 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSBIQA: Green Saliency-guided Blind Image Quality Assessment Method
Jul 08, 2024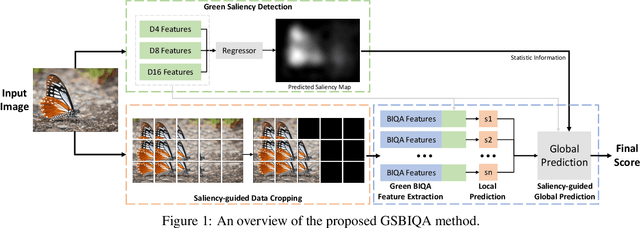
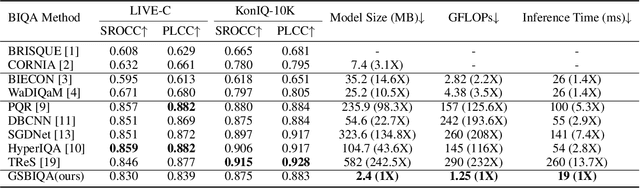

Blind Image Quality Assessment (BIQA) is an essential task that estimates the perceptual quality of images without reference. While many BIQA methods employ deep neural networks (DNNs) and incorporate saliency detectors to enhance performance, their large model sizes limit deployment on resource-constrained devices. To address this challenge, we introduce a novel and non-deep-learning BIQA method with a lightweight saliency detection module, called Green Saliency-guided Blind Image Quality Assessment (GSBIQA). It is characterized by its minimal model size, reduced computational demands, and robust performance. Experimental results show that the performance of GSBIQA is comparable with state-of-the-art DL-based methods with significantly lower resource requirements.
GreenSaliency: A Lightweight and Efficient Image Saliency Detection Method
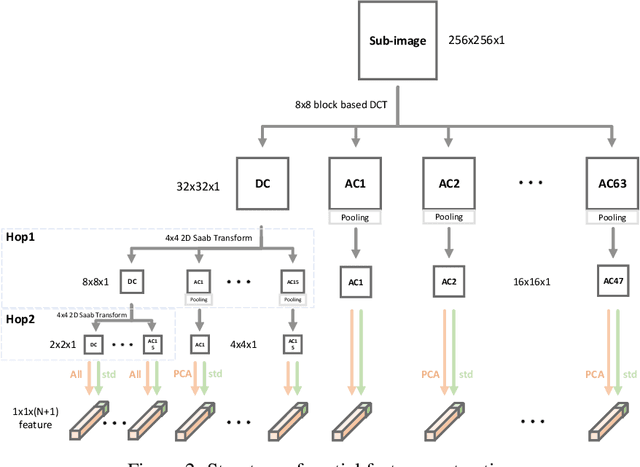
Mar 30, 2024Image saliency detection is crucial in understanding human gaze patterns from visual stimuli. The escalating demand for research in image saliency detection is driven by the growing necessity to incorporate such techniques into various computer vision tasks and to understand human visual systems. Many existing image saliency detection methods rely on deep neural networks (DNNs) to achieve good performance. However, the high computational complexity associated with these approaches impedes their integration with other modules or deployment on resource-constrained platforms, such as mobile devices. To address this need, we propose a novel image saliency detection method named GreenSaliency, which has a small model size, minimal carbon footprint, and low computational complexity. GreenSaliency can be a competitive alternative to the existing deep-learning-based (DL-based) image saliency detection methods with limited computation resources. GreenSaliency comprises two primary steps: 1) multi-layer hybrid feature extraction and 2) multi-path saliency prediction. Experimental results demonstrate that GreenSaliency achieves comparable performance to the state-of-the-art DL-based methods while possessing a considerably smaller model size and significantly reduced computational complexity.
Blind Video Quality Assessment at the Edge
Jun 17, 2023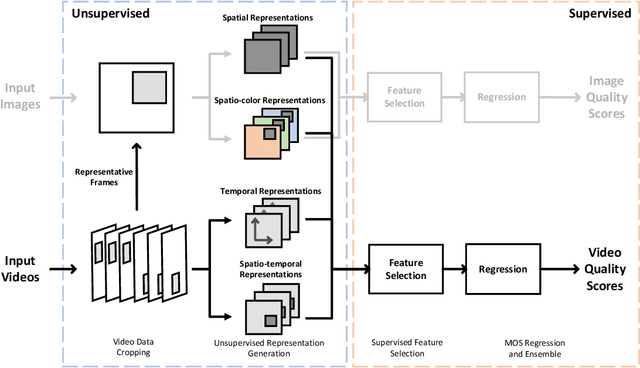
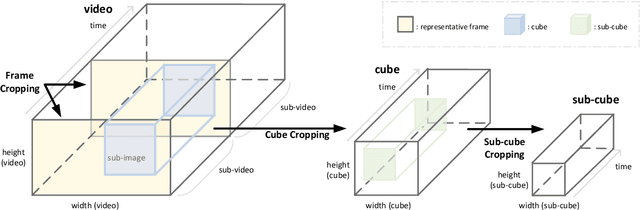
Owing to the proliferation of user-generated videos on the Internet, blind video quality assessment (BVQA) at the edge attracts growing attention. The usage of deep-learning-based methods is restricted by their large model sizes and high computational complexity. In light of this, a novel lightweight BVQA method called GreenBVQA is proposed in this work. GreenBVQA features a small model size, low computational complexity, and high performance. Its processing pipeline includes: video data cropping, unsupervised representation generation, supervised feature selection, and mean-opinion-score (MOS) regression and ensembles. We conduct experimental evaluations on three BVQA datasets and show that GreenBVQA can offer state-of-the-art performance in PLCC and SROCC metrics while demanding significantly smaller model sizes and lower computational complexity. Thus, GreenBVQA is well-suited for edge devices.
Lightweight High-Performance Blind Image Quality Assessment
Mar 23, 2023

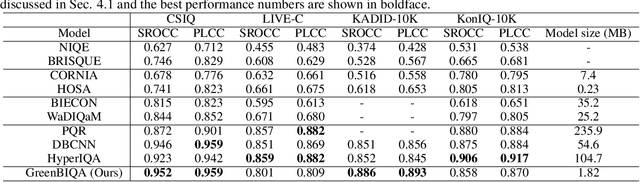

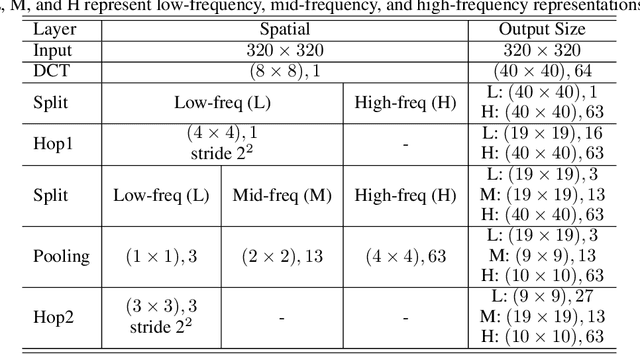
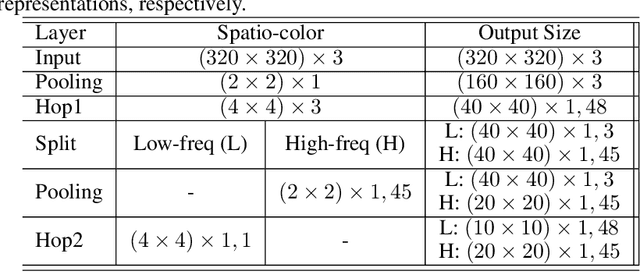
Blind image quality assessment (BIQA) is a task that predicts the perceptual quality of an image without its reference. Research on BIQA attracts growing attention due to the increasing amount of user-generated images and emerging mobile applications where reference images are unavailable. The problem is challenging due to the wide range of content and mixed distortion types. Many existing BIQA methods use deep neural networks (DNNs) to achieve high performance. However, their large model sizes hinder their applicability to edge or mobile devices. To meet the need, a novel BIQA method with a small model, low computational complexity, and high performance is proposed and named "GreenBIQA" in this work. GreenBIQA includes five steps: 1) image cropping, 2) unsupervised representation generation, 3) supervised feature selection, 4) distortion-specific prediction, and 5) regression and decision ensemble. Experimental results show that the performance of GreenBIQA is comparable with that of state-of-the-art deep-learning (DL) solutions while demanding a much smaller model size and significantly lower computational complexity.
Lightweight Image Codec via Multi-Grid Multi-Block-Size Vector Quantization
Sep 25, 2022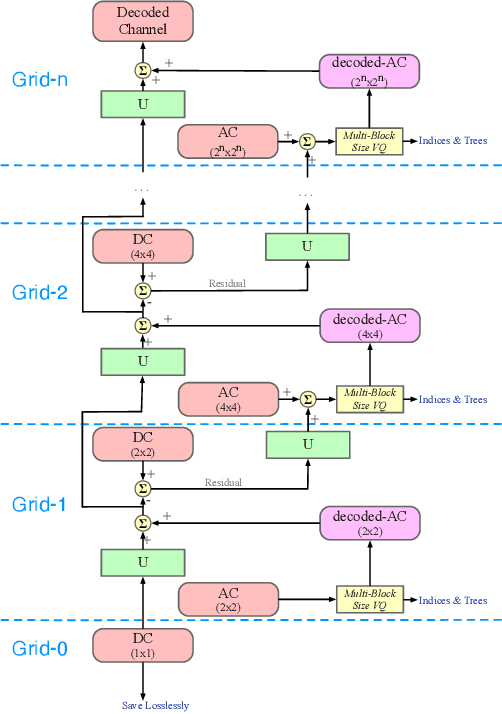
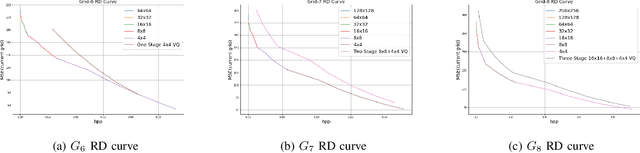


A multi-grid multi-block-size vector quantization (MGBVQ) method is proposed for image coding in this work. The fundamental idea of image coding is to remove correlations among pixels before quantization and entropy coding, e.g., the discrete cosine transform (DCT) and intra predictions, adopted by modern image coding standards. We present a new method to remove pixel correlations. First, by decomposing correlations into long- and short-range correlations, we represent long-range correlations in coarser grids due to their smoothness, thus leading to a multi-grid (MG) coding architecture. Second, we show that short-range correlations can be effectively coded by a suite of vector quantizers (VQs). Along this line, we argue the effectiveness of VQs of very large block sizes and present a convenient way to implement them. It is shown by experimental results that MGBVQ offers excellent rate-distortion (RD) performance, which is comparable with existing image coders, at much lower complexity. Besides, it provides a progressive coded bitstream.
GreenBIQA: A Lightweight Blind Image Quality Assessment Method
Jun 29, 2022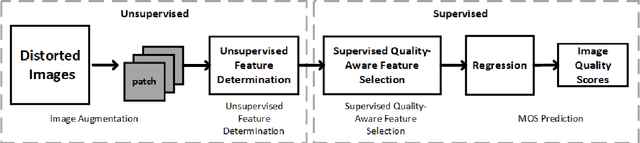
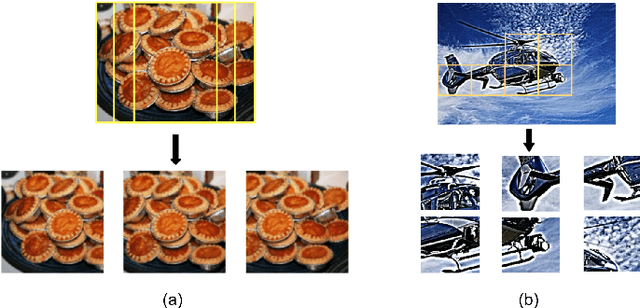
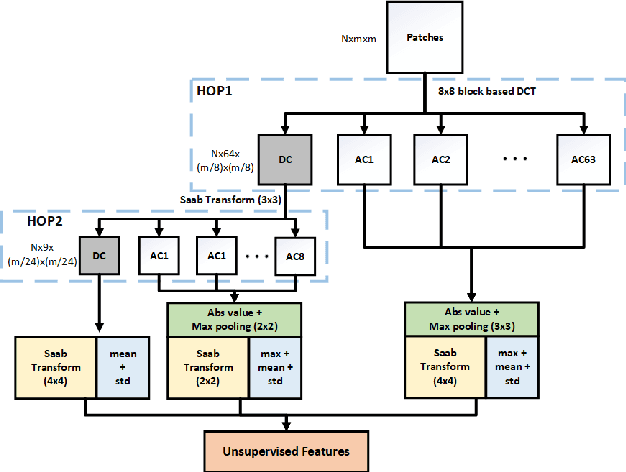
Deep neural networks (DNNs) achieve great success in blind image quality assessment (BIQA) with large pre-trained models in recent years. Their solutions cannot be easily deployed at mobile or edge devices, and a lightweight solution is desired. In this work, we propose a novel BIQA model, called GreenBIQA, that aims at high performance, low computational complexity and a small model size. GreenBIQA adopts an unsupervised feature generation method and a supervised feature selection method to extract quality-aware features. Then, it trains an XGBoost regressor to predict quality scores of test images. We conduct experiments on four popular IQA datasets, which include two synthetic-distortion and two authentic-distortion datasets. Experimental results show that GreenBIQA is competitive in performance against state-of-the-art DNNs with lower complexity and smaller model sizes.
A Machine Learning Approach to Optimal Inverse Discrete Cosine Transform (IDCT) Design
Jan 31, 2021
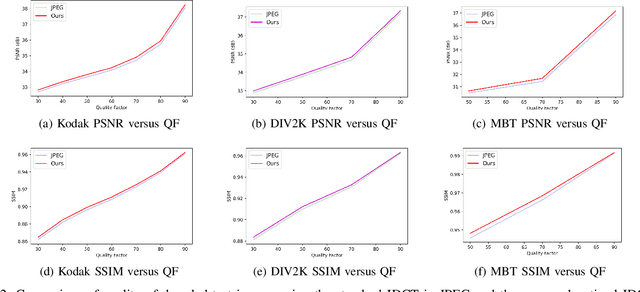


The design of the optimal inverse discrete cosine transform (IDCT) to compensate the quantization error is proposed for effective lossy image compression in this work. The forward and inverse DCTs are designed in pair in current image/video coding standards without taking the quantization effect into account. Yet, the distribution of quantized DCT coefficients deviate from that of original DCT coefficients. This is particularly obvious when the quality factor of JPEG compressed images is small. To address this problem, we first use a set of training images to learn the compound effect of forward DCT, quantization and dequantization in cascade. Then, a new IDCT kernel is learned to reverse the effect of such a pipeline. Experiments are conducted to demonstrate that the advantage of the new method, which has a gain of 0.11-0.30dB over the standard JPEG over a wide range of quality factors.