 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvKGYarn: Spinning Configurable and Scalable Conversational Knowledge Graph QA datasets with Large Language Models
Aug 12, 2024



The rapid advancement of Large Language Models (LLMs) and conversational assistants necessitates dynamic, scalable, and configurable conversational datasets for training and evaluation. These datasets must accommodate diverse user interaction modes, including text and voice, each presenting unique modeling challenges. Knowledge Graphs (KGs), with their structured and evolving nature, offer an ideal foundation for current and precise knowledge. Although human-curated KG-based conversational datasets exist, they struggle to keep pace with the rapidly changing user information needs. We present ConvKGYarn, a scalable method for generating up-to-date and configurable conversational KGQA datasets. Qualitative psychometric analyses confirm our method can generate high-quality datasets rivaling a popular conversational KGQA dataset while offering it at scale and covering a wide range of human-interaction configurations. We showcase its utility by testing LLMs on diverse conversations - exploring model behavior on conversational KGQA sets with different configurations grounded in the same KG fact set. Our results highlight the ability of ConvKGYarn to improve KGQA foundations and evaluate parametric knowledge of LLMs, thus offering a robust solution to the constantly evolving landscape of conversational assistants.
Time Sensitive Knowledge Editing through Efficient Finetuning
Jun 06, 2024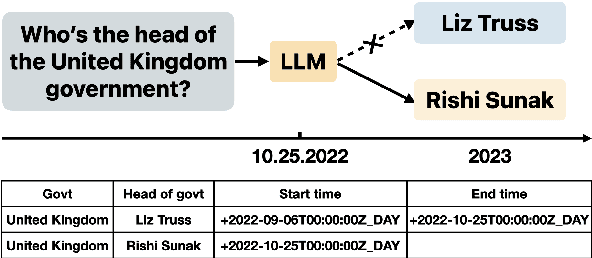

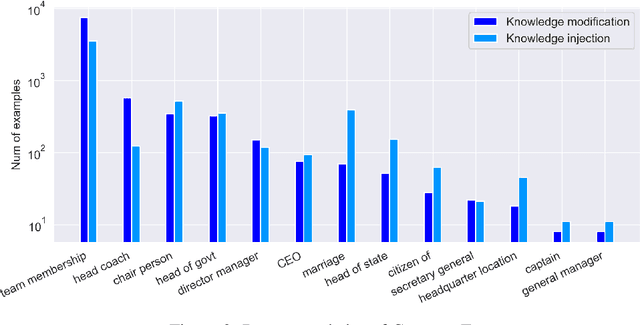
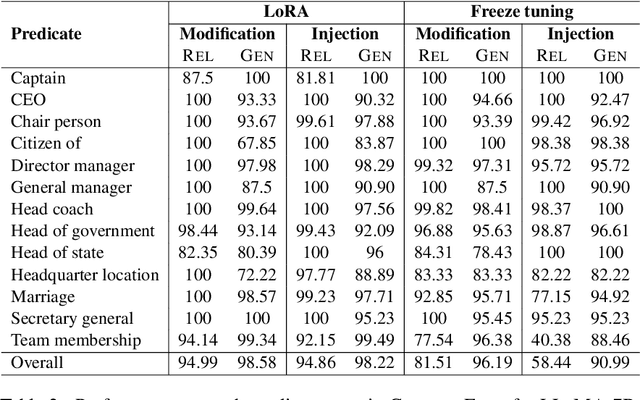
Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
Spotlight the Negatives: A Generalized Discriminative Latent Model
Jul 08, 2015


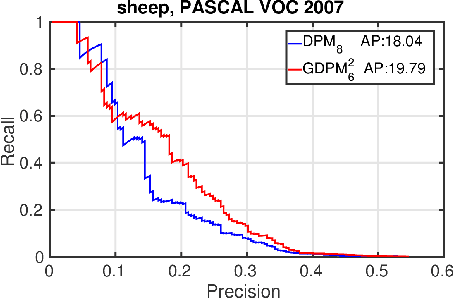
Discriminative latent variable models (LVM) are frequently applied to various visual recognition tasks. In these systems the latent (hidden) variables provide a formalism for modeling structured variation of visual features. Conventionally, latent variables are de- fined on the variation of the foreground (positive) class. In this work we augment LVMs to include negative latent variables corresponding to the background class. We formalize the scoring function of such a generalized LVM (GLVM). Then we discuss a framework for learning a model based on the GLVM scoring function. We theoretically showcase how some of the current visual recognition methods can benefit from this generalization. Finally, we experiment on a generalized form of Deformable Part Models with negative latent variables and show significant improvements on two different detection tasks.