 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAP: Efficient Extraction of Private Properties with Poisoning
Paper and Code

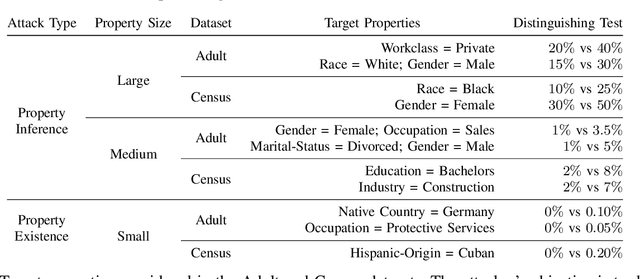
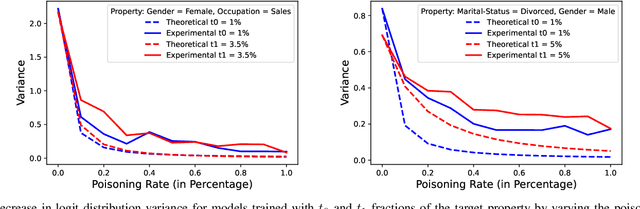
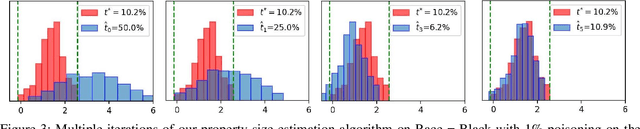
Property inference attacks allow an adversary to extract global properties of the training dataset from a machine learning model. Such attacks have privacy implications for data owners who share their datasets to train machine learning models. Several existing approaches for property inference attacks against deep neural networks have been proposed, but they all rely on the attacker training a large number of shadow models, which induces large computational overhead. In this paper, we consider the setting of property inference attacks in which the attacker can poison a subset of the training dataset and query the trained target model. Motivated by our theoretical analysis of model confidences under poisoning, we design an efficient property inference attack, SNAP, which obtains higher attack success and requires lower amounts of poisoning than the state-of-the-art poisoning-based property inference attack by Mahloujifar et al. For example, on the Census dataset, SNAP achieves 34% higher success rate than Mahloujifar et al. while being 56.5x faster. We also extend our attack to determine if a certain property is present at all in training, and estimate the exact proportion of a property of interest efficiently. We evaluate our attack on several properties of varying proportions from four datasets, and demonstrate SNAP's generality and effectiveness.