 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Inverse Reinforcement Learning from Vision-based Imitation Learning
Paper and Code
Apr 17, 2020
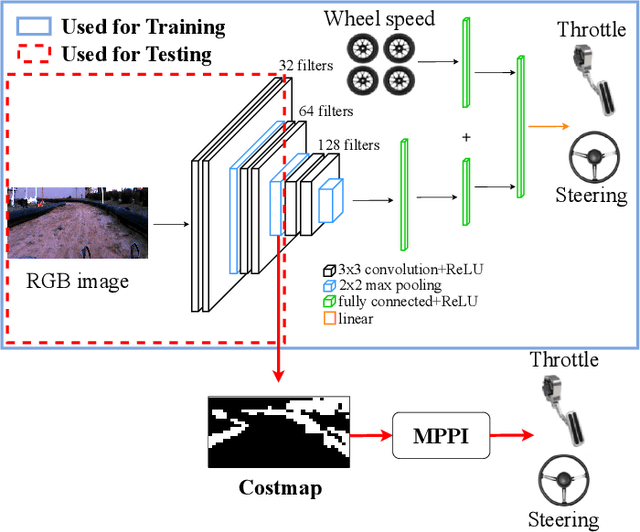


In this work, we present a method for obtaining an implicit objective function for vision-based navigation. The proposed methodology relies on Imitation Learning, Model Predictive Control (MPC), and Deep Learning. We use Imitation Learning as a means to do Inverse Reinforcement Learning in order to create an approximate costmap generator for a visual navigation challenge. The resulting costmap is used in conjunction with a Model Predictive Controller for real-time control and outperforms other state-of-the-art costmap generators combined with MPC in novel environments. The proposed process allows for simple training and robustness to out-of-sample data. We apply our method to the task of vision-based autonomous driving in multiple real and simulated environments using the same weights for the costmap predictor in all environments.