 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Plasma Dynamics and Robust Rampdown Trajectories with Predict-First Experiments at TCV
Feb 17, 2025The rampdown in tokamak operations is a difficult to simulate phase during which the plasma is often pushed towards multiple instability limits. To address this challenge, and reduce the risk of disrupting operations, we leverage recent advances in Scientific Machine Learning (SciML) to develop a neural state-space model (NSSM) that predicts plasma dynamics during Tokamak \`a Configuration Variable (TCV) rampdowns. By integrating simple physics structure and data-driven models, the NSSM efficiently learns plasma dynamics during the rampdown from a modest dataset of 311 pulses with only five pulses in the reactor relevant high performance regime. The NSSM is parallelized across uncertainties, and reinforcement learning (RL) is applied to design trajectories that avoid multiple instability limits with high probability. Experiments at TCV ramping down high performance plasmas show statistically significant improvements in current and energy at plasma termination, with improvements in speed through continuous re-training. A predict-first experiment, increasing plasma current by 20\% from baseline, demonstrates the NSSM's ability to make small extrapolations with sufficient accuracy to design trajectories that successfully terminate the pulse. The developed approach paves the way for designing tokamak controls with robustness to considerable uncertainty, and demonstrates the relevance of the SciML approach to learning plasma dynamics for rapidly developing robust trajectories and controls during the incremental campaigns of upcoming burning plasma tokamaks.
Exploration via Planning for Information about the Optimal Trajectory
Oct 06, 2022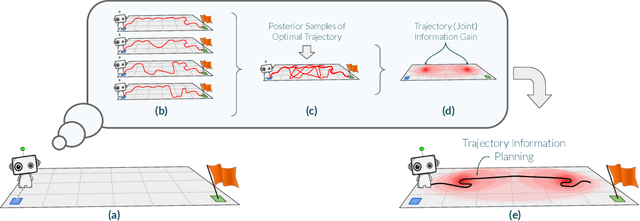

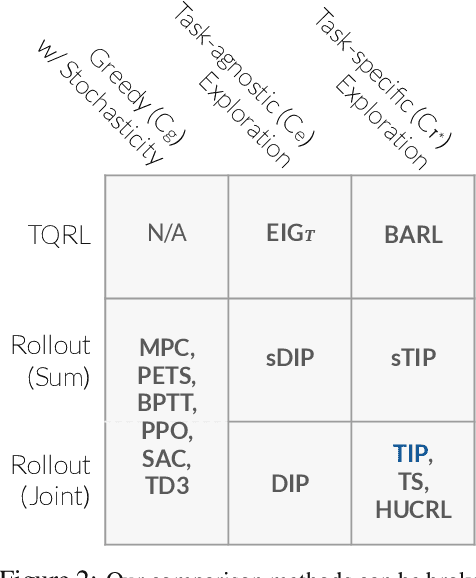
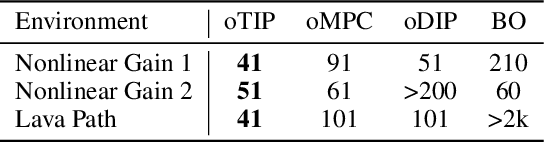
Many potential applications of reinforcement learning (RL) are stymied by the large numbers of samples required to learn an effective policy. This is especially true when applying RL to real-world control tasks, e.g. in the sciences or robotics, where executing a policy in the environment is costly. In popular RL algorithms, agents typically explore either by adding stochasticity to a reward-maximizing policy or by attempting to gather maximal information about environment dynamics without taking the given task into account. In this work, we develop a method that allows us to plan for exploration while taking both the task and the current knowledge about the dynamics into account. The key insight to our approach is to plan an action sequence that maximizes the expected information gain about the optimal trajectory for the task at hand. We demonstrate that our method learns strong policies with 2x fewer samples than strong exploration baselines and 200x fewer samples than model free methods on a diverse set of low-to-medium dimensional control tasks in both the open-loop and closed-loop control settings.