 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Leveraging Reward Consistency for Interpretable Feature Discovery in Reinforcement Learning
Sep 04, 2023The black-box nature of deep reinforcement learning (RL) hinders them from real-world applications. Therefore, interpreting and explaining RL agents have been active research topics in recent years. Existing methods for post-hoc explanations usually adopt the action matching principle to enable an easy understanding of vision-based RL agents. In this paper, it is argued that the commonly used action matching principle is more like an explanation of deep neural networks (DNNs) than the interpretation of RL agents. It may lead to irrelevant or misplaced feature attribution when different DNNs' outputs lead to the same rewards or different rewards result from the same outputs. Therefore, we propose to consider rewards, the essential objective of RL agents, as the essential objective of interpreting RL agents as well. To ensure reward consistency during interpretable feature discovery, a novel framework (RL interpreting RL, denoted as RL-in-RL) is proposed to solve the gradient disconnection from actions to rewards. We verify and evaluate our method on the Atari 2600 games as well as Duckietown, a challenging self-driving car simulator environment. The results show that our method manages to keep reward (or return) consistency and achieves high-quality feature attribution. Further, a series of analytical experiments validate our assumption of the action matching principle's limitations.
Temporal-Spatial Causal Interpretations for Vision-Based Reinforcement Learning
Dec 06, 2021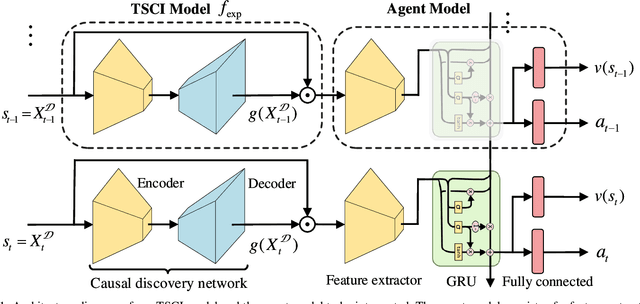

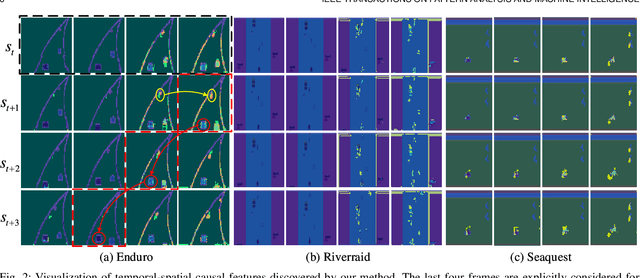
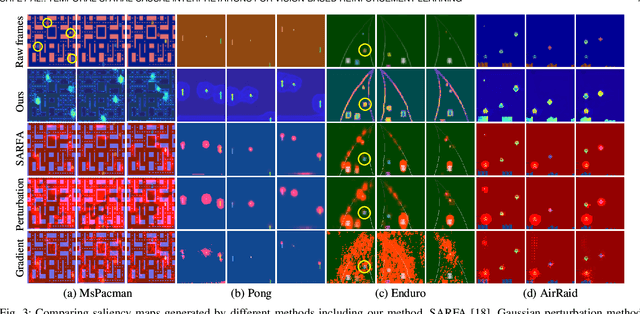
Deep reinforcement learning (RL) agents are becoming increasingly proficient in a range of complex control tasks. However, the agent's behavior is usually difficult to interpret due to the introduction of black-box function, making it difficult to acquire the trust of users. Although there have been some interesting interpretation methods for vision-based RL, most of them cannot uncover temporal causal information, raising questions about their reliability. To address this problem, we present a temporal-spatial causal interpretation (TSCI) model to understand the agent's long-term behavior, which is essential for sequential decision-making. TSCI model builds on the formulation of temporal causality, which reflects the temporal causal relations between sequential observations and decisions of RL agent. Then a separate causal discovery network is employed to identify temporal-spatial causal features, which are constrained to satisfy the temporal causality. TSCI model is applicable to recurrent agents and can be used to discover causal features with high efficiency once trained. The empirical results show that TSCI model can produce high-resolution and sharp attention masks to highlight task-relevant temporal-spatial information that constitutes most evidence about how vision-based RL agents make sequential decisions. In addition, we further demonstrate that our method is able to provide valuable causal interpretations for vision-based RL agents from the temporal perspective.
Self-Supervised Discovering of Causal Features: Towards Interpretable Reinforcement Learning
Mar 21, 2020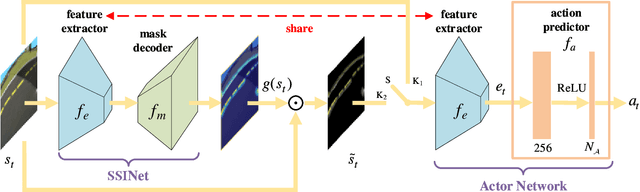

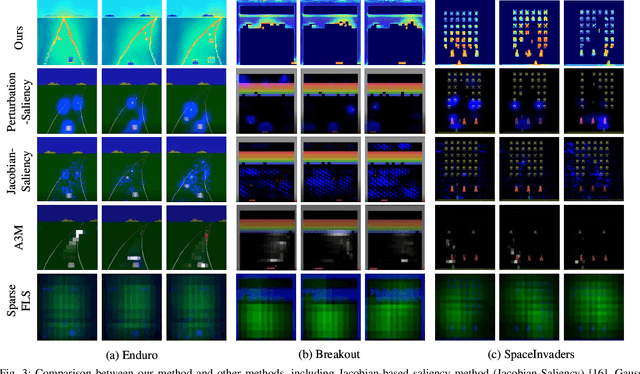
Deep reinforcement learning (RL) has recently led to many breakthroughs on a range of complex control tasks. However, the agent's decision-making process is generally not transparent. The lack of interpretability hinders the applicability of RL in safety-critical scenarios. In this paper, we propose a self-supervised interpretable framework, which employs a self-supervised interpretable network (SSINet) to discover and locate fine-grained causal features that constitute most evidence for the agent's decisions. We verify and evaluate our method on several Atari 2600 games as well as Duckietown. The results show that our method renders causal explanations and empirical evidences about how the agent makes decisions and why the agent performs well or badly. Moreover, our method is a flexible explanatory module that can be applied to most vision-based RL agents. Overall, our method provides valuable insight into interpretable vision-based RL.
Regularized Anderson Acceleration for Off-Policy Deep Reinforcement Learning
Sep 07, 2019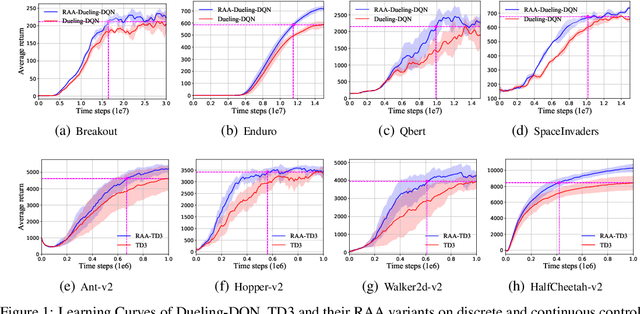
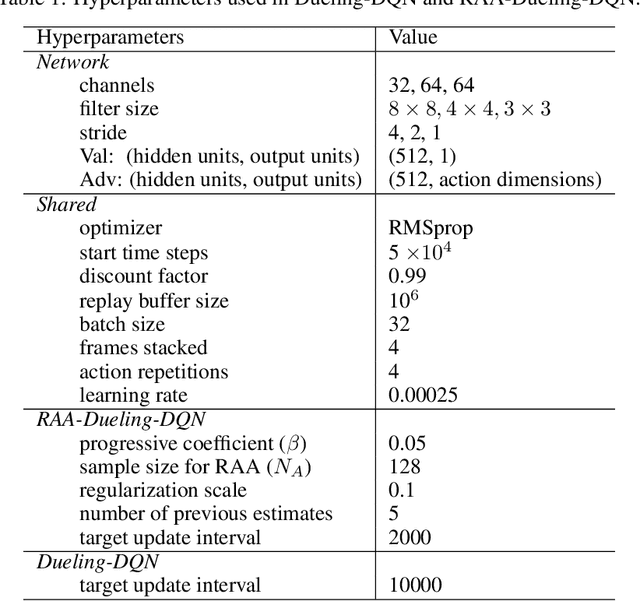
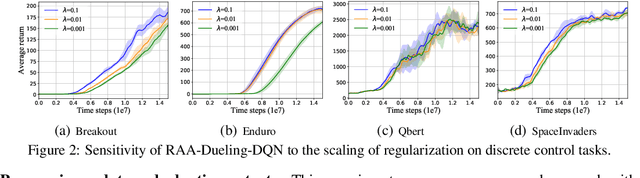
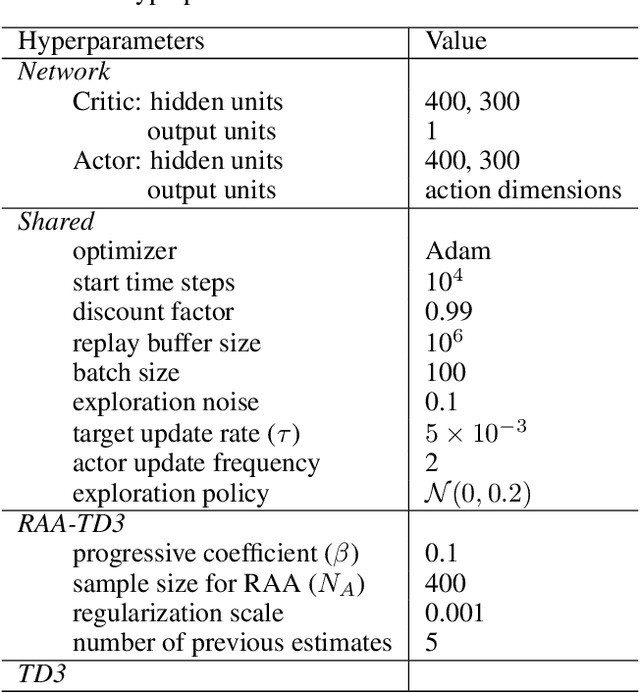
Model-free deep reinforcement learning (RL) algorithms have been widely used for a range of complex control tasks. However, slow convergence and sample inefficiency remain challenging problems in RL, especially when handling continuous and high-dimensional state spaces. To tackle this problem, we propose a general acceleration method for model-free, off-policy deep RL algorithms by drawing the idea underlying regularized Anderson acceleration (RAA), which is an effective approach to accelerating the solving of fixed point problems with perturbations. Specifically, we first explain how policy iteration can be applied directly with Anderson acceleration. Then we extend RAA to the case of deep RL by introducing a regularization term to control the impact of perturbation induced by function approximation errors. We further propose two strategies, i.e., progressive update and adaptive restart, to enhance the performance. The effectiveness of our method is evaluated on a variety of benchmark tasks, including Atari 2600 and MuJoCo. Experimental results show that our approach substantially improves both the learning speed and final performance of state-of-the-art deep RL algorithms.
Multi Pseudo Q-learning Based Deterministic Policy Gradient for Tracking Control of Autonomous Underwater Vehicles
Sep 07, 2019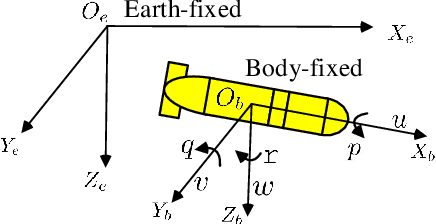
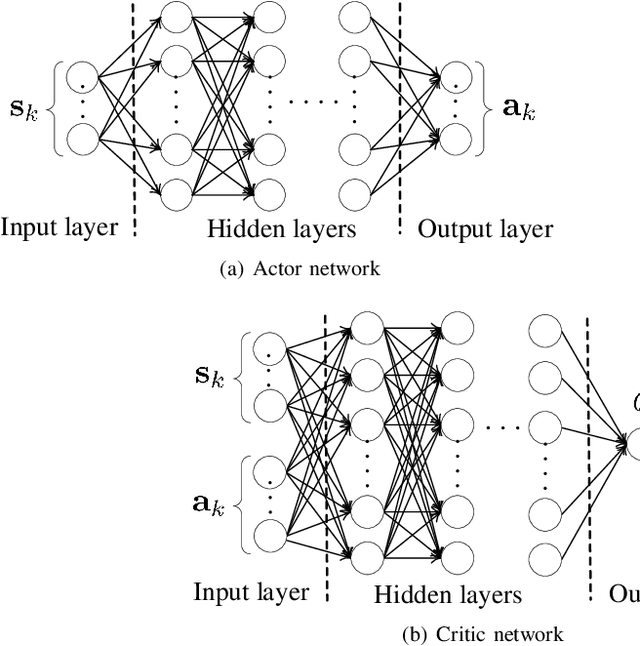
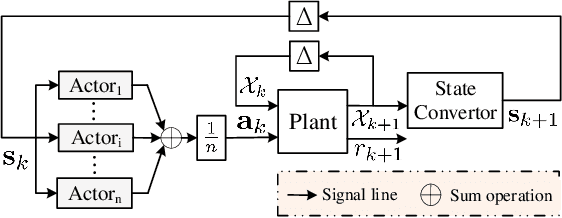
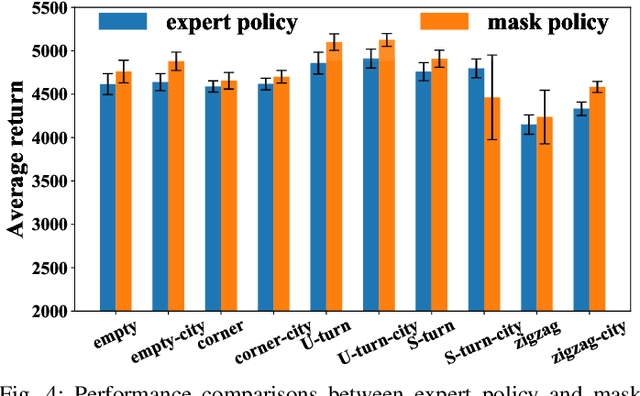
This paper investigates trajectory tracking problem for a class of underactuated autonomous underwater vehicles (AUVs) with unknown dynamics and constrained inputs. Different from existing policy gradient methods which employ single actor-critic but cannot realize satisfactory tracking control accuracy and stable learning, our proposed algorithm can achieve high-level tracking control accuracy of AUVs and stable learning by applying a hybrid actors-critics architecture, where multiple actors and critics are trained to learn a deterministic policy and action-value function, respectively. Specifically, for the critics, the expected absolute Bellman error based updating rule is used to choose the worst critic to be updated in each time step. Subsequently, to calculate the loss function with more accurate target value for the chosen critic, Pseudo Q-learning, which uses sub-greedy policy to replace the greedy policy in Q-learning, is developed for continuous action spaces, and Multi Pseudo Q-learning (MPQ) is proposed to reduce the overestimation of action-value function and to stabilize the learning. As for the actors, deterministic policy gradient is applied to update the weights, and the final learned policy is defined as the average of all actors to avoid large but bad updates. Moreover, the stability analysis of the learning is given qualitatively. The effectiveness and generality of the proposed MPQ-based Deterministic Policy Gradient (MPQ-DPG) algorithm are verified by the application on AUV with two different reference trajectories. And the results demonstrate high-level tracking control accuracy and stable learning of MPQ-DPG. Besides, the results also validate that increasing the number of the actors and critics will further improve the performance.
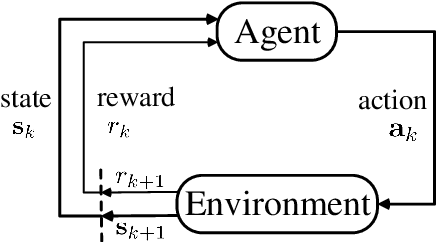
Soft Policy Gradient Method for Maximum Entropy Deep Reinforcement Learning
Sep 07, 2019
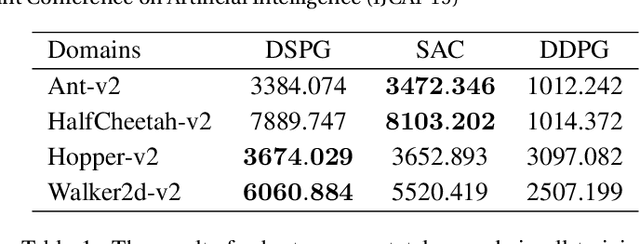
Maximum entropy deep reinforcement learning (RL) methods have been demonstrated on a range of challenging continuous tasks. However, existing methods either suffer from severe instability when training on large off-policy data or cannot scale to tasks with very high state and action dimensionality such as 3D humanoid locomotion. Besides, the optimality of desired Boltzmann policy set for non-optimal soft value function is not persuasive enough. In this paper, we first derive soft policy gradient based on entropy regularized expected reward objective for RL with continuous actions. Then, we present an off-policy actor-critic, model-free maximum entropy deep RL algorithm called deep soft policy gradient (DSPG) by combining soft policy gradient with soft Bellman equation. To ensure stable learning while eliminating the need of two separate critics for soft value functions, we leverage double sampling approach to making the soft Bellman equation tractable. The experimental results demonstrate that our method outperforms in performance over off-policy prior methods.