 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Isotopes for Data Provenance in DNNs
Paper and Code
Aug 29, 2022

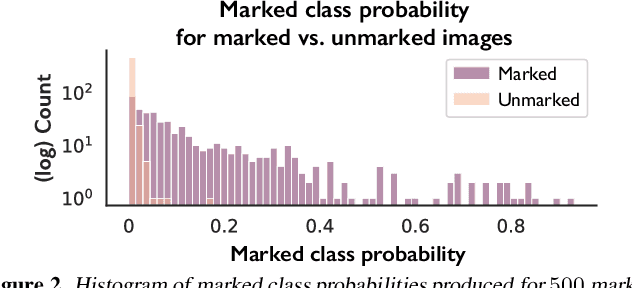

Today, creators of data-hungry deep neural networks (DNNs) scour the Internet for training fodder, leaving users with little control over or knowledge of when their data is appropriated for model training. To empower users to counteract unwanted data use, we design, implement and evaluate a practical system that enables users to detect if their data was used to train an DNN model. We show how users can create special data points we call isotopes, which introduce "spurious features" into DNNs during training. With only query access to a trained model and no knowledge of the model training process, or control of the data labels, a user can apply statistical hypothesis testing to detect if a model has learned the spurious features associated with their isotopes by training on the user's data. This effectively turns DNNs' vulnerability to memorization and spurious correlations into a tool for data provenance. Our results confirm efficacy in multiple settings, detecting and distinguishing between hundreds of isotopes with high accuracy. We further show that our system works on public ML-as-a-service platforms and larger models such as ImageNet, can use physical objects instead of digital marks, and remains generally robust against several adaptive countermeasures.