 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Evaluation Metrics -- The Mirage of Hallucination Detection
Apr 25, 2025Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
Time Sensitive Knowledge Editing through Efficient Finetuning
Jun 06, 2024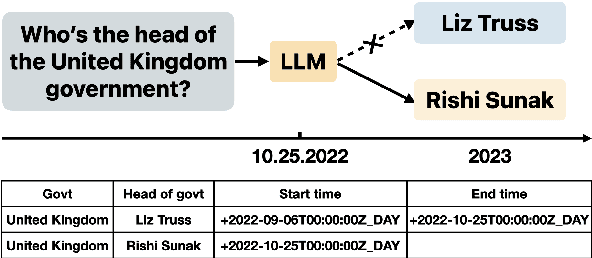

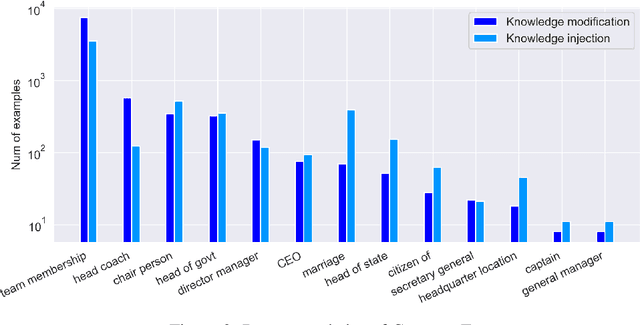
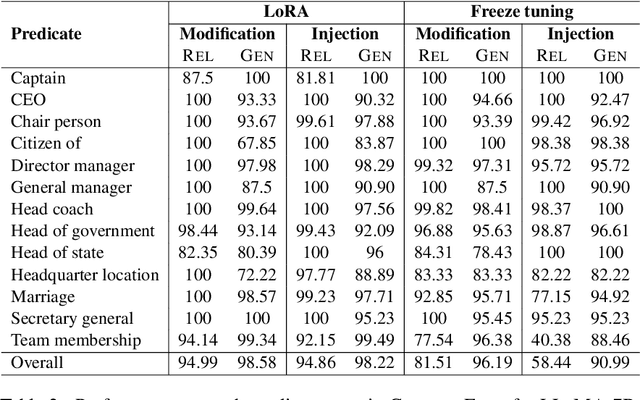
Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
Knowledge Graph Embedding: An Overview
Sep 21, 2023



Many mathematical models have been leveraged to design embeddings for representing Knowledge Graph (KG) entities and relations for link prediction and many downstream tasks. These mathematically-inspired models are not only highly scalable for inference in large KGs, but also have many explainable advantages in modeling different relation patterns that can be validated through both formal proofs and empirical results. In this paper, we make a comprehensive overview of the current state of research in KG completion. In particular, we focus on two main branches of KG embedding (KGE) design: 1) distance-based methods and 2) semantic matching-based methods. We discover the connections between recently proposed models and present an underlying trend that might help researchers invent novel and more effective models. Next, we delve into CompoundE and CompoundE3D, which draw inspiration from 2D and 3D affine operations, respectively. They encompass a broad spectrum of techniques including distance-based and semantic-based methods. We will also discuss an emerging approach for KG completion which leverages pre-trained language models (PLMs) and textual descriptions of entities and relations and offer insights into the integration of KGE embedding methods with PLMs for KG completion.
AsyncET: Asynchronous Learning for Knowledge Graph Entity Typing with Auxiliary Relations
Aug 30, 2023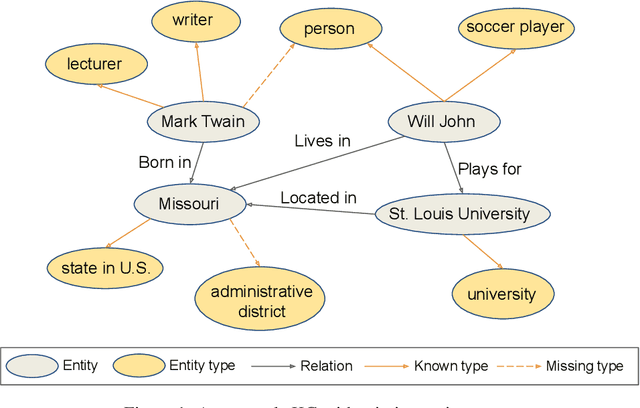



Knowledge graph entity typing (KGET) is a task to predict the missing entity types in knowledge graphs (KG). Previously, KG embedding (KGE) methods tried to solve the KGET task by introducing an auxiliary relation, 'hasType', to model the relationship between entities and their types. However, a single auxiliary relation has limited expressiveness for diverse entity-type patterns. We improve the expressiveness of KGE methods by introducing multiple auxiliary relations in this work. Similar entity types are grouped to reduce the number of auxiliary relations and improve their capability to model entity-type patterns with different granularities. With the presence of multiple auxiliary relations, we propose a method adopting an Asynchronous learning scheme for Entity Typing, named AsyncET, which updates the entity and type embeddings alternatively to keep the learned entity embedding up-to-date and informative for entity type prediction. Experiments are conducted on two commonly used KGET datasets to show that the performance of KGE methods on the KGET task can be substantially improved by the proposed multiple auxiliary relations and asynchronous embedding learning. Furthermore, our method has a significant advantage over state-of-the-art methods in model sizes and time complexity.
Knowledge Graph Embedding with 3D Compound Geometric Transformations
Apr 01, 2023The cascade of 2D geometric transformations were exploited to model relations between entities in a knowledge graph (KG), leading to an effective KG embedding (KGE) model, CompoundE. Furthermore, the rotation in the 3D space was proposed as a new KGE model, Rotate3D, by leveraging its non-commutative property. Inspired by CompoundE and Rotate3D, we leverage 3D compound geometric transformations, including translation, rotation, scaling, reflection, and shear and propose a family of KGE models, named CompoundE3D, in this work. CompoundE3D allows multiple design variants to match rich underlying characteristics of a KG. Since each variant has its own advantages on a subset of relations, an ensemble of multiple variants can yield superior performance. The effectiveness and flexibility of CompoundE3D are experimentally verified on four popular link prediction datasets.
GreenKGC: A Lightweight Knowledge Graph Completion Method
Aug 19, 2022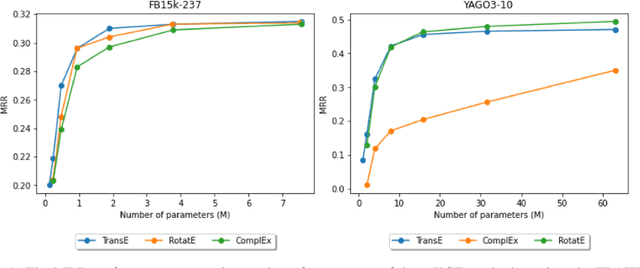



Knowledge graph completion (KGC) aims to discover missing relationships between entities in knowledge graphs (KGs). Most prior KGC work focuses on learning representations for entities and relations. Yet, a higher-dimensional embedding space is usually required for a better reasoning capability, which leads to a larger model size and hinders applicability to real-world problems (e.g., large-scale KGs or mobile/edge computing). A lightweight modularized KGC solution, called GreenKGC, is proposed in this work to address this issue. GreenKGC consists of three modules: 1) representation learning, 2) feature pruning, and 3) decision learning. In Module 1, we leverage existing KG embedding models to learn high-dimensional representations for entities and relations. In Module 2, the KG is partitioned into several relation groups followed by a feature pruning process to find the most discriminant features for each relation group. Finally, a classifier is assigned to each relation group to cope with low-dimensional triple features for KGC tasks in Module 3. We evaluate the performance of GreenKGC on four widely used link prediction datasets and observe that GreenKGC can achieve comparable or even better performance against original high-dimensional embeddings with a much smaller model size. Furthermore, we experiment on two triple classification datasets to demonstrate that the same methodology can generalize to more tasks.
CompoundE: Knowledge Graph Embedding with Translation, Rotation and Scaling Compound Operations
Jul 12, 2022



Translation, rotation, and scaling are three commonly used geometric manipulation operations in image processing. Besides, some of them are successfully used in developing effective knowledge graph embedding (KGE) models such as TransE and RotatE. Inspired by the synergy, we propose a new KGE model by leveraging all three operations in this work. Since translation, rotation, and scaling operations are cascaded to form a compound one, the new model is named CompoundE. By casting CompoundE in the framework of group theory, we show that quite a few scoring-function-based KGE models are special cases of CompoundE. CompoundE extends the simple distance-based relation to relation-dependent compound operations on head and/or tail entities. To demonstrate the effectiveness of CompoundE, we conduct experiments on three popular KG completion datasets. Experimental results show that CompoundE consistently achieves the state of-the-art performance.
Accelerated Design and Deployment of Low-Carbon Concrete for Data Centers
Apr 11, 2022
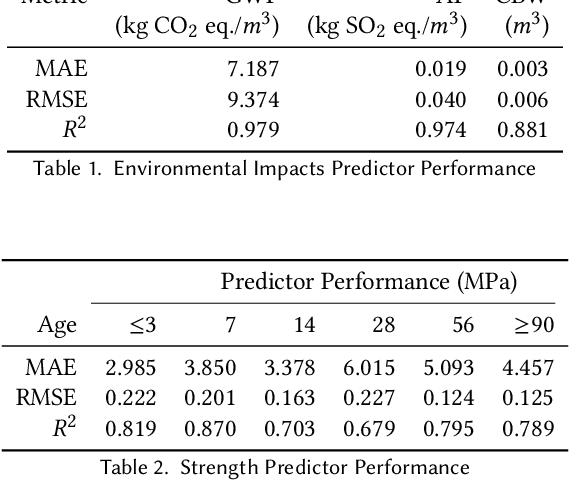

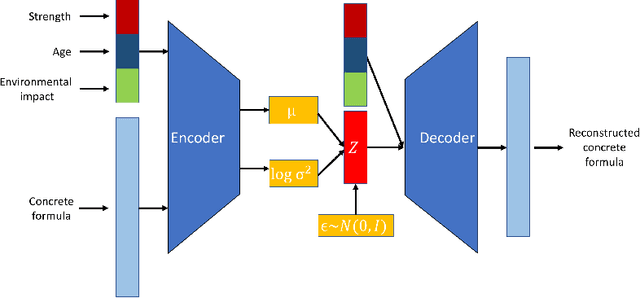
Concrete is the most widely used engineered material in the world with more than 10 billion tons produced annually. Unfortunately, with that scale comes a significant burden in terms of energy, water, and release of greenhouse gases and other pollutants; indeed 8% of worldwide carbon emissions are attributed to the production of cement, a key ingredient in concrete. As such, there is interest in creating concrete formulas that minimize this environmental burden, while satisfying engineering performance requirements including compressive strength. Specifically for computing, concrete is a major ingredient in the construction of data centers. In this work, we use conditional variational autoencoders (CVAEs), a type of semi-supervised generative artificial intelligence (AI) model, to discover concrete formulas with desired properties. Our model is trained just using a small open dataset from the UCI Machine Learning Repository joined with environmental impact data from standard lifecycle analysis. Computational predictions demonstrate CVAEs can design concrete formulas with much lower carbon requirements than existing formulations while meeting design requirements. Next we report laboratory-based compressive strength experiments for five AI-generated formulations, which demonstrate that the formulations exceed design requirements. The resulting formulations were then used by Ozinga Ready Mix -- a concrete supplier -- to generate field-ready concrete formulations, based on local conditions and their expertise in concrete design. Finally, we report on how these formulations were used in the construction of buildings and structures in a Meta data center in DeKalb, IL, USA. Results from field experiments as part of this real-world deployment corroborate the efficacy of AI-generated low-carbon concrete mixes.
CORE: A Knowledge Graph Entity Type Prediction Method via Complex Space Regression and Embedding
Dec 19, 2021



Entity type prediction is an important problem in knowledge graph (KG) research. A new KG entity type prediction method, named CORE (COmplex space Regression and Embedding), is proposed in this work. The proposed CORE method leverages the expressive power of two complex space embedding models; namely, RotatE and ComplEx models. It embeds entities and types in two different complex spaces using either RotatE or ComplEx. Then, we derive a complex regression model to link these two spaces. Finally, a mechanism to optimize embedding and regression parameters jointly is introduced. Experiments show that CORE outperforms benchmarking methods on representative KG entity type inference datasets. Strengths and weaknesses of various entity type prediction methods are analyzed.
KGBoost: A Classification-based Knowledge Base Completion Method with Negative Sampling
Dec 17, 2021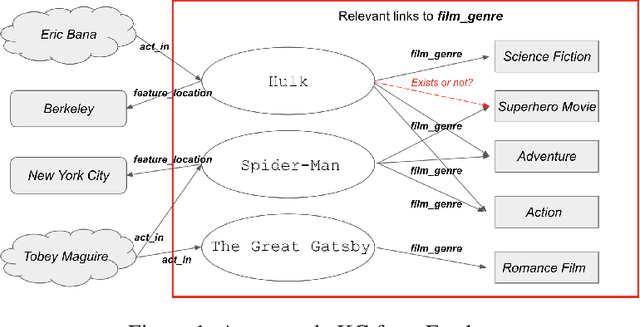
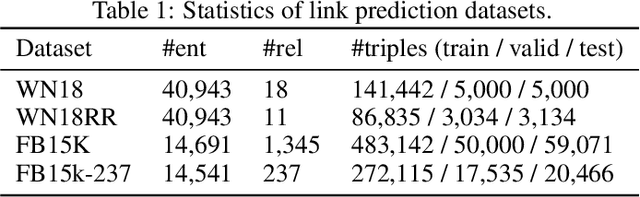

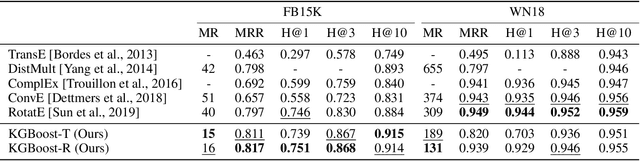
Knowledge base completion is formulated as a binary classification problem in this work, where an XGBoost binary classifier is trained for each relation using relevant links in knowledge graphs (KGs). The new method, named KGBoost, adopts a modularized design and attempts to find hard negative samples so as to train a powerful classifier for missing link prediction. We conduct experiments on multiple benchmark datasets, and demonstrate that KGBoost outperforms state-of-the-art methods across most datasets. Furthermore, as compared with models trained by end-to-end optimization, KGBoost works well under the low-dimensional setting so as to allow a smaller model size.