 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Human-Object-Interaction (EHOI) Detection via Interaction Label Coding and Conditional Decision
Aug 13, 2024Human-Object Interaction (HOI) detection is a fundamental task in image understanding. While deep-learning-based HOI methods provide high performance in terms of mean Average Precision (mAP), they are computationally expensive and opaque in training and inference processes. An Efficient HOI (EHOI) detector is proposed in this work to strike a good balance between detection performance, inference complexity, and mathematical transparency. EHOI is a two-stage method. In the first stage, it leverages a frozen object detector to localize the objects and extract various features as intermediate outputs. In the second stage, the first-stage outputs predict the interaction type using the XGBoost classifier. Our contributions include the application of error correction codes (ECCs) to encode rare interaction cases, which reduces the model size and the complexity of the XGBoost classifier in the second stage. Additionally, we provide a mathematical formulation of the relabeling and decision-making process. Apart from the architecture, we present qualitative results to explain the functionalities of the feedforward modules. Experimental results demonstrate the advantages of ECC-coded interaction labels and the excellent balance of detection performance and complexity of the proposed EHOI method.
Word Embedding Dimension Reduction via Weakly-Supervised Feature Selection
Jul 17, 2024



As a fundamental task in natural language processing, word embedding converts each word into a representation in a vector space. A challenge with word embedding is that as the vocabulary grows, the vector space's dimension increases and it can lead to a vast model size. Storing and processing word vectors are resource-demanding, especially for mobile edge-devices applications. This paper explores word embedding dimension reduction. To balance computational costs and performance, we propose an efficient and effective weakly-supervised feature selection method, named WordFS. It has two variants, each utilizing novel criteria for feature selection. Experiments conducted on various tasks (e.g., word and sentence similarity and binary and multi-class classification) indicate that the proposed WordFS model outperforms other dimension reduction methods at lower computational costs.
GSBIQA: Green Saliency-guided Blind Image Quality Assessment Method
Jul 08, 2024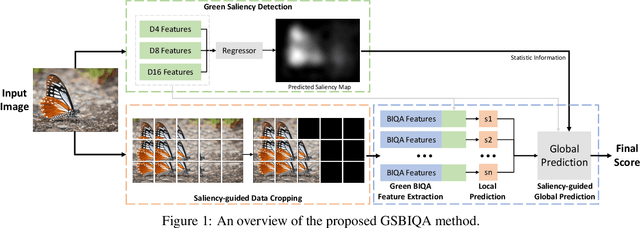
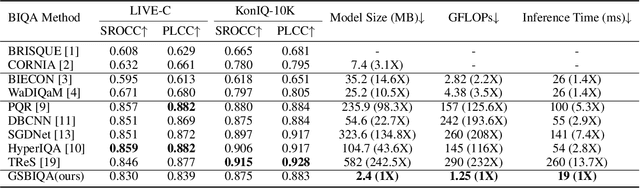
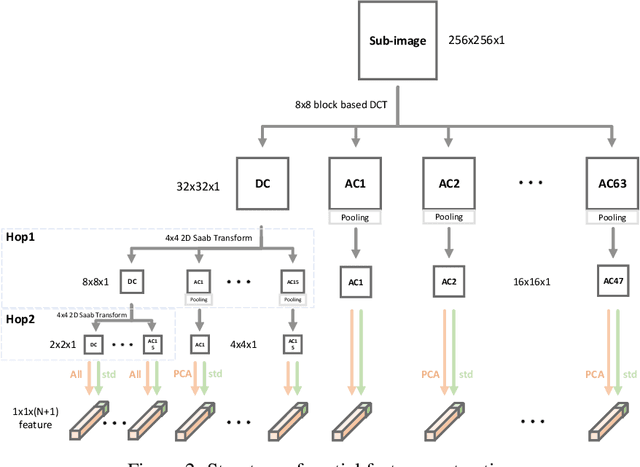

Blind Image Quality Assessment (BIQA) is an essential task that estimates the perceptual quality of images without reference. While many BIQA methods employ deep neural networks (DNNs) and incorporate saliency detectors to enhance performance, their large model sizes limit deployment on resource-constrained devices. To address this challenge, we introduce a novel and non-deep-learning BIQA method with a lightweight saliency detection module, called Green Saliency-guided Blind Image Quality Assessment (GSBIQA). It is characterized by its minimal model size, reduced computational demands, and robust performance. Experimental results show that the performance of GSBIQA is comparable with state-of-the-art DL-based methods with significantly lower resource requirements.
GreenSaliency: A Lightweight and Efficient Image Saliency Detection Method
Mar 30, 2024Image saliency detection is crucial in understanding human gaze patterns from visual stimuli. The escalating demand for research in image saliency detection is driven by the growing necessity to incorporate such techniques into various computer vision tasks and to understand human visual systems. Many existing image saliency detection methods rely on deep neural networks (DNNs) to achieve good performance. However, the high computational complexity associated with these approaches impedes their integration with other modules or deployment on resource-constrained platforms, such as mobile devices. To address this need, we propose a novel image saliency detection method named GreenSaliency, which has a small model size, minimal carbon footprint, and low computational complexity. GreenSaliency can be a competitive alternative to the existing deep-learning-based (DL-based) image saliency detection methods with limited computation resources. GreenSaliency comprises two primary steps: 1) multi-layer hybrid feature extraction and 2) multi-path saliency prediction. Experimental results demonstrate that GreenSaliency achieves comparable performance to the state-of-the-art DL-based methods while possessing a considerably smaller model size and significantly reduced computational complexity.
Knowledge Graph Embedding: An Overview
Sep 21, 2023



Many mathematical models have been leveraged to design embeddings for representing Knowledge Graph (KG) entities and relations for link prediction and many downstream tasks. These mathematically-inspired models are not only highly scalable for inference in large KGs, but also have many explainable advantages in modeling different relation patterns that can be validated through both formal proofs and empirical results. In this paper, we make a comprehensive overview of the current state of research in KG completion. In particular, we focus on two main branches of KG embedding (KGE) design: 1) distance-based methods and 2) semantic matching-based methods. We discover the connections between recently proposed models and present an underlying trend that might help researchers invent novel and more effective models. Next, we delve into CompoundE and CompoundE3D, which draw inspiration from 2D and 3D affine operations, respectively. They encompass a broad spectrum of techniques including distance-based and semantic-based methods. We will also discuss an emerging approach for KG completion which leverages pre-trained language models (PLMs) and textual descriptions of entities and relations and offer insights into the integration of KGE embedding methods with PLMs for KG completion.
Bias and Fairness in Chatbots: An Overview
Sep 16, 2023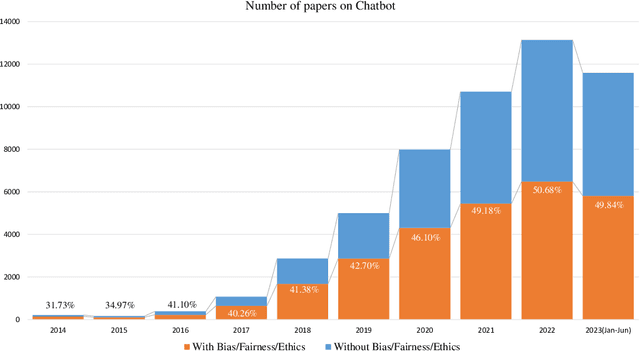
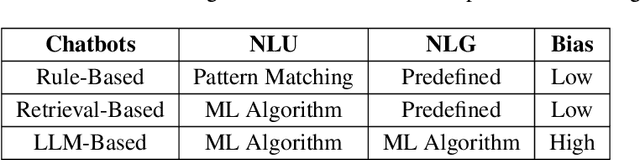
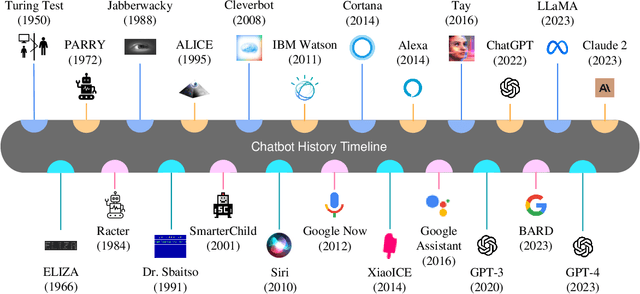
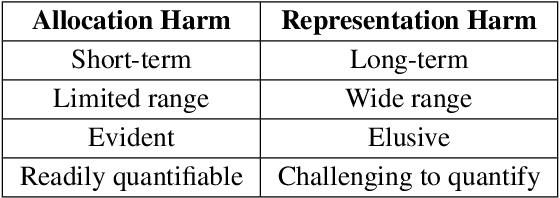
Chatbots have been studied for more than half a century. With the rapid development of natural language processing (NLP) technologies in recent years, chatbots using large language models (LLMs) have received much attention nowadays. Compared with traditional ones, modern chatbots are more powerful and have been used in real-world applications. There are however, bias and fairness concerns in modern chatbot design. Due to the huge amounts of training data, extremely large model sizes, and lack of interpretability, bias mitigation and fairness preservation of modern chatbots are challenging. Thus, a comprehensive overview on bias and fairness in chatbot systems is given in this paper. The history of chatbots and their categories are first reviewed. Then, bias sources and potential harms in applications are analyzed. Considerations in designing fair and unbiased chatbot systems are examined. Finally, future research directions are discussed.
AsyncET: Asynchronous Learning for Knowledge Graph Entity Typing with Auxiliary Relations
Aug 30, 2023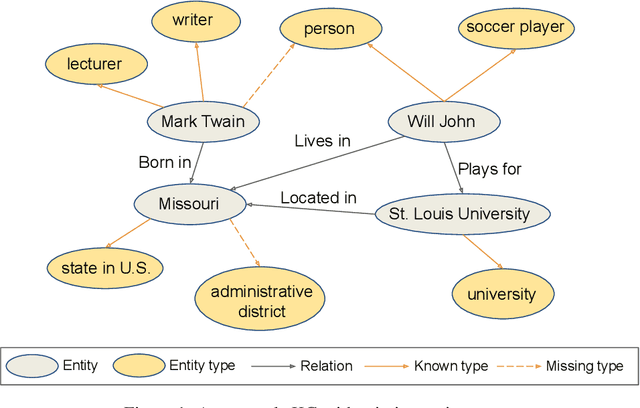



Knowledge graph entity typing (KGET) is a task to predict the missing entity types in knowledge graphs (KG). Previously, KG embedding (KGE) methods tried to solve the KGET task by introducing an auxiliary relation, 'hasType', to model the relationship between entities and their types. However, a single auxiliary relation has limited expressiveness for diverse entity-type patterns. We improve the expressiveness of KGE methods by introducing multiple auxiliary relations in this work. Similar entity types are grouped to reduce the number of auxiliary relations and improve their capability to model entity-type patterns with different granularities. With the presence of multiple auxiliary relations, we propose a method adopting an Asynchronous learning scheme for Entity Typing, named AsyncET, which updates the entity and type embeddings alternatively to keep the learned entity embedding up-to-date and informative for entity type prediction. Experiments are conducted on two commonly used KGET datasets to show that the performance of KGE methods on the KGET task can be substantially improved by the proposed multiple auxiliary relations and asynchronous embedding learning. Furthermore, our method has a significant advantage over state-of-the-art methods in model sizes and time complexity.
Blind Video Quality Assessment at the Edge
Jun 17, 2023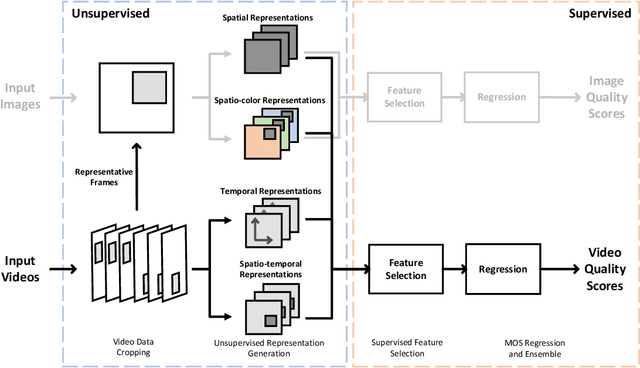
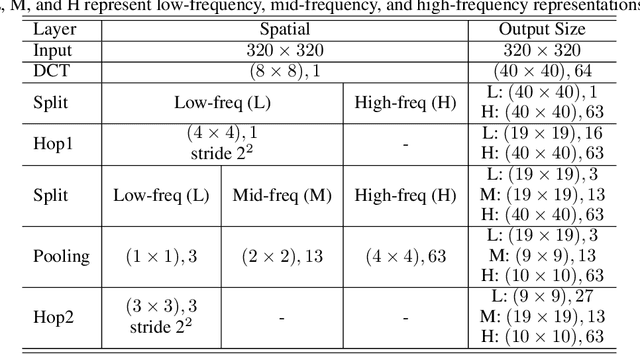
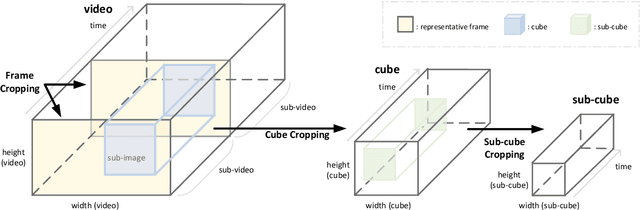
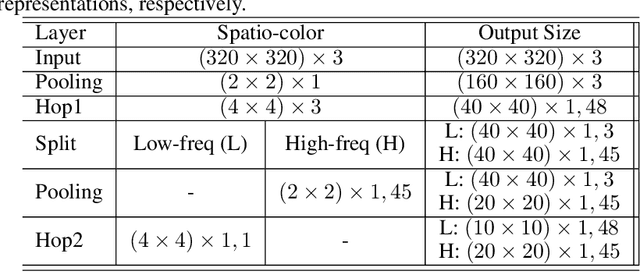
Owing to the proliferation of user-generated videos on the Internet, blind video quality assessment (BVQA) at the edge attracts growing attention. The usage of deep-learning-based methods is restricted by their large model sizes and high computational complexity. In light of this, a novel lightweight BVQA method called GreenBVQA is proposed in this work. GreenBVQA features a small model size, low computational complexity, and high performance. Its processing pipeline includes: video data cropping, unsupervised representation generation, supervised feature selection, and mean-opinion-score (MOS) regression and ensembles. We conduct experimental evaluations on three BVQA datasets and show that GreenBVQA can offer state-of-the-art performance in PLCC and SROCC metrics while demanding significantly smaller model sizes and lower computational complexity. Thus, GreenBVQA is well-suited for edge devices.
Knowledge Graph Embedding with 3D Compound Geometric Transformations
Apr 01, 2023The cascade of 2D geometric transformations were exploited to model relations between entities in a knowledge graph (KG), leading to an effective KG embedding (KGE) model, CompoundE. Furthermore, the rotation in the 3D space was proposed as a new KGE model, Rotate3D, by leveraging its non-commutative property. Inspired by CompoundE and Rotate3D, we leverage 3D compound geometric transformations, including translation, rotation, scaling, reflection, and shear and propose a family of KGE models, named CompoundE3D, in this work. CompoundE3D allows multiple design variants to match rich underlying characteristics of a KG. Since each variant has its own advantages on a subset of relations, an ensemble of multiple variants can yield superior performance. The effectiveness and flexibility of CompoundE3D are experimentally verified on four popular link prediction datasets.
Lightweight High-Performance Blind Image Quality Assessment
Mar 23, 2023

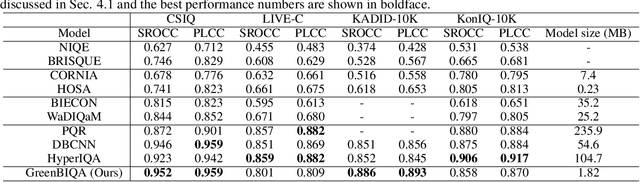

Blind image quality assessment (BIQA) is a task that predicts the perceptual quality of an image without its reference. Research on BIQA attracts growing attention due to the increasing amount of user-generated images and emerging mobile applications where reference images are unavailable. The problem is challenging due to the wide range of content and mixed distortion types. Many existing BIQA methods use deep neural networks (DNNs) to achieve high performance. However, their large model sizes hinder their applicability to edge or mobile devices. To meet the need, a novel BIQA method with a small model, low computational complexity, and high performance is proposed and named "GreenBIQA" in this work. GreenBIQA includes five steps: 1) image cropping, 2) unsupervised representation generation, 3) supervised feature selection, 4) distortion-specific prediction, and 5) regression and decision ensemble. Experimental results show that the performance of GreenBIQA is comparable with that of state-of-the-art deep-learning (DL) solutions while demanding a much smaller model size and significantly lower computational complexity.