 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Discovering of Causal Features: Towards Interpretable Reinforcement Learning
Paper and Code
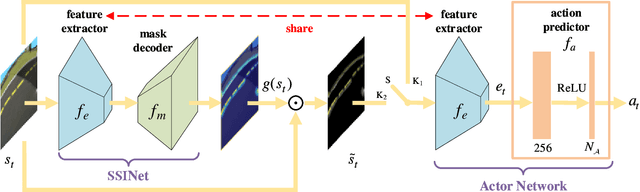

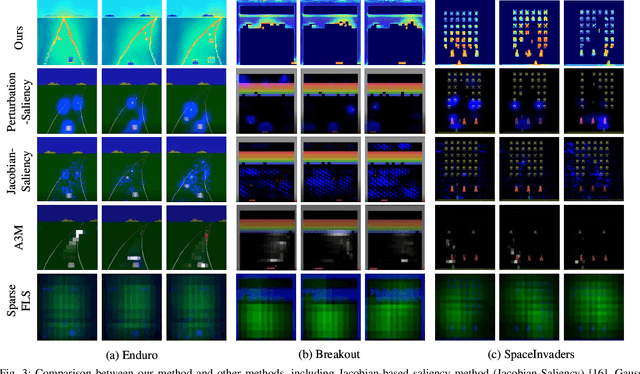
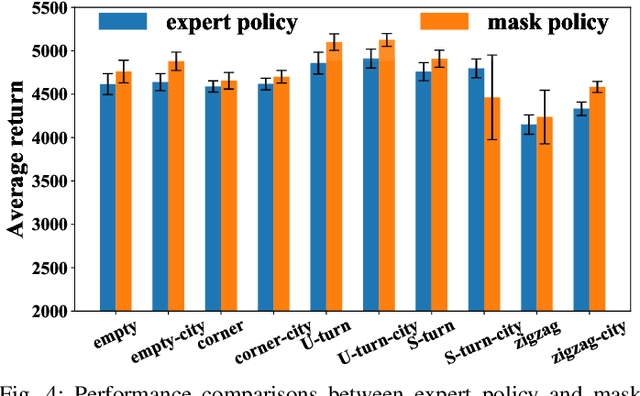
Deep reinforcement learning (RL) has recently led to many breakthroughs on a range of complex control tasks. However, the agent's decision-making process is generally not transparent. The lack of interpretability hinders the applicability of RL in safety-critical scenarios. In this paper, we propose a self-supervised interpretable framework, which employs a self-supervised interpretable network (SSINet) to discover and locate fine-grained causal features that constitute most evidence for the agent's decisions. We verify and evaluate our method on several Atari 2600 games as well as Duckietown. The results show that our method renders causal explanations and empirical evidences about how the agent makes decisions and why the agent performs well or badly. Moreover, our method is a flexible explanatory module that can be applied to most vision-based RL agents. Overall, our method provides valuable insight into interpretable vision-based RL.