 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dementia from Speech and Transcripts using Transformers
Paper and Code
Oct 27, 2021

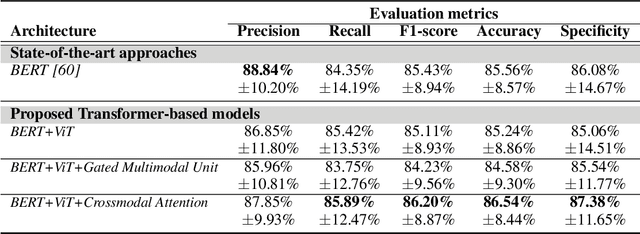
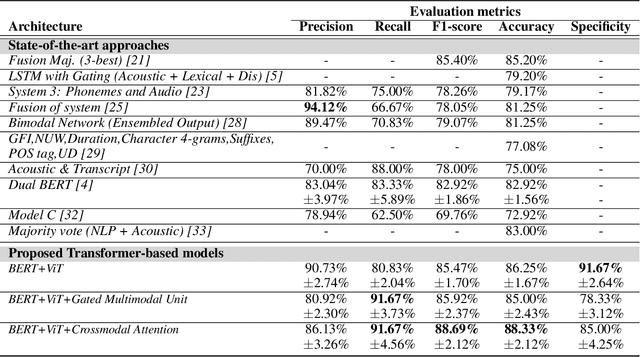
Alzheimer's disease (AD) constitutes a neurodegenerative disease with serious consequences to peoples' everyday lives, if it is not diagnosed early since there is no available cure. Because of the cost of examinations for diagnosing dementia, i.e., Magnetic Resonance Imaging (MRI), electroencephalogram (EEG) signals etc., current work has been focused on diagnosing dementia from spontaneous speech. However, little work has been done regarding the conversion of speech data to Log-Mel spectrograms and Mel-frequency cepstral coefficients (MFCCs) and the usage of pretrained models. Concurrently, little work has been done in terms of both the usage of transformer networks and the way the two modalities, i.e., speech and transcripts, are combined in a single neural network. To address these limitations, first we employ several pretrained models, with Vision Transformer (ViT) achieving the highest evaluation results. Secondly, we propose multimodal models. More specifically, our introduced models include Gated Multimodal Unit in order to control the influence of each modality towards the final classification and crossmodal attention so as to capture in an effective way the relationships between the two modalities. Extensive experiments conducted on the ADReSS Challenge dataset demonstrate the effectiveness of the proposed models and their superiority over state-of-the-art approaches.