 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Conditional Distributions via Dual Embeddings
Paper and Code
Dec 31, 2016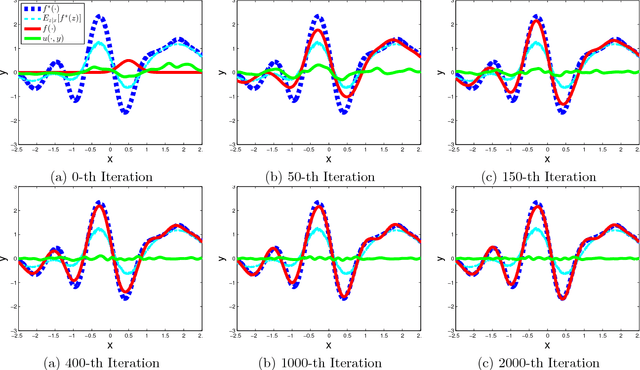
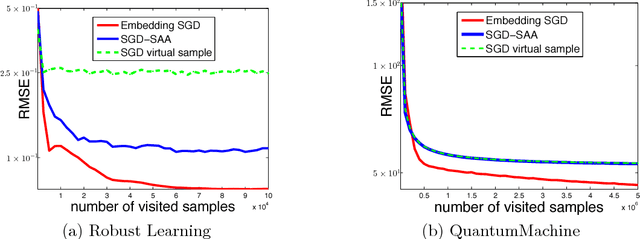
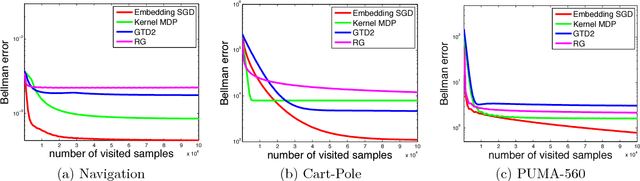
Many machine learning tasks, such as learning with invariance and policy evaluation in reinforcement learning, can be characterized as problems of learning from conditional distributions. In such problems, each sample $x$ itself is associated with a conditional distribution $p(z|x)$ represented by samples $\{z_i\}_{i=1}^M$, and the goal is to learn a function $f$ that links these conditional distributions to target values $y$. These learning problems become very challenging when we only have limited samples or in the extreme case only one sample from each conditional distribution. Commonly used approaches either assume that $z$ is independent of $x$, or require an overwhelmingly large samples from each conditional distribution. To address these challenges, we propose a novel approach which employs a new min-max reformulation of the learning from conditional distribution problem. With such new reformulation, we only need to deal with the joint distribution $p(z,x)$. We also design an efficient learning algorithm, Embedding-SGD, and establish theoretical sample complexity for such problems. Finally, our numerical experiments on both synthetic and real-world datasets show that the proposed approach can significantly improve over the existing algorithms.