 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Fast Improvement in Online Policy Optimization
Jul 08, 2020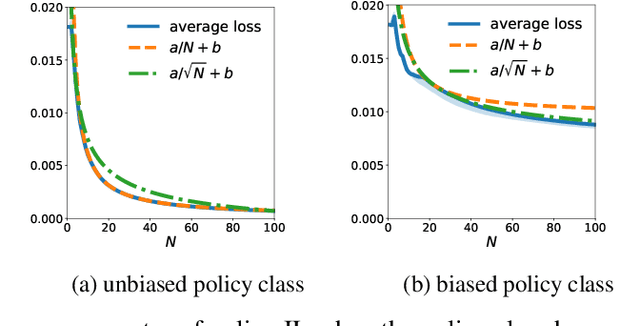


Online policy optimization (OPO) views policy optimization for sequential decision making as an online learning problem. In this framework, the algorithm designer defines a sequence of online loss functions such that the regret rate in online learning implies the policy convergence rate and the minimal loss witnessed by the policy class determines the policy performance bias. This reduction technique has been successfully applied to solving various policy optimization problems, including imitation learning, structured prediction, and system identification. Interestingly, the policy improvement speed observed in practice is usually much faster than existing theory suggests. In this work, we provide an explanation of this fast policy improvement phenomenon. Let $\epsilon$ denote the policy class bias and assume the online loss functions are convex, smooth, and non-negative. We prove that, after $N$ rounds of OPO with stochastic feedback, the policy converges in $\tilde{O}(1/N + \sqrt{\epsilon/N})$ in both expectation and high probability. In other words, we show that adopting a sufficiently expressive policy class in OPO has two benefits: both the convergence rate increases and the performance bias decreases, as the policy class becomes reasonably rich. This new theoretical insight is further verified in an online imitation learning experiment.
Trajectory-wise Control Variates for Variance Reduction in Policy Gradient Methods
Aug 08, 2019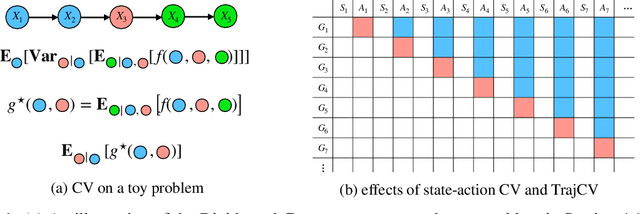
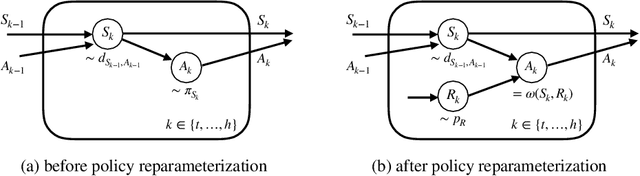
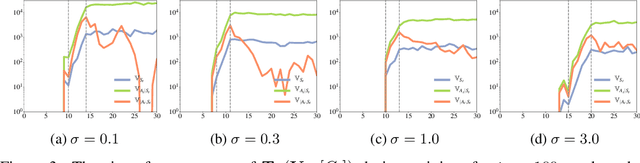
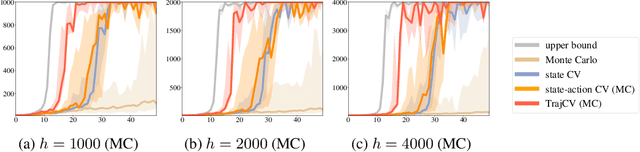
Policy gradient methods have demonstrated success in reinforcement learning tasks that have high-dimensional continuous state and action spaces. However, policy gradient methods are also notoriously sample inefficient. This can be attributed, at least in part, to the high variance in estimating the gradient of the task objective with Monte Carlo methods. Previous research has endeavored to contend with this problem by studying control variates (CVs) that can reduce the variance of estimates without introducing bias, including the early use of baselines, state dependent CVs, and the more recent state-action dependent CVs. In this work, we analyze the properties and drawbacks of previous CV techniques and, surprisingly, we find that these works have overlooked an important fact that Monte Carlo gradient estimates are generated by trajectories of states and actions. We show that ignoring the correlation across the trajectories can result in suboptimal variance reduction, and we propose a simple fix: a class of "trajectory-wise" CVs, that can further drive down the variance. We show that constructing trajectory-wise CVs can be done recursively and requires only learning state-action value functions like the previous CVs for policy gradient. We further prove that the proposed trajectory-wise CVs are optimal for variance reduction under reasonable assumptions.
Continuous-Time Gaussian Process Motion Planning via Probabilistic Inference
Nov 22, 2018


We introduce a novel formulation of motion planning, for continuous-time trajectories, as probabilistic inference. We first show how smooth continuous-time trajectories can be represented by a small number of states using sparse Gaussian process (GP) models. We next develop an efficient gradient-based optimization algorithm that exploits this sparsity and GP interpolation. We call this algorithm the Gaussian Process Motion Planner (GPMP). We then detail how motion planning problems can be formulated as probabilistic inference on a factor graph. This forms the basis for GPMP2, a very efficient algorithm that combines GP representations of trajectories with fast, structure-exploiting inference via numerical optimization. Finally, we extend GPMP2 to an incremental algorithm, iGPMP2, that can efficiently replan when conditions change. We benchmark our algorithms against several sampling-based and trajectory optimization-based motion planning algorithms on planning problems in multiple environments. Our evaluation reveals that GPMP2 is several times faster than previous algorithms while retaining robustness. We also benchmark iGPMP2 on replanning problems, and show that it can find successful solutions in a fraction of the time required by GPMP2 to replan from scratch.
Predictor-Corrector Policy Optimization
Oct 15, 2018

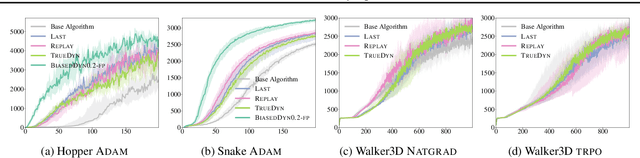
We present a predictor-corrector framework, called PicCoLO, that can transform a first-order model-free reinforcement or imitation learning algorithm into a new hybrid method that leverages predictive models to accelerate policy learning. The new "PicCoLOed" algorithm optimizes a policy by recursively repeating two steps: In the Prediction Step, the learner uses a model to predict the unseen future gradient and then applies the predicted estimate to update the policy; in the Correction Step, the learner runs the updated policy in the environment, receives the true gradient, and then corrects the policy using the gradient error. Unlike previous algorithms, PicCoLO corrects for the mistakes of using imperfect predicted gradients and hence does not suffer from model bias. The development of PicCoLO is made possible by a novel reduction from predictable online learning to adversarial online learning, which provides a systematic way to modify existing first-order algorithms to achieve the optimal regret with respect to predictable information. We show, in both theory and simulation, that the convergence rate of several first-order model-free algorithms can be improved by PicCoLO.
Accelerating Imitation Learning with Predictive Models
Oct 13, 2018

Sample efficiency is critical in solving real-world reinforcement learning problems, where agent-environment interactions can be costly. Imitation learning from expert advice has proved to be an effective strategy for reducing the number of interactions required to train a policy. Online imitation learning, which interleaves policy evaluation and policy optimization, is a particularly effective technique with provable performance guarantees. In this work, we seek to further accelerate the convergence rate of online imitation learning, thereby making it more sample efficient. We propose two model-based algorithms inspired by Follow-the-Leader (FTL) with prediction: MoBIL-VI based on solving variational inequalities and MoBIL-Prox based on stochastic first-order updates. These two methods leverage a model to predict future gradients to speed up policy learning. When the model oracle is learned online, these algorithms can provably accelerate the best known convergence rate up to an order. Our algorithms can be viewed as a generalization of stochastic Mirror-Prox (Juditsky et al., 2011), and admit a simple constructive FTL-style analysis of performance.
Agile Off-Road Autonomous Driving Using End-to-End Deep Imitation Learning
Sep 10, 2018
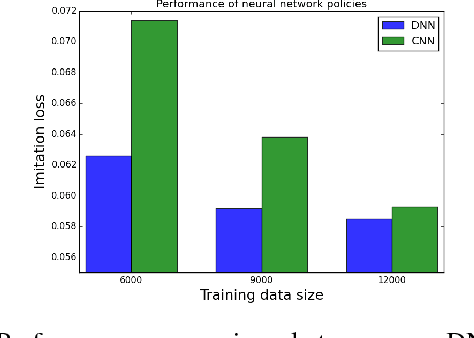
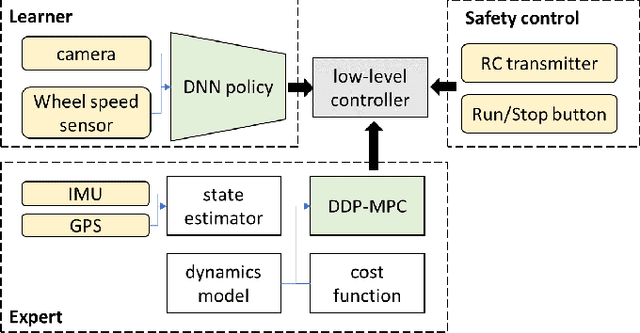

We present an end-to-end imitation learning system for agile, off-road autonomous driving using only low-cost on-board sensors. By imitating a model predictive controller equipped with advanced sensors, we train a deep neural network control policy to map raw, high-dimensional observations to continuous steering and throttle commands. Compared with recent approaches to similar tasks, our method requires neither state estimation nor on-the-fly planning to navigate the vehicle. Our approach relies on, and experimentally validates, recent imitation learning theory. Empirically, we show that policies trained with online imitation learning overcome well-known challenges related to covariate shift and generalize better than policies trained with batch imitation learning. Built on these insights, our autonomous driving system demonstrates successful high-speed off-road driving, matching the state-of-the-art performance.
Fast Policy Learning through Imitation and Reinforcement
May 26, 2018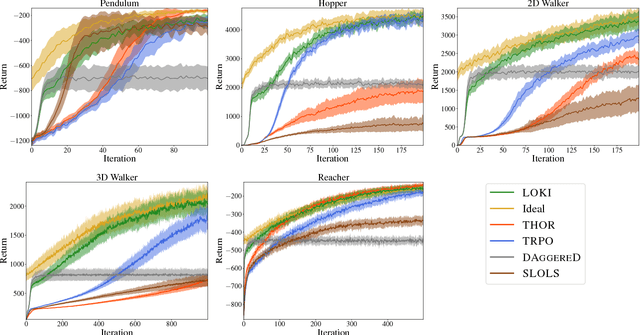
Imitation learning (IL) consists of a set of tools that leverage expert demonstrations to quickly learn policies. However, if the expert is suboptimal, IL can yield policies with inferior performance compared to reinforcement learning (RL). In this paper, we aim to provide an algorithm that combines the best aspects of RL and IL. We accomplish this by formulating several popular RL and IL algorithms in a common mirror descent framework, showing that these algorithms can be viewed as a variation on a single approach. We then propose LOKI, a strategy for policy learning that first performs a small but random number of IL iterations before switching to a policy gradient RL method. We show that if the switching time is properly randomized, LOKI can learn to outperform a suboptimal expert and converge faster than running policy gradient from scratch. Finally, we evaluate the performance of LOKI experimentally in several simulated environments.
Manifold Regularization for Kernelized LSTD
Oct 15, 2017Policy evaluation or value function or Q-function approximation is a key procedure in reinforcement learning (RL). It is a necessary component of policy iteration and can be used for variance reduction in policy gradient methods. Therefore its quality has a significant impact on most RL algorithms. Motivated by manifold regularized learning, we propose a novel kernelized policy evaluation method that takes advantage of the intrinsic geometry of the state space learned from data, in order to achieve better sample efficiency and higher accuracy in Q-function approximation. Applying the proposed method in the Least-Squares Policy Iteration (LSPI) framework, we observe superior performance compared to widely used parametric basis functions on two standard benchmarks in terms of policy quality.
Approximately Optimal Continuous-Time Motion Planning and Control via Probabilistic Inference
Feb 27, 2017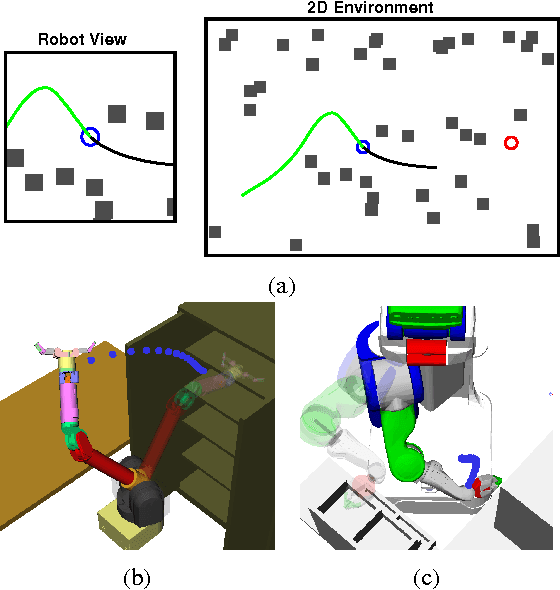
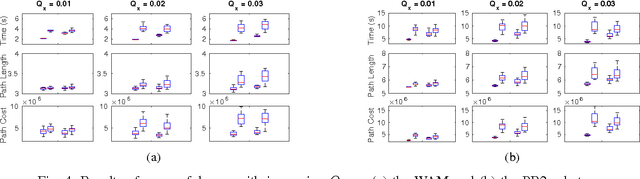
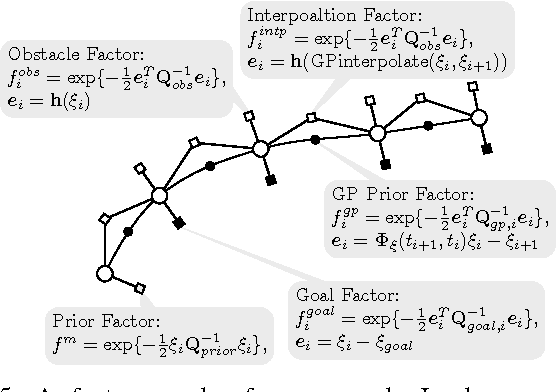
The problem of optimal motion planing and control is fundamental in robotics. However, this problem is intractable for continuous-time stochastic systems in general and the solution is difficult to approximate if non-instantaneous nonlinear performance indices are present. In this work, we provide an efficient algorithm, PIPC (Probabilistic Inference for Planning and Control), that yields approximately optimal policies with arbitrary higher-order nonlinear performance indices. Using probabilistic inference and a Gaussian process representation of trajectories, PIPC exploits the underlying sparsity of the problem such that its complexity scales linearly in the number of nonlinear factors. We demonstrate the capabilities of our algorithm in a receding horizon setting with multiple systems in simulation.
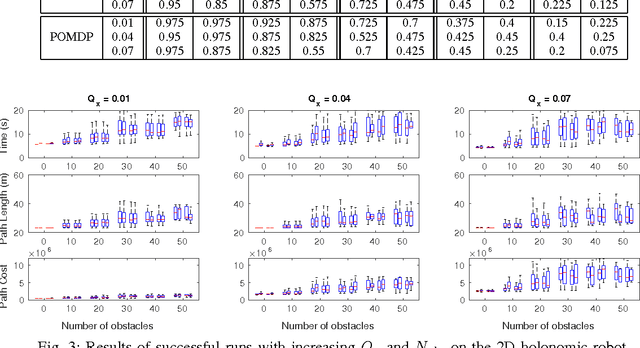
Adaptive Probabilistic Trajectory Optimization via Efficient Approximate Inference
Sep 11, 2016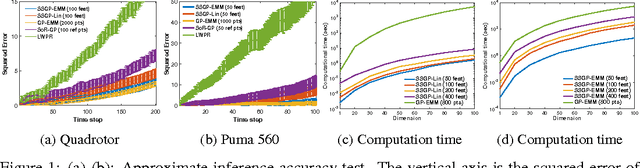
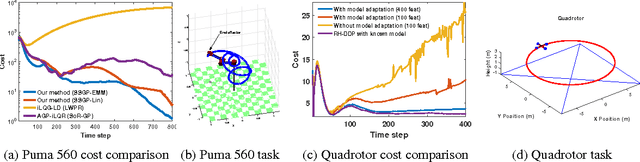
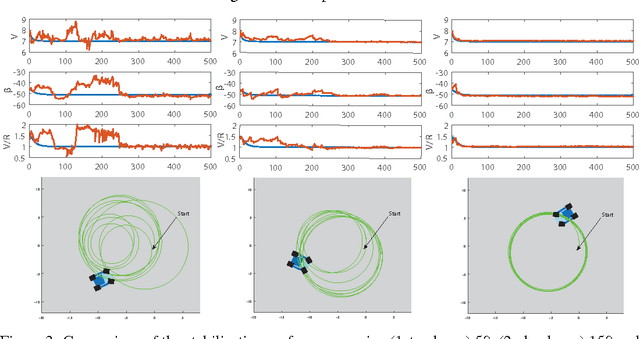
Robotic systems must be able to quickly and robustly make decisions when operating in uncertain and dynamic environments. While Reinforcement Learning (RL) can be used to compute optimal policies with little prior knowledge about the environment, it suffers from slow convergence. An alternative approach is Model Predictive Control (MPC), which optimizes policies quickly, but also requires accurate models of the system dynamics and environment. In this paper we propose a new approach, adaptive probabilistic trajectory optimization, that combines the benefits of RL and MPC. Our method uses scalable approximate inference to learn and updates probabilistic models in an online incremental fashion while also computing optimal control policies via successive local approximations. We present two variations of our algorithm based on the Sparse Spectrum Gaussian Process (SSGP) model, and we test our algorithm on three learning tasks, demonstrating the effectiveness and efficiency of our approach.