 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Detection of Social Spambots in Twitter using Transformers
Paper and Code
Aug 28, 2023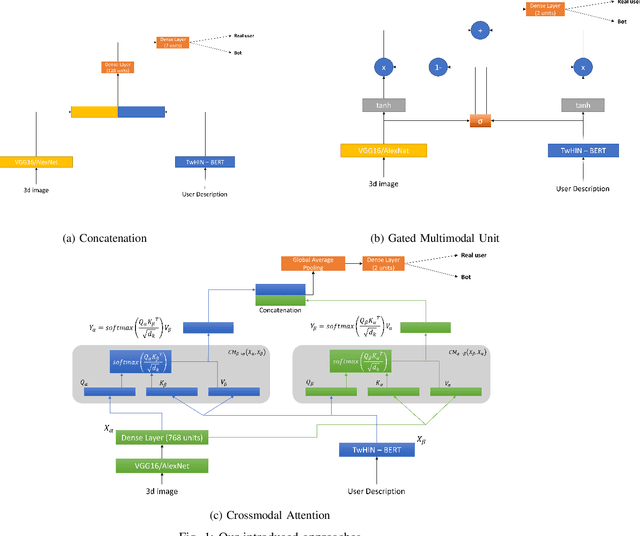
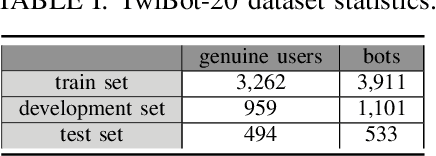
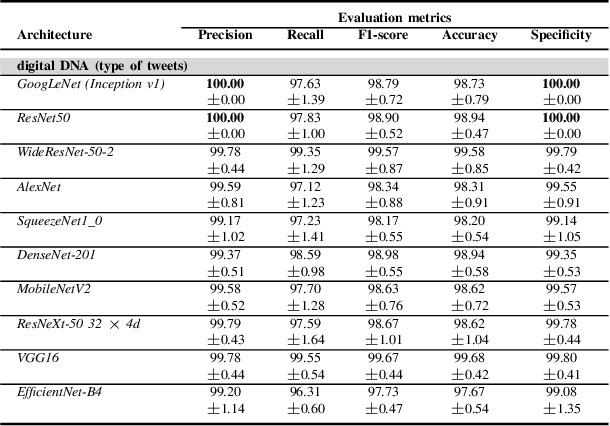
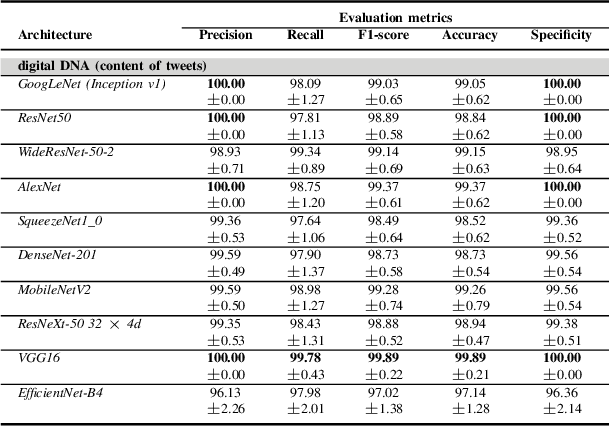
Although not all bots are malicious, the vast majority of them are responsible for spreading misinformation and manipulating the public opinion about several issues, i.e., elections and many more. Therefore, the early detection of social spambots is crucial. Although there have been proposed methods for detecting bots in social media, there are still substantial limitations. For instance, existing research initiatives still extract a large number of features and train traditional machine learning algorithms or use GloVe embeddings and train LSTMs. However, feature extraction is a tedious procedure demanding domain expertise. Also, language models based on transformers have been proved to be better than LSTMs. Other approaches create large graphs and train graph neural networks requiring in this way many hours for training and access to computational resources. To tackle these limitations, this is the first study employing only the user description field and images of three channels denoting the type and content of tweets posted by the users. Firstly, we create digital DNA sequences, transform them to 3d images, and apply pretrained models of the vision domain, including EfficientNet, AlexNet, VGG16, etc. Next, we propose a multimodal approach, where we use TwHIN-BERT for getting the textual representation of the user description field and employ VGG16 for acquiring the visual representation for the image modality. We propose three different fusion methods, namely concatenation, gated multimodal unit, and crossmodal attention, for fusing the different modalities and compare their performances. Extensive experiments conducted on the Cresci '17 dataset demonstrate valuable advantages of our introduced approaches over state-of-the-art ones reaching Accuracy up to 99.98%.