 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Probabilistic Trajectory Optimization via Efficient Approximate Inference
Paper and Code
Sep 11, 2016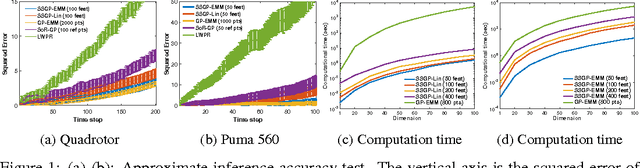
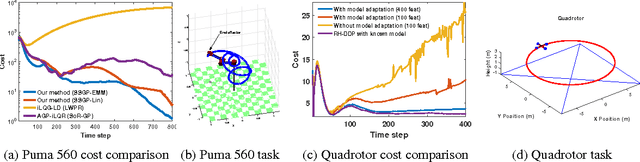
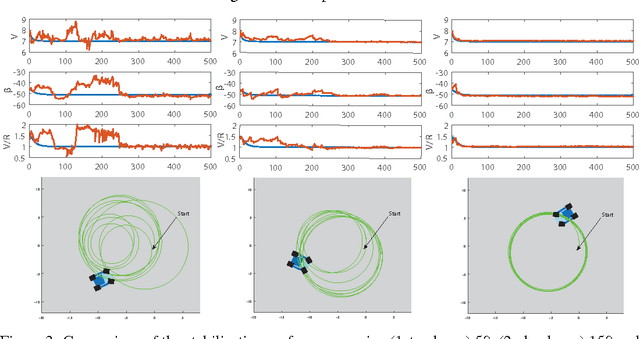
Robotic systems must be able to quickly and robustly make decisions when operating in uncertain and dynamic environments. While Reinforcement Learning (RL) can be used to compute optimal policies with little prior knowledge about the environment, it suffers from slow convergence. An alternative approach is Model Predictive Control (MPC), which optimizes policies quickly, but also requires accurate models of the system dynamics and environment. In this paper we propose a new approach, adaptive probabilistic trajectory optimization, that combines the benefits of RL and MPC. Our method uses scalable approximate inference to learn and updates probabilistic models in an online incremental fashion while also computing optimal control policies via successive local approximations. We present two variations of our algorithm based on the Sparse Spectrum Gaussian Process (SSGP) model, and we test our algorithm on three learning tasks, demonstrating the effectiveness and efficiency of our approach.