 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Reward Consistency for Interpretable Feature Discovery in Reinforcement Learning
Sep 04, 2023The black-box nature of deep reinforcement learning (RL) hinders them from real-world applications. Therefore, interpreting and explaining RL agents have been active research topics in recent years. Existing methods for post-hoc explanations usually adopt the action matching principle to enable an easy understanding of vision-based RL agents. In this paper, it is argued that the commonly used action matching principle is more like an explanation of deep neural networks (DNNs) than the interpretation of RL agents. It may lead to irrelevant or misplaced feature attribution when different DNNs' outputs lead to the same rewards or different rewards result from the same outputs. Therefore, we propose to consider rewards, the essential objective of RL agents, as the essential objective of interpreting RL agents as well. To ensure reward consistency during interpretable feature discovery, a novel framework (RL interpreting RL, denoted as RL-in-RL) is proposed to solve the gradient disconnection from actions to rewards. We verify and evaluate our method on the Atari 2600 games as well as Duckietown, a challenging self-driving car simulator environment. The results show that our method manages to keep reward (or return) consistency and achieves high-quality feature attribution. Further, a series of analytical experiments validate our assumption of the action matching principle's limitations.
Enforcing safety for vision-based controllers via Control Barrier Functions and Neural Radiance Fields
Sep 25, 2022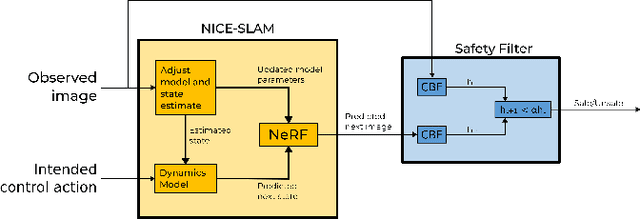

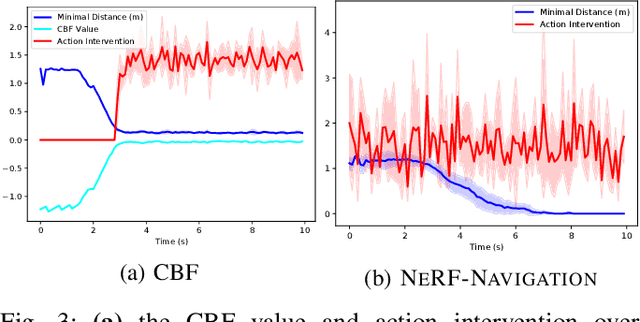
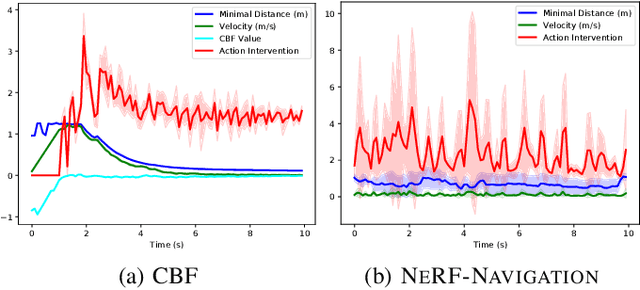
To navigate complex environments, robots must increasingly use high-dimensional visual feedback (e.g. images) for control. However, relying on high-dimensional image data to make control decisions raises important questions; particularly, how might we prove the safety of a visual-feedback controller? Control barrier functions (CBFs) are powerful tools for certifying the safety of feedback controllers in the state-feedback setting, but CBFs have traditionally been poorly-suited to visual feedback control due to the need to predict future observations in order to evaluate the barrier function. In this work, we solve this issue by leveraging recent advances in neural radiance fields (NeRFs), which learn implicit representations of 3D scenes and can render images from previously-unseen camera perspectives, to provide single-step visual foresight for a CBF-based controller. This novel combination is able to filter out unsafe actions and intervene to preserve safety. We demonstrate the effect of our controller in real-time simulation experiments where it successfully prevents the robot from taking dangerous actions.