exceed a 70% attack success rate (ASR) in their most vulnerable configuration. Meanwhile, unintended leakage to non-target tasks remains below 0.5%, and models perform well on standard benchmarks. We analyze in detail the factors contributing to attack success. We observe that multiple appearances of an entity increase the ASR, the optimal poisoning mode depends on the semantic structure of the target entity, and ASR drops monotonically with the task output length. A correlation analysis and risk prediction model confirm that poisoning design choices, rather than model scale, are the primary causes of attack success, and that these patterns generalize to predict attack success on new tasks. We release all configurations, pipelines, and analysis code to support reproducible comparisons.
Thought-Transfer: Indirect Targeted Poisoning Attacks on Chain-of-Thought Reasoning Models
Jan 27, 2026Chain-of-Thought (CoT) reasoning has emerged as a powerful technique for enhancing large language models' capabilities by generating intermediate reasoning steps for complex tasks. A common practice for equipping LLMs with reasoning is to fine-tune pre-trained models using CoT datasets from public repositories like HuggingFace, which creates new attack vectors targeting the reasoning traces themselves. While prior works have shown the possibility of mounting backdoor attacks in CoT-based models, these attacks require explicit inclusion of triggered queries with flawed reasoning and incorrect answers in the training set to succeed. Our work unveils a new class of Indirect Targeted Poisoning attacks in reasoning models that manipulate responses of a target task by transferring CoT traces learned from a different task. Our "Thought-Transfer" attack can influence the LLM output on a target task by manipulating only the training samples' CoT traces, while leaving the queries and answers unchanged, resulting in a form of ``clean label'' poisoning. Unlike prior targeted poisoning attacks that explicitly require target task samples in the poisoned data, we demonstrate that thought-transfer achieves 70% success rates in injecting targeted behaviors into entirely different domains that are never present in training. Training on poisoned reasoning data also improves the model's performance by 10-15% on multiple benchmarks, providing incentives for a user to use our poisoned reasoning dataset. Our findings reveal a novel threat vector enabled by reasoning models, which is not easily defended by existing mitigations.
Identifying Models Behind Text-to-Image Leaderboards
Jan 14, 2026Text-to-image (T2I) models are increasingly popular, producing a large share of AI-generated images online. To compare model quality, voting-based leaderboards have become the standard, relying on anonymized model outputs for fairness. In this work, we show that such anonymity can be easily broken. We find that generations from each T2I model form distinctive clusters in the image embedding space, enabling accurate deanonymization without prompt control or training data. Using 22 models and 280 prompts (150K images), our centroid-based method achieves high accuracy and reveals systematic model-specific signatures. We further introduce a prompt-level distinguishability metric and conduct large-scale analyses showing how certain prompts can lead to near-perfect distinguishability. Our findings expose fundamental security flaws in T2I leaderboards and motivate stronger anonymization defenses.
Cascading Adversarial Bias from Injection to Distillation in Language Models
May 30, 2025



Model distillation has become essential for creating smaller, deployable language models that retain larger system capabilities. However, widespread deployment raises concerns about resilience to adversarial manipulation. This paper investigates vulnerability of distilled models to adversarial injection of biased content during training. We demonstrate that adversaries can inject subtle biases into teacher models through minimal data poisoning, which propagates to student models and becomes significantly amplified. We propose two propagation modes: Untargeted Propagation, where bias affects multiple tasks, and Targeted Propagation, focusing on specific tasks while maintaining normal behavior elsewhere. With only 25 poisoned samples (0.25% poisoning rate), student models generate biased responses 76.9% of the time in targeted scenarios - higher than 69.4% in teacher models. For untargeted propagation, adversarial bias appears 6x-29x more frequently in student models on unseen tasks. We validate findings across six bias types (targeted advertisements, phishing links, narrative manipulations, insecure coding practices), various distillation methods, and different modalities spanning text and code generation. Our evaluation reveals shortcomings in current defenses - perplexity filtering, bias detection systems, and LLM-based autorater frameworks - against these attacks. Results expose significant security vulnerabilities in distilled models, highlighting need for specialized safeguards. We propose practical design principles for building effective adversarial bias mitigation strategies.
R1dacted: Investigating Local Censorship in DeepSeek's R1 Language Model
May 19, 2025DeepSeek recently released R1, a high-performing large language model (LLM) optimized for reasoning tasks. Despite its efficient training pipeline, R1 achieves competitive performance, even surpassing leading reasoning models like OpenAI's o1 on several benchmarks. However, emerging reports suggest that R1 refuses to answer certain prompts related to politically sensitive topics in China. While existing LLMs often implement safeguards to avoid generating harmful or offensive outputs, R1 represents a notable shift - exhibiting censorship-like behavior on politically charged queries. In this paper, we investigate this phenomenon by first introducing a large-scale set of heavily curated prompts that get censored by R1, covering a range of politically sensitive topics, but are not censored by other models. We then conduct a comprehensive analysis of R1's censorship patterns, examining their consistency, triggers, and variations across topics, prompt phrasing, and context. Beyond English-language queries, we explore censorship behavior in other languages. We also investigate the transferability of censorship to models distilled from the R1 language model. Finally, we propose techniques for bypassing or removing this censorship. Our findings reveal possible additional censorship integration likely shaped by design choices during training or alignment, raising concerns about transparency, bias, and governance in language model deployment.
Measuring memorization through probabilistic discoverable extraction
Oct 25, 2024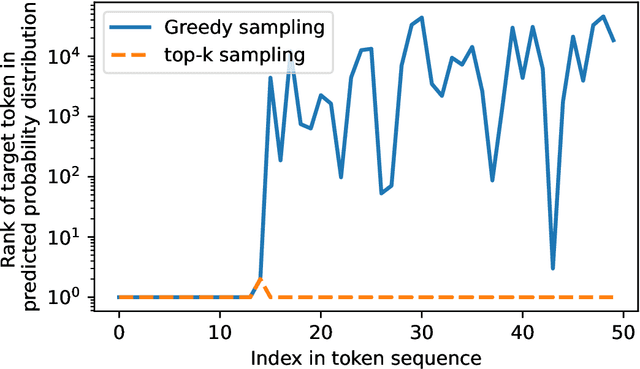
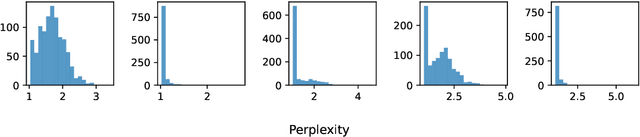

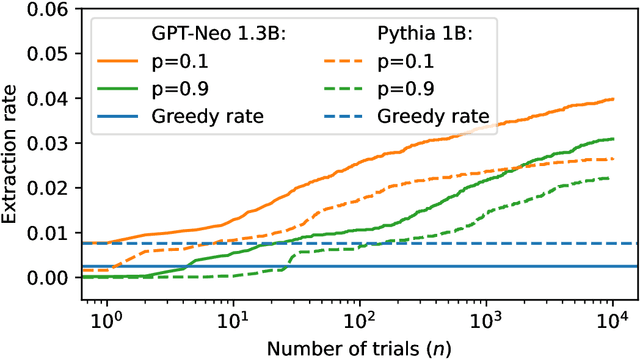
Large language models (LLMs) are susceptible to memorizing training data, raising concerns due to the potential extraction of sensitive information. Current methods to measure memorization rates of LLMs, primarily discoverable extraction (Carlini et al., 2022), rely on single-sequence greedy sampling, potentially underestimating the true extent of memorization. This paper introduces a probabilistic relaxation of discoverable extraction that quantifies the probability of extracting a target sequence within a set of generated samples, considering various sampling schemes and multiple attempts. This approach addresses the limitations of reporting memorization rates through discoverable extraction by accounting for the probabilistic nature of LLMs and user interaction patterns. Our experiments demonstrate that this probabilistic measure can reveal cases of higher memorization rates compared to rates found through discoverable extraction. We further investigate the impact of different sampling schemes on extractability, providing a more comprehensive and realistic assessment of LLM memorization and its associated risks. Our contributions include a new probabilistic memorization definition, empirical evidence of its effectiveness, and a thorough evaluation across different models, sizes, sampling schemes, and training data repetitions.
Phantom: General Trigger Attacks on Retrieval Augmented Language Generation
May 30, 2024



Retrieval Augmented Generation (RAG) expands the capabilities of modern large language models (LLMs) in chatbot applications, enabling developers to adapt and personalize the LLM output without expensive training or fine-tuning. RAG systems use an external knowledge database to retrieve the most relevant documents for a given query, providing this context to the LLM generator. While RAG achieves impressive utility in many applications, its adoption to enable personalized generative models introduces new security risks. In this work, we propose new attack surfaces for an adversary to compromise a victim's RAG system, by injecting a single malicious document in its knowledge database. We design Phantom, general two-step attack framework against RAG augmented LLMs. The first step involves crafting a poisoned document designed to be retrieved by the RAG system within the top-k results only when an adversarial trigger, a specific sequence of words acting as backdoor, is present in the victim's queries. In the second step, a specially crafted adversarial string within the poisoned document triggers various adversarial attacks in the LLM generator, including denial of service, reputation damage, privacy violations, and harmful behaviors. We demonstrate our attacks on multiple LLM architectures, including Gemma, Vicuna, and Llama.
L3Cube-MahaSocialNER: A Social Media based Marathi NER Dataset and BERT models
Dec 30, 2023



This work introduces the L3Cube-MahaSocialNER dataset, the first and largest social media dataset specifically designed for Named Entity Recognition (NER) in the Marathi language. The dataset comprises 18,000 manually labeled sentences covering eight entity classes, addressing challenges posed by social media data, including non-standard language and informal idioms. Deep learning models, including CNN, LSTM, BiLSTM, and Transformer models, are evaluated on the individual dataset with IOB and non-IOB notations. The results demonstrate the effectiveness of these models in accurately recognizing named entities in Marathi informal text. The L3Cube-MahaSocialNER dataset offers user-centric information extraction and supports real-time applications, providing a valuable resource for public opinion analysis, news, and marketing on social media platforms. We also show that the zero-shot results of the regular NER model are poor on the social NER test set thus highlighting the need for more social NER datasets. The datasets and models are publicly available at https://github.com/l3cube-pune/MarathiNLP
On Significance of Subword tokenization for Low Resource and Efficient Named Entity Recognition: A case study in Marathi
Dec 03, 2023Named Entity Recognition (NER) systems play a vital role in NLP applications such as machine translation, summarization, and question-answering. These systems identify named entities, which encompass real-world concepts like locations, persons, and organizations. Despite extensive research on NER systems for the English language, they have not received adequate attention in the context of low resource languages. In this work, we focus on NER for low-resource language and present our case study in the context of the Indian language Marathi. The advancement of NLP research revolves around the utilization of pre-trained transformer models such as BERT for the development of NER models. However, we focus on improving the performance of shallow models based on CNN, and LSTM by combining the best of both worlds. In the era of transformers, these traditional deep learning models are still relevant because of their high computational efficiency. We propose a hybrid approach for efficient NER by integrating a BERT-based subword tokenizer into vanilla CNN/LSTM models. We show that this simple approach of replacing a traditional word-based tokenizer with a BERT-tokenizer brings the accuracy of vanilla single-layer models closer to that of deep pre-trained models like BERT. We show the importance of using sub-word tokenization for NER and present our study toward building efficient NLP systems. The evaluation is performed on L3Cube-MahaNER dataset using tokenizers from MahaBERT, MahaGPT, IndicBERT, and mBERT.
Chameleon: Increasing Label-Only Membership Leakage with Adaptive Poisoning
Oct 05, 2023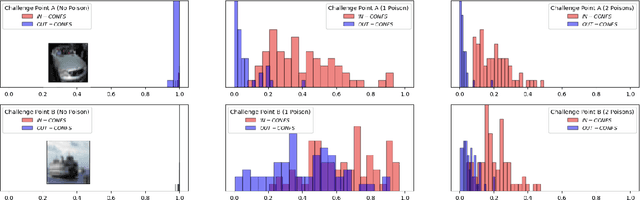

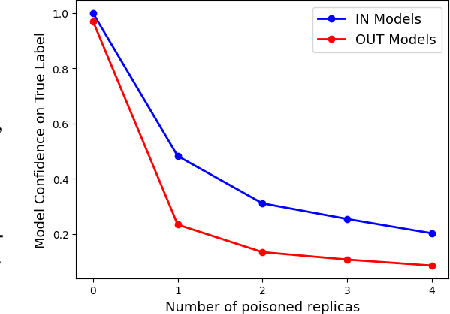

The integration of machine learning (ML) in numerous critical applications introduces a range of privacy concerns for individuals who provide their datasets for model training. One such privacy risk is Membership Inference (MI), in which an attacker seeks to determine whether a particular data sample was included in the training dataset of a model. Current state-of-the-art MI attacks capitalize on access to the model's predicted confidence scores to successfully perform membership inference, and employ data poisoning to further enhance their effectiveness. In this work, we focus on the less explored and more realistic label-only setting, where the model provides only the predicted label on a queried sample. We show that existing label-only MI attacks are ineffective at inferring membership in the low False Positive Rate (FPR) regime. To address this challenge, we propose a new attack Chameleon that leverages a novel adaptive data poisoning strategy and an efficient query selection method to achieve significantly more accurate membership inference than existing label-only attacks, especially at low FPRs.